 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlice-and-Forge: Making Better Use of Caches for Graph Convolutional Network Accelerators
Jan 24, 2023



Graph convolutional networks (GCNs) are becoming increasingly popular as they can process a wide variety of data formats that prior deep neural networks cannot easily support. One key challenge in designing hardware accelerators for GCNs is the vast size and randomness in their data access patterns which greatly reduces the effectiveness of the limited on-chip cache. Aimed at improving the effectiveness of the cache by mitigating the irregular data accesses, prior studies often employ the vertex tiling techniques used in traditional graph processing applications. While being effective at enhancing the cache efficiency, those approaches are often sensitive to the tiling configurations where the optimal setting heavily depends on target input datasets. Furthermore, the existing solutions require manual tuning through trial-and-error or rely on sub-optimal analytical models. In this paper, we propose Slice-and-Forge (SnF), an efficient hardware accelerator for GCNs which greatly improves the effectiveness of the limited on-chip cache. SnF chooses a tiling strategy named feature slicing that splits the features into vertical slices and processes them in the outermost loop of the execution. This particular choice results in a repetition of the identical computational patterns over irregular graph data over multiple rounds. Taking advantage of such repetitions, SnF dynamically tunes its tile size. Our experimental results reveal that SnF can achieve 1.73x higher performance in geomean compared to prior work on multi-engine settings, and 1.46x higher performance in geomean on small scale settings, without the need for off-line analyses.
Optimus-CC: Efficient Large NLP Model Training with 3D Parallelism Aware Communication Compression
Jan 24, 2023



In training of modern large natural language processing (NLP) models, it has become a common practice to split models using 3D parallelism to multiple GPUs. Such technique, however, suffers from a high overhead of inter-node communication. Compressing the communication is one way to mitigate the overhead by reducing the inter-node traffic volume; however, the existing compression techniques have critical limitations to be applied for NLP models with 3D parallelism in that 1) only the data parallelism traffic is targeted, and 2) the existing compression schemes already harm the model quality too much. In this paper, we present Optimus-CC, a fast and scalable distributed training framework for large NLP models with aggressive communication compression. Optimus-CC differs from existing communication compression frameworks in the following ways: First, we compress pipeline parallel (inter-stage) traffic. In specific, we compress the inter-stage backpropagation and the embedding synchronization in addition to the existing data-parallel traffic compression methods. Second, we propose techniques to avoid the model quality drop that comes from the compression. We further provide mathematical and empirical analyses to show that our techniques can successfully suppress the compression error. Lastly, we analyze the pipeline and opt to selectively compress those traffic lying on the critical path. This further helps reduce the compression error. We demonstrate our solution on a GPU cluster, and achieve superior speedup from the baseline state-of-the-art solutions for distributed training without sacrificing the model quality.
Enabling Hard Constraints in Differentiable Neural Network and Accelerator Co-Exploration
Jan 23, 2023Co-exploration of an optimal neural architecture and its hardware accelerator is an approach of rising interest which addresses the computational cost problem, especially in low-profile systems. The large co-exploration space is often handled by adopting the idea of differentiable neural architecture search. However, despite the superior search efficiency of the differentiable co-exploration, it faces a critical challenge of not being able to systematically satisfy hard constraints such as frame rate. To handle the hard constraint problem of differentiable co-exploration, we propose HDX, which searches for hard-constrained solutions without compromising the global design objectives. By manipulating the gradients in the interest of the given hard constraint, high-quality solutions satisfying the constraint can be obtained.
ETF Portfolio Construction via Neural Network trained on Financial Statement Data
Jul 04, 2022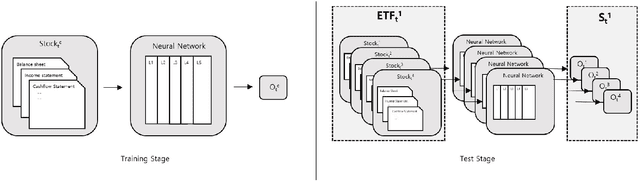
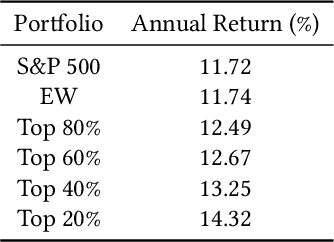
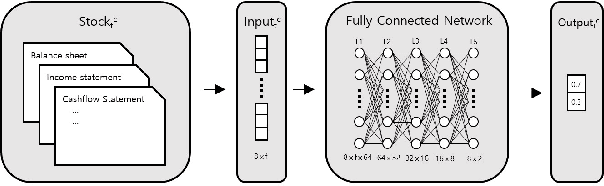
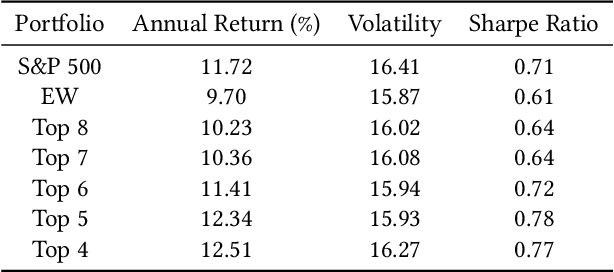
Recently, the application of advanced machine learning methods for asset management has become one of the most intriguing topics. Unfortunately, the application of these methods, such as deep neural networks, is difficult due to the data shortage problem. To address this issue, we propose a novel approach using neural networks to construct a portfolio of exchange traded funds (ETFs) based on the financial statement data of their components. Although a number of ETFs and ETF-managed portfolios have emerged in the past few decades, the ability to apply neural networks to manage ETF portfolios is limited since the number and historical existence of ETFs are relatively smaller and shorter, respectively, than those of individual stocks. Therefore, we use the data of individual stocks to train our neural networks to predict the future performance of individual stocks and use these predictions and the portfolio deposit file (PDF) to construct a portfolio of ETFs. Multiple experiments have been performed, and we have found that our proposed method outperforms the baselines. We believe that our approach can be more beneficial when managing recently listed ETFs, such as thematic ETFs, of which there is relatively limited historical data for training advanced machine learning methods.
Shai-am: A Machine Learning Platform for Investment Strategies
Jul 01, 2022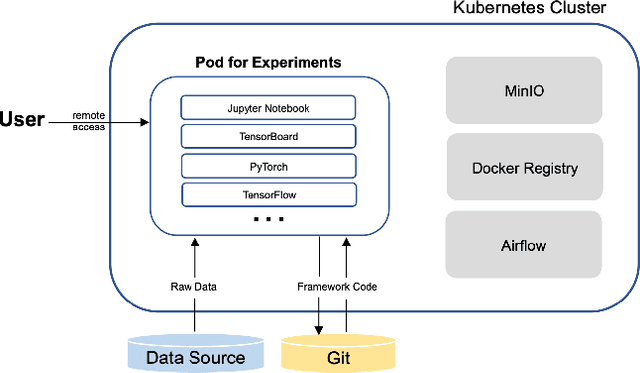
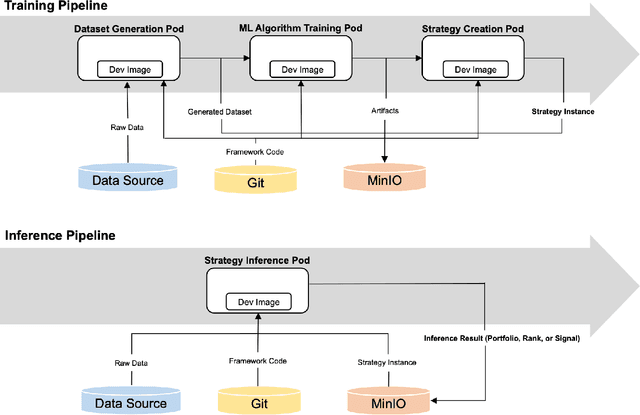
The finance industry has adopted machine learning (ML) as a form of quantitative research to support better investment decisions, yet there are several challenges often overlooked in practice. (1) ML code tends to be unstructured and ad hoc, which hinders cooperation with others. (2) Resource requirements and dependencies vary depending on which algorithm is used, so a flexible and scalable system is needed. (3) It is difficult for domain experts in traditional finance to apply their experience and knowledge in ML-based strategies unless they acquire expertise in recent technologies. This paper presents Shai-am, an ML platform integrated with our own Python framework. The platform leverages existing modern open-source technologies, managing containerized pipelines for ML-based strategies with unified interfaces to solve the aforementioned issues. Each strategy implements the interface defined in the core framework. The framework is designed to enhance reusability and readability, facilitating collaborative work in quantitative research. Shai-am aims to be a pure AI asset manager for solving various tasks in financial markets.
It's All In the Teacher: Zero-Shot Quantization Brought Closer to the Teacher
Apr 01, 2022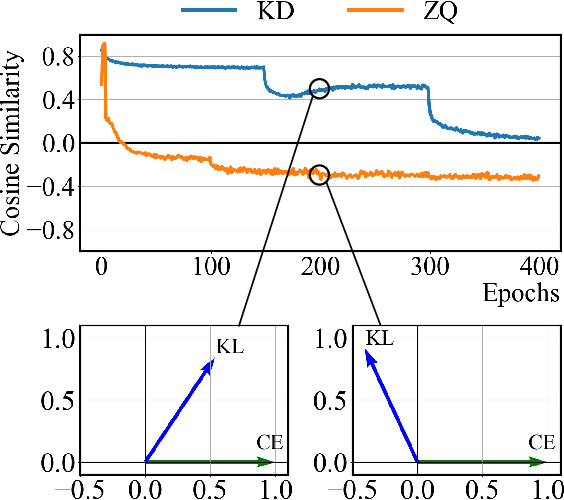
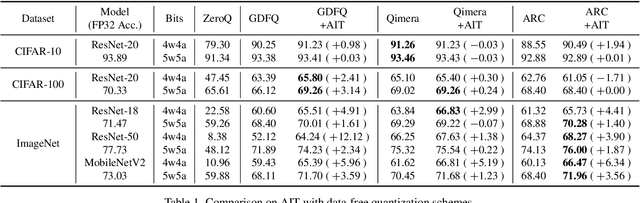
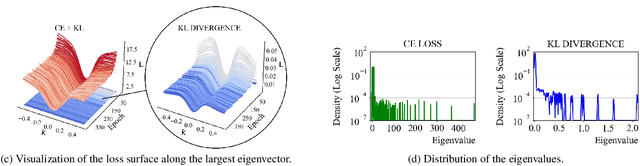
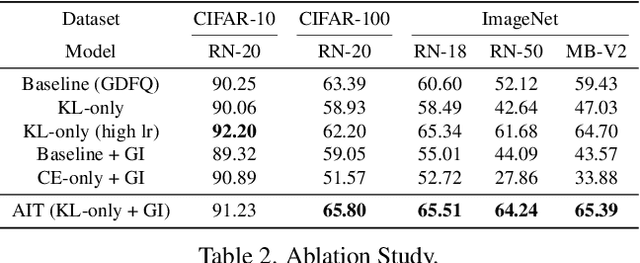
Model quantization is considered as a promising method to greatly reduce the resource requirements of deep neural networks. To deal with the performance drop induced by quantization errors, a popular method is to use training data to fine-tune quantized networks. In real-world environments, however, such a method is frequently infeasible because training data is unavailable due to security, privacy, or confidentiality concerns. Zero-shot quantization addresses such problems, usually by taking information from the weights of a full-precision teacher network to compensate the performance drop of the quantized networks. In this paper, we first analyze the loss surface of state-of-the-art zero-shot quantization techniques and provide several findings. In contrast to usual knowledge distillation problems, zero-shot quantization often suffers from 1) the difficulty of optimizing multiple loss terms together, and 2) the poor generalization capability due to the use of synthetic samples. Furthermore, we observe that many weights fail to cross the rounding threshold during training the quantized networks even when it is necessary to do so for better performance. Based on the observations, we propose AIT, a simple yet powerful technique for zero-shot quantization, which addresses the aforementioned two problems in the following way: AIT i) uses a KL distance loss only without a cross-entropy loss, and ii) manipulates gradients to guarantee that a certain portion of weights are properly updated after crossing the rounding thresholds. Experiments show that AIT outperforms the performance of many existing methods by a great margin, taking over the overall state-of-the-art position in the field.
Qimera: Data-free Quantization with Synthetic Boundary Supporting Samples
Nov 04, 2021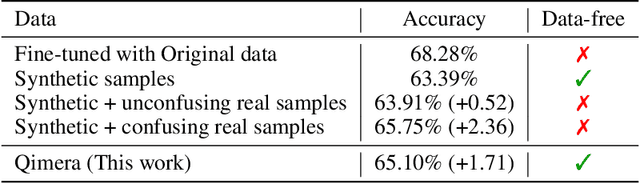
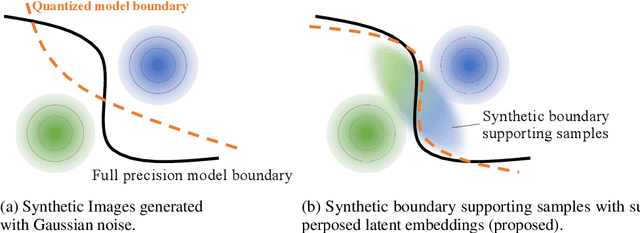
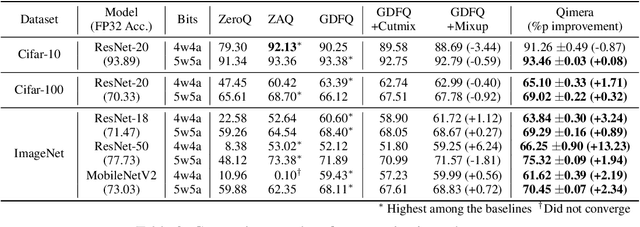
Model quantization is known as a promising method to compress deep neural networks, especially for inferences on lightweight mobile or edge devices. However, model quantization usually requires access to the original training data to maintain the accuracy of the full-precision models, which is often infeasible in real-world scenarios for security and privacy issues. A popular approach to perform quantization without access to the original data is to use synthetically generated samples, based on batch-normalization statistics or adversarial learning. However, the drawback of such approaches is that they primarily rely on random noise input to the generator to attain diversity of the synthetic samples. We find that this is often insufficient to capture the distribution of the original data, especially around the decision boundaries. To this end, we propose Qimera, a method that uses superposed latent embeddings to generate synthetic boundary supporting samples. For the superposed embeddings to better reflect the original distribution, we also propose using an additional disentanglement mapping layer and extracting information from the full-precision model. The experimental results show that Qimera achieves state-of-the-art performances for various settings on data-free quantization. Code is available at https://github.com/iamkanghyunchoi/qimera.
An Attention Module for Convolutional Neural Networks
Aug 18, 2021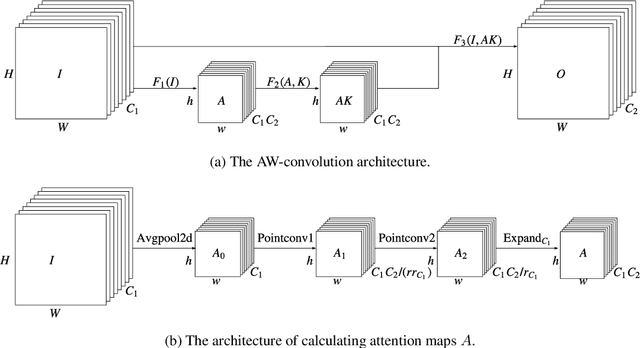
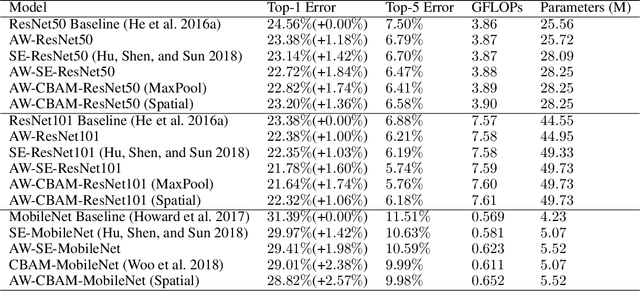
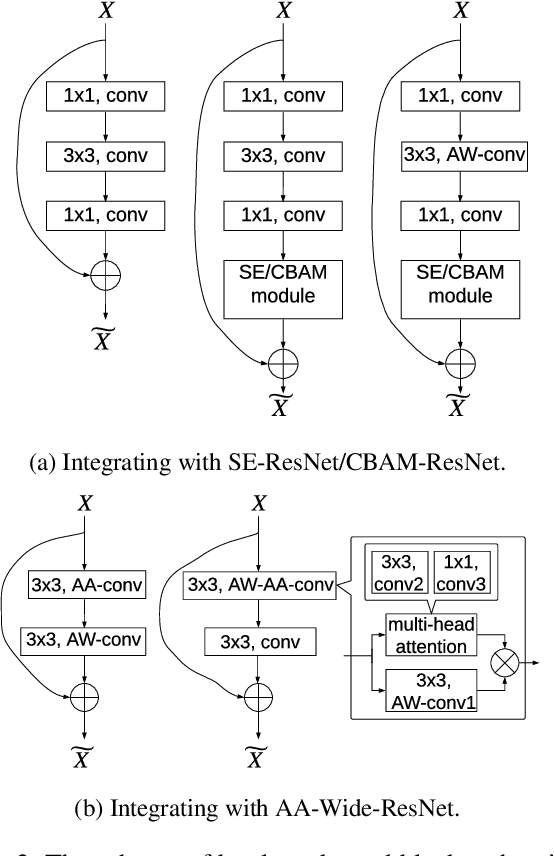
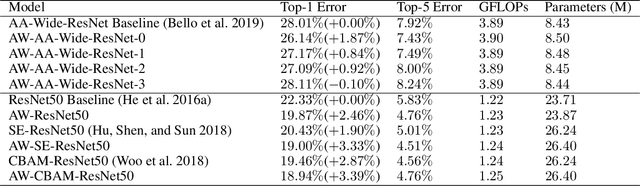
Attention mechanism has been regarded as an advanced technique to capture long-range feature interactions and to boost the representation capability for convolutional neural networks. However, we found two ignored problems in current attentional activations-based models: the approximation problem and the insufficient capacity problem of the attention maps. To solve the two problems together, we initially propose an attention module for convolutional neural networks by developing an AW-convolution, where the shape of attention maps matches that of the weights rather than the activations. Our proposed attention module is a complementary method to previous attention-based schemes, such as those that apply the attention mechanism to explore the relationship between channel-wise and spatial features. Experiments on several datasets for image classification and object detection tasks show the effectiveness of our proposed attention module. In particular, our proposed attention module achieves 1.00% Top-1 accuracy improvement on ImageNet classification over a ResNet101 baseline and 0.63 COCO-style Average Precision improvement on the COCO object detection on top of a Faster R-CNN baseline with the backbone of ResNet101-FPN. When integrating with the previous attentional activations-based models, our proposed attention module can further increase their Top-1 accuracy on ImageNet classification by up to 0.57% and COCO-style Average Precision on the COCO object detection by up to 0.45. Code and pre-trained models will be publicly available.
AutoReCon: Neural Architecture Search-based Reconstruction for Data-free Compression
May 25, 2021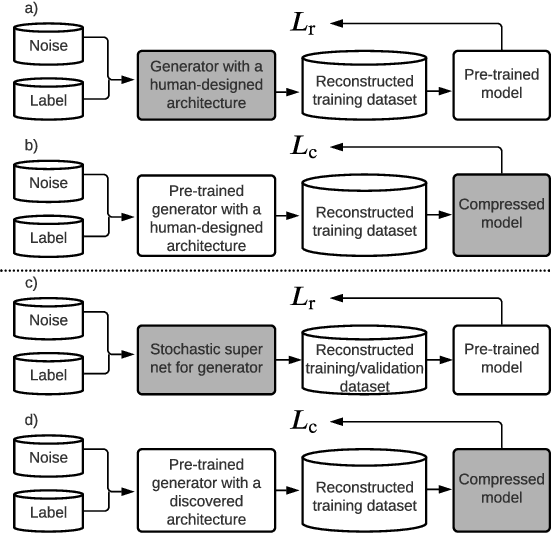
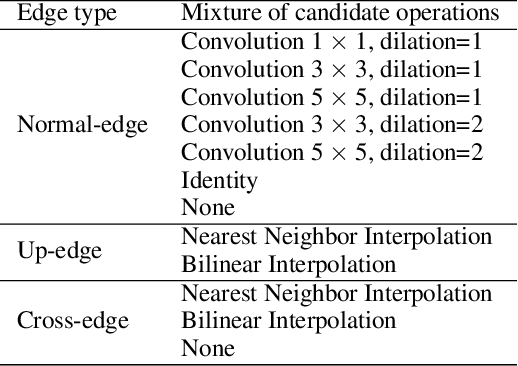
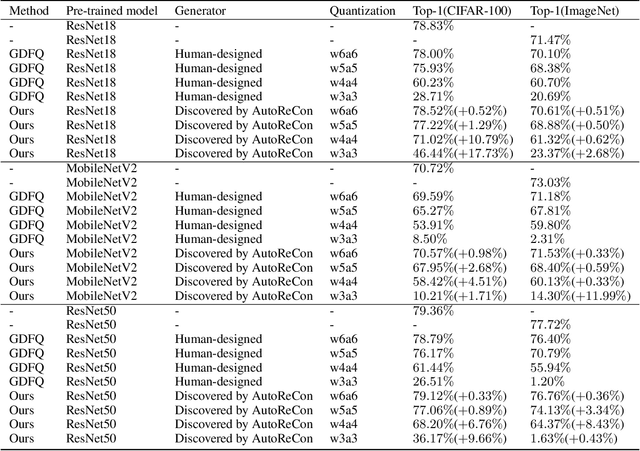
Data-free compression raises a new challenge because the original training dataset for a pre-trained model to be compressed is not available due to privacy or transmission issues. Thus, a common approach is to compute a reconstructed training dataset before compression. The current reconstruction methods compute the reconstructed training dataset with a generator by exploiting information from the pre-trained model. However, current reconstruction methods focus on extracting more information from the pre-trained model but do not leverage network engineering. This work is the first to consider network engineering as an approach to design the reconstruction method. Specifically, we propose the AutoReCon method, which is a neural architecture search-based reconstruction method. In the proposed AutoReCon method, the generator architecture is designed automatically given the pre-trained model for reconstruction. Experimental results show that using generators discovered by the AutoRecon method always improve the performance of data-free compression.
GradPIM: A Practical Processing-in-DRAM Architecture for Gradient Descent
Feb 15, 2021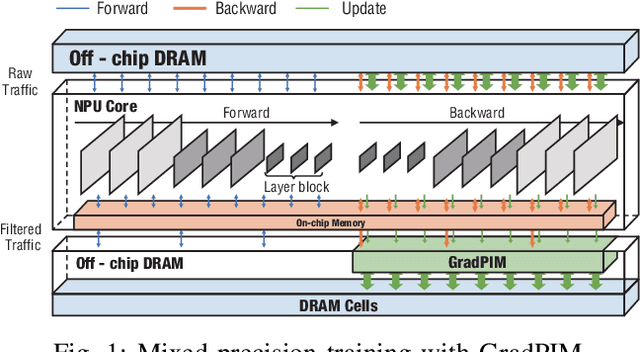
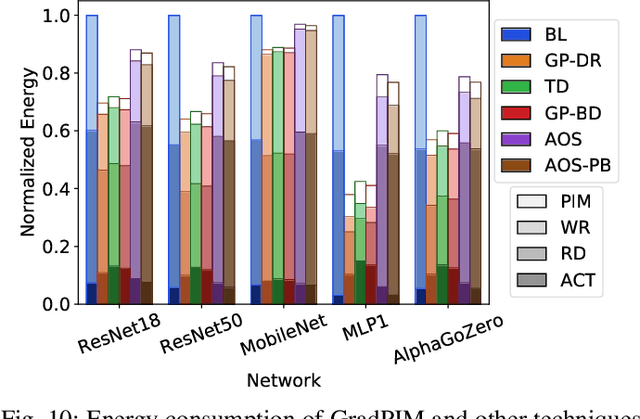
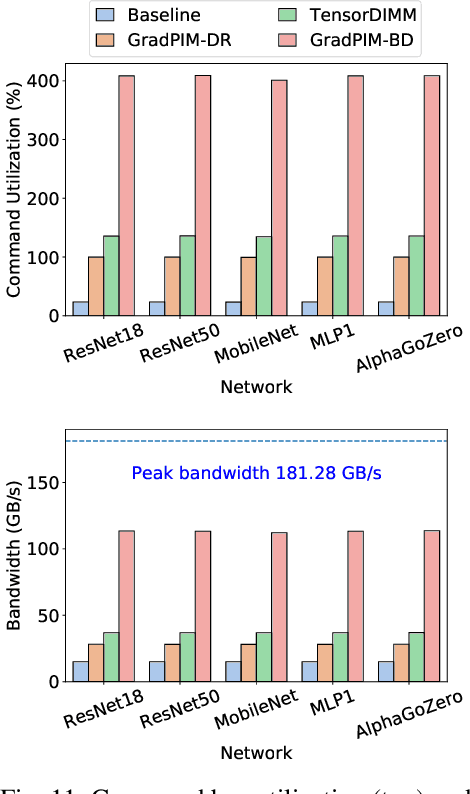
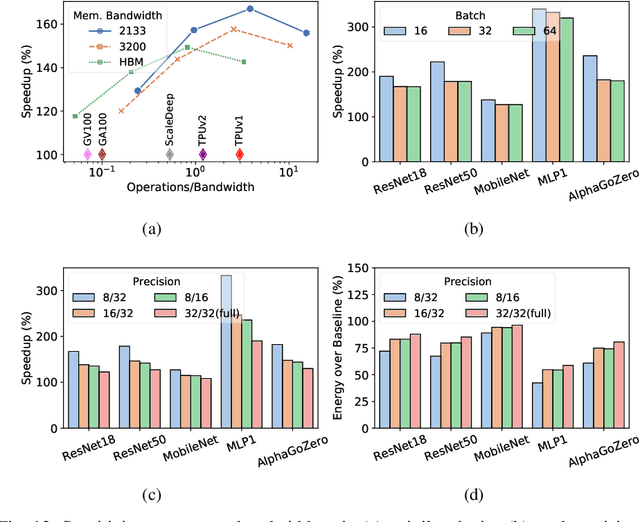
In this paper, we present GradPIM, a processing-in-memory architecture which accelerates parameter updates of deep neural networks training. As one of processing-in-memory techniques that could be realized in the near future, we propose an incremental, simple architectural design that does not invade the existing memory protocol. Extending DDR4 SDRAM to utilize bank-group parallelism makes our operation designs in processing-in-memory (PIM) module efficient in terms of hardware cost and performance. Our experimental results show that the proposed architecture can improve the performance of DNN training and greatly reduce memory bandwidth requirement while posing only a minimal amount of overhead to the protocol and DRAM area.