 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-Ensemble Text Generation: On Attacking the Automatic AI-Generated Text Detection
Feb 17, 2024



The robustness of AI-content detection models against cultivated attacks (e.g., paraphrasing or word switching) remains a significant concern. This study proposes a novel token-ensemble generation strategy to challenge the robustness of current AI-content detection approaches. We explore the ensemble attack strategy by completing the prompt with the next token generated from random candidate LLMs. We find the token-ensemble approach significantly drops the performance of AI-content detection models (The code and test sets will be released). Our findings reveal that token-ensemble generation poses a vital challenge to current detection models and underlines the need for advancing detection technologies to counter sophisticated adversarial strategies.
Improving Real Estate Appraisal with POI Integration and Areal Embedding
Nov 20, 2023



Despite advancements in real estate appraisal methods, this study primarily focuses on two pivotal challenges. Firstly, we explore the often-underestimated impact of Points of Interest (POI) on property values, emphasizing the necessity for a comprehensive, data-driven approach to feature selection. Secondly, we integrate road-network-based Areal Embedding to enhance spatial understanding for real estate appraisal. We first propose a revised method for POI feature extraction, and discuss the impact of each POI for house price appraisal. Then we present the Areal embedding-enabled Masked Multihead Attention-based Spatial Interpolation for House Price Prediction (AMMASI) model, an improvement upon the existing ASI model, which leverages masked multi-head attention on geographic neighbor houses and similar-featured houses. Our model outperforms current baselines and also offers promising avenues for future optimization in real estate appraisal methodologies.
Enhancing Stance Classification with Quantified Moral Foundations
Oct 15, 2023



This study enhances stance detection on social media by incorporating deeper psychological attributes, specifically individuals' moral foundations. These theoretically-derived dimensions aim to provide a comprehensive profile of an individual's moral concerns which, in recent work, has been linked to behaviour in a range of domains, including society, politics, health, and the environment. In this paper, we investigate how moral foundation dimensions can contribute to predicting an individual's stance on a given target. Specifically we incorporate moral foundation features extracted from text, along with message semantic features, to classify stances at both message- and user-levels across a range of targets and models. Our preliminary results suggest that encoding moral foundations can enhance the performance of stance detection tasks and help illuminate the associations between specific moral foundations and online stances on target topics. The results highlight the importance of considering deeper psychological attributes in stance analysis and underscores the role of moral foundations in guiding online social behavior.
Enhancing Spatiotemporal Traffic Prediction through Urban Human Activity Analysis
Aug 20, 2023



Traffic prediction is one of the key elements to ensure the safety and convenience of citizens. Existing traffic prediction models primarily focus on deep learning architectures to capture spatial and temporal correlation. They often overlook the underlying nature of traffic. Specifically, the sensor networks in most traffic datasets do not accurately represent the actual road network exploited by vehicles, failing to provide insights into the traffic patterns in urban activities. To overcome these limitations, we propose an improved traffic prediction method based on graph convolution deep learning algorithms. We leverage human activity frequency data from National Household Travel Survey to enhance the inference capability of a causal relationship between activity and traffic patterns. Despite making minimal modifications to the conventional graph convolutional recurrent networks and graph convolutional transformer architectures, our approach achieves state-of-the-art performance without introducing excessive computational overhead.
Can we trust the evaluation on ChatGPT?
Mar 22, 2023ChatGPT, the first large language model (LLM) with mass adoption, has demonstrated remarkable performance in numerous natural language tasks. Despite its evident usefulness, evaluating ChatGPT's performance in diverse problem domains remains challenging due to the closed nature of the model and its continuous updates via Reinforcement Learning from Human Feedback (RLHF). We highlight the issue of data contamination in ChatGPT evaluations, with a case study of the task of stance detection. We discuss the challenge of preventing data contamination and ensuring fair model evaluation in the age of closed and continuously trained models.
Wearing Masks Implies Refuting Trump?: Towards Target-specific User Stance Prediction across Events in COVID-19 and US Election 2020
Mar 21, 2023



People who share similar opinions towards controversial topics could form an echo chamber and may share similar political views toward other topics as well. The existence of such connections, which we call connected behavior, gives researchers a unique opportunity to predict how one would behave for a future event given their past behaviors. In this work, we propose a framework to conduct connected behavior analysis. Neural stance detection models are trained on Twitter data collected on three seemingly independent topics, i.e., wearing a mask, racial equality, and Trump, to detect people's stance, which we consider as their online behavior in each topic-related event. Our results reveal a strong connection between the stances toward the three topical events and demonstrate the power of past behaviors in predicting one's future behavior.
Is ChatGPT better than Human Annotators? Potential and Limitations of ChatGPT in Explaining Implicit Hate Speech
Feb 11, 2023


Recent studies have alarmed that many online hate speeches are implicit. With its subtle nature, the explainability of the detection of such hateful speech has been a challenging problem. In this work, we examine whether ChatGPT can be used for providing natural language explanations (NLEs) for implicit hateful speech detection. We design our prompt to elicit concise ChatGPT-generated NLEs and conduct user studies to evaluate their qualities by comparison with human-generated NLEs. We discuss the potential and limitations of ChatGPT in the context of implicit hateful speech research.
Chain of Explanation: New Prompting Method to Generate Higher Quality Natural Language Explanation for Implicit Hate Speech
Sep 11, 2022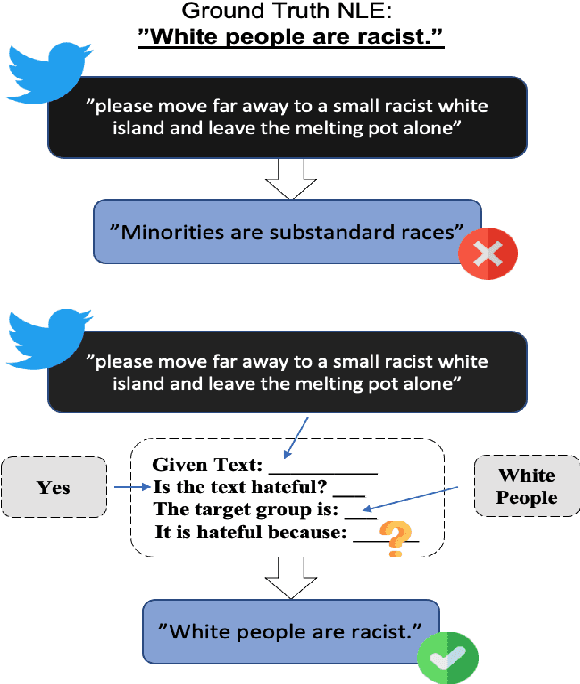

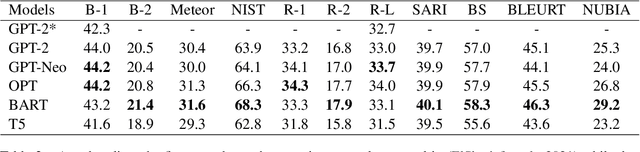

Recent studies have exploited advanced generative language models to generate Natural Language Explanations (NLE) for why a certain text could be hateful. We propose the Chain of Explanation Prompting method, inspired by the chain of thoughts study \cite{wei2022chain}, to generate high-quality NLE for implicit hate speech. We build a benchmark based on the selected mainstream Pre-trained Language Models (PLMs), including GPT-2, GPT-Neo, OPT, T5, and BART, with various evaluation metrics from lexical, semantic, and faithful aspects. To further evaluate the quality of the generated NLE from human perceptions, we hire human annotators to score the informativeness and clarity of the generated NLE. Then, we inspect which automatic evaluation metric could be best correlated with the human-annotated informativeness and clarity metric scores.
Who Is Missing? Characterizing the Participation of Different Demographic Groups in a Korean Nationwide Daily Conversation Corpus
Apr 20, 2022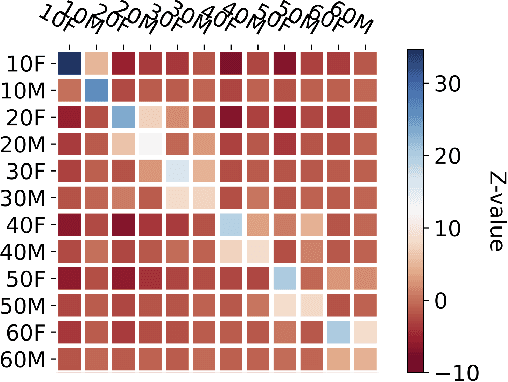
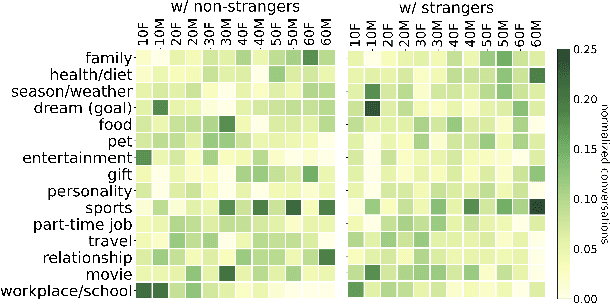
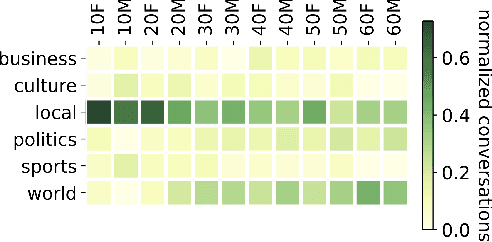
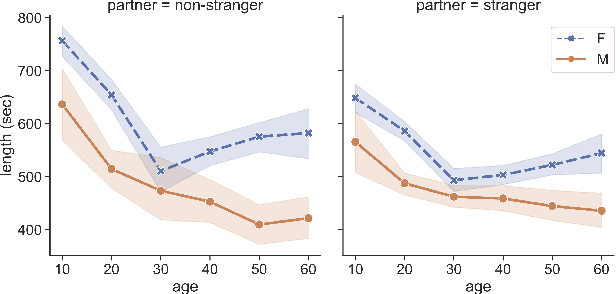
A conversation corpus is essential to build interactive AI applications. However, the demographic information of the participants in such corpora is largely underexplored mainly due to the lack of individual data in many corpora. In this work, we analyze a Korean nationwide daily conversation corpus constructed by the National Institute of Korean Language (NIKL) to characterize the participation of different demographic (age and sex) groups in the corpus.
A Survey on Predicting the Factuality and the Bias of News Media
Mar 16, 2021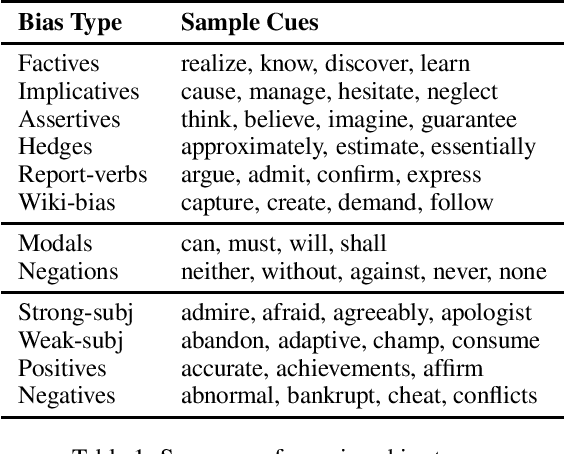
The present level of proliferation of fake, biased, and propagandistic content online has made it impossible to fact-check every single suspicious claim or article, either manually or automatically. Thus, many researchers are shifting their attention to higher granularity, aiming to profile entire news outlets, which makes it possible to detect likely "fake news" the moment it is published, by simply checking the reliability of its source. Source factuality is also an important element of systems for automatic fact-checking and "fake news" detection, as they need to assess the reliability of the evidence they retrieve online. Political bias detection, which in the Western political landscape is about predicting left-center-right bias, is an equally important topic, which has experienced a similar shift towards profiling entire news outlets. Moreover, there is a clear connection between the two, as highly biased media are less likely to be factual; yet, the two problems have been addressed separately. In this survey, we review the state of the art on media profiling for factuality and bias, arguing for the need to model them jointly. We further discuss interesting recent advances in using different information sources and modalities, which go beyond the text of the articles the target news outlet has published. Finally, we discuss current challenges and outline future research directions.