 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalanceRAG: Joint Risk Calibration for Cascaded Retrieval-Augmented Generation
May 19, 2026Large language models (LLMs) can enhance factuality via retrieval-augmented generation (RAG), but applying RAG to every query is unnecessary when the model-only answer is reliable. This motivates cascaded RAG: each query is first handled by an LLM-only branch, escalated to a RAG fallback only if the primary branch is uncertain, and abstained from when neither branch is sufficiently trustworthy. However, calibrating such cascades stage by stage may be conservative, since the final utility depends on joint uncertainty thresholding of LLM-only and RAG. In this work, we develop BalanceRAG to certify threshold pairs at a target risk level. Given uncertainty scores from the two branches, BalanceRAG frames each threshold pair as an operating point on a two-dimensional lattice and identifies safe operating points using sequential graphical testing. This enables risk-adaptive threshold calibration, controlling the system-level error rate among accepted points, while retaining more examples. Furthermore, BalanceRAG extends to multi-risk calibration, allowing retrieval usage to be bounded together with the selection-conditioned risk. Experiments on three open-domain question answering (QA) benchmarks across multiple LLM backbones demonstrate that BalanceRAG meets prescribed risk levels, preserves higher coverage and more accepted correct examples, and reduces unnecessary retrieval calls compared with always-on RAG.
Breaking the Memory Wall for AI Chip with a New Dimension
Sep 28, 2020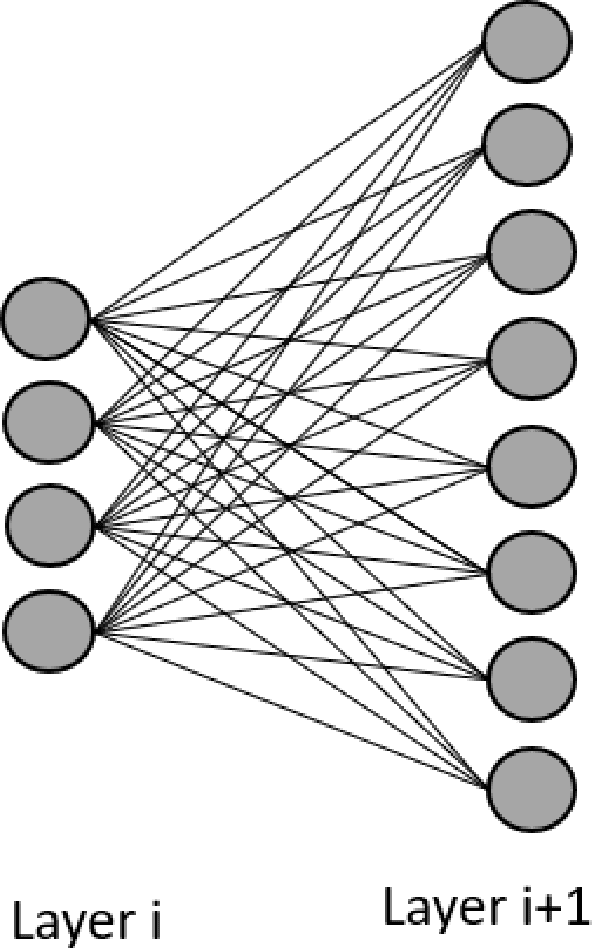
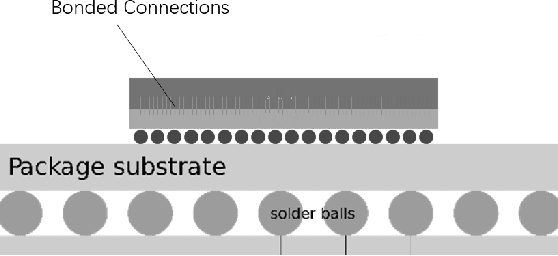
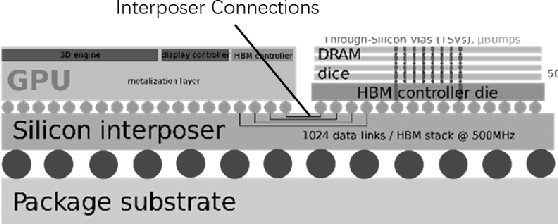
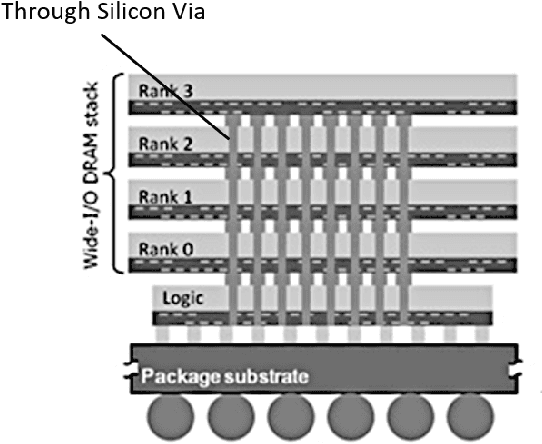
Recent advancements in deep learning have led to the widespread adoption of artificial intelligence (AI) in applications such as computer vision and natural language processing. As neural networks become deeper and larger, AI modeling demands outstrip the capabilities of conventional chip architectures. Memory bandwidth falls behind processing power. Energy consumption comes to dominate the total cost of ownership. Currently, memory capacity is insufficient to support the most advanced NLP models. In this work, we present a 3D AI chip, called Sunrise, with near-memory computing architecture to address these three challenges. This distributed, near-memory computing architecture allows us to tear down the performance-limiting memory wall with an abundance of data bandwidth. We achieve the same level of energy efficiency on 40nm technology as competing chips on 7nm technology. By moving to similar technologies as other AI chips, we project to achieve more than ten times the energy efficiency, seven times the performance of the current state-of-the-art chips, and twenty times of memory capacity as compared with the best chip in each benchmark.