 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustMargin: Training-Free Arbitration between Parametric Memory and Retrieved Evidence in Large Language Models
Jun 07, 2026Large language models answer knowledge-intensive questions using both parametric memory and retrieved evidence, but neither source is uniformly reliable. Retrieval can fill knowledge gaps, yet distracting passages may override correct closed-book answers. We study this post-generation conflict as answer-level source arbitration: given Direct and RAG answers from the same frozen model, decide which source to trust. We propose TRUSTMARGIN, a training-free, plug-and-play arbitration layer that scores the two existing candidates with the model's own likelihoods. It combines a parametric-prior margin, which tests whether memory accepts the retrieved answer, with an evidence-binding margin, which discounts passage-only salience and measures question-specific support. TRUSTMARGIN selects between Direct and RAG without fine-tuning, external judges, or additional generation. Across 2WIKIMQA and CWQA with three LLaMA scales, TRUSTMARGIN consistently improves over Direct generation and BM25-RAG, recovers part of the Direct/RAG oracle gap, and generalizes to multiple training-free RAG pipelines.
InFusionLayer: a CFA-based ensemble tool to generate new classifiers for learning and modeling
Mar 09, 2026Ensemble learning is a well established body of methods for machine learning to enhance predictive performance by combining multiple algorithms/models. Combinatorial Fusion Analysis (CFA) has provided method and practice for combining multiple scoring systems, using rank-score characteristic (RSC) function and cognitive diversity (CD), including ensemble method and model fusion. However, there is no general-purpose Python tool available that incorporate these techniques. In this paper we introduce \texttt{InFusionLayer}, a machine learning architecture inspired by CFA at the system fusion level that uses a moderate set of base models to optimize unsupervised and supervised learning multiclassification problems. We demonstrate \texttt{InFusionLayer}'s ease of use for PyTorch, TensorFlow, and Scikit-learn workflows by validating its performance on various computer vision datasets. Our results highlight the practical advantages of incorporating distinctive features of RSC function and CD, paving the way for more sophisticated ensemble learning applications in machine learning. We open-sourced our code to encourage continuing development and community accessibility to leverage CFA on github: https://github.com/ewroginek/Infusion
Masks Fusion with Multi-Target Learning For Speech Enhancement
Sep 28, 2021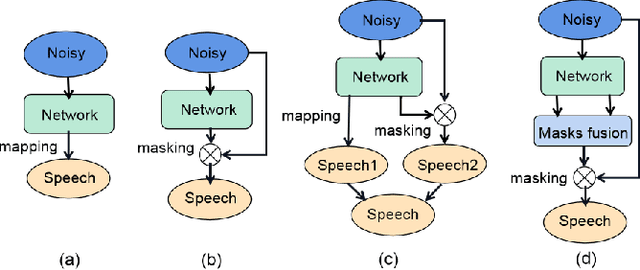
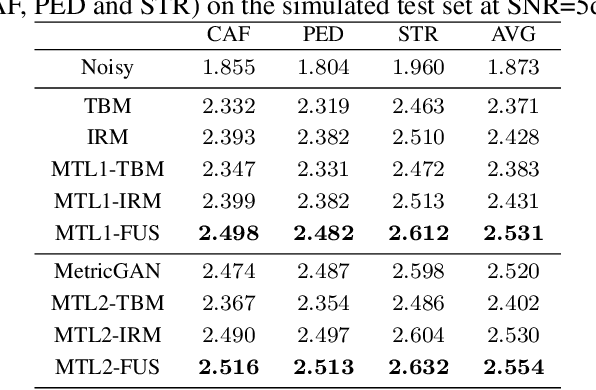
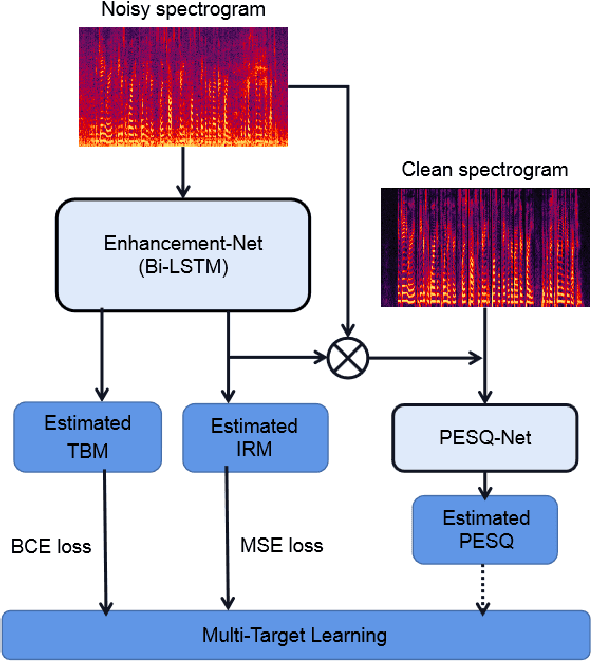
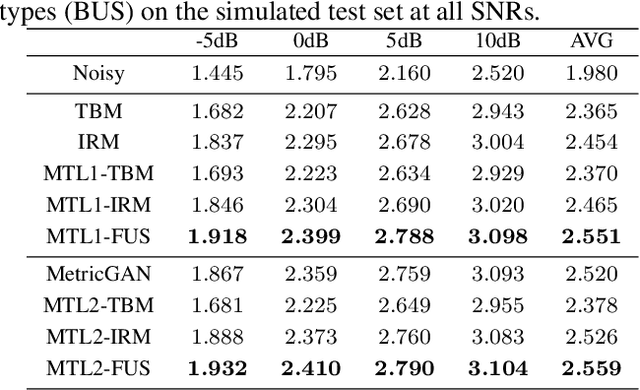
Recently, deep neural network (DNN) based time-frequency (T-F) mask estimation has shown remarkable effectiveness for speech enhancement. Typically, a single T-F mask is first estimated based on DNN and then used to mask the spectrogram of noisy speech in an order to suppress the noise. This work proposes a multi-mask fusion method for speech enhancement. It simultaneously estimates two complementary masks, e.g., ideal ratio mask (IRM) and target binary mask (TBM), and then fuse them to obtain a refined mask for speech enhancement. The advantage of the new method is twofold. First, simultaneously estimating multiple complementary masks brings benefit endowed by multi-target learning. Second, multi-mask fusion can exploit the complementarity of multiple masks to boost the performance of speech enhancement. Experimental results show that the proposed method can achieve significant PESQ improvement and reduce the recognition error rate of back-end over traditional masking-based methods. Code is available at https://github.com/lc-zhou/mask-fusion.