 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQimera: Data-free Quantization with Synthetic Boundary Supporting Samples
Paper and Code
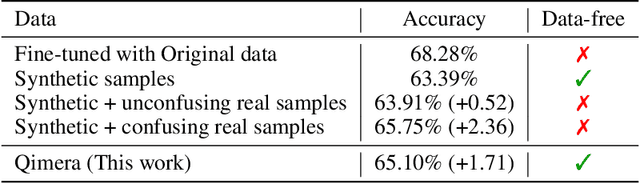
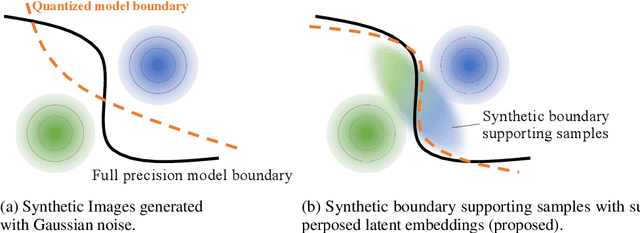
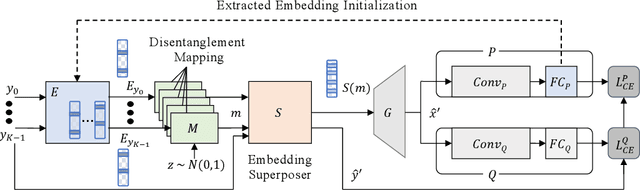
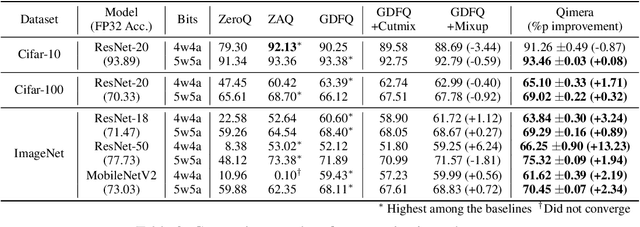
Model quantization is known as a promising method to compress deep neural networks, especially for inferences on lightweight mobile or edge devices. However, model quantization usually requires access to the original training data to maintain the accuracy of the full-precision models, which is often infeasible in real-world scenarios for security and privacy issues. A popular approach to perform quantization without access to the original data is to use synthetically generated samples, based on batch-normalization statistics or adversarial learning. However, the drawback of such approaches is that they primarily rely on random noise input to the generator to attain diversity of the synthetic samples. We find that this is often insufficient to capture the distribution of the original data, especially around the decision boundaries. To this end, we propose Qimera, a method that uses superposed latent embeddings to generate synthetic boundary supporting samples. For the superposed embeddings to better reflect the original distribution, we also propose using an additional disentanglement mapping layer and extracting information from the full-precision model. The experimental results show that Qimera achieves state-of-the-art performances for various settings on data-free quantization. Code is available at https://github.com/iamkanghyunchoi/qimera.