 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards A Scalable Solution for Improving Multi-Group Fairness in Compositional Classification
Jul 11, 2023Despite the rich literature on machine learning fairness, relatively little attention has been paid to remediating complex systems, where the final prediction is the combination of multiple classifiers and where multiple groups are present. In this paper, we first show that natural baseline approaches for improving equal opportunity fairness scale linearly with the product of the number of remediated groups and the number of remediated prediction labels, rendering them impractical. We then introduce two simple techniques, called {\em task-overconditioning} and {\em group-interleaving}, to achieve a constant scaling in this multi-group multi-label setup. Our experimental results in academic and real-world environments demonstrate the effectiveness of our proposal at mitigation within this environment.
Let's Do a Thought Experiment: Using Counterfactuals to Improve Moral Reasoning
Jun 25, 2023Language models still struggle on moral reasoning, despite their impressive performance in many other tasks. In particular, the Moral Scenarios task in MMLU (Multi-task Language Understanding) is among the worst performing tasks for many language models, including GPT-3. In this work, we propose a new prompting framework, Thought Experiments, to teach language models to do better moral reasoning using counterfactuals. Experiment results show that our framework elicits counterfactual questions and answers from the model, which in turn helps improve the accuracy on Moral Scenarios task by 9-16% compared to other zero-shot baselines. Interestingly, unlike math reasoning tasks, zero-shot Chain-of-Thought (CoT) reasoning doesn't work out of the box, and even reduces accuracy by around 4% compared to direct zero-shot. We further observed that with minimal human supervision in the form of 5 few-shot examples, the accuracy of the task can be improved to as much as 80%.
Improving Classifier Robustness through Active Generation of Pairwise Counterfactuals
May 22, 2023Counterfactual Data Augmentation (CDA) is a commonly used technique for improving robustness in natural language classifiers. However, one fundamental challenge is how to discover meaningful counterfactuals and efficiently label them, with minimal human labeling cost. Most existing methods either completely rely on human-annotated labels, an expensive process which limits the scale of counterfactual data, or implicitly assume label invariance, which may mislead the model with incorrect labels. In this paper, we present a novel framework that utilizes counterfactual generative models to generate a large number of diverse counterfactuals by actively sampling from regions of uncertainty, and then automatically label them with a learned pairwise classifier. Our key insight is that we can more correctly label the generated counterfactuals by training a pairwise classifier that interpolates the relationship between the original example and the counterfactual. We demonstrate that with a small amount of human-annotated counterfactual data (10%), we can generate a counterfactual augmentation dataset with learned labels, that provides an 18-20% improvement in robustness and a 14-21% reduction in errors on 6 out-of-domain datasets, comparable to that of a fully human-annotated counterfactual dataset for both sentiment classification and question paraphrase tasks.
Investigating Ensemble Methods for Model Robustness Improvement of Text Classifiers
Oct 28, 2022Large pre-trained language models have shown remarkable performance over the past few years. These models, however, sometimes learn superficial features from the dataset and cannot generalize to the distributions that are dissimilar to the training scenario. There have been several approaches proposed to reduce model's reliance on these bias features which can improve model robustness in the out-of-distribution setting. However, existing methods usually use a fixed low-capacity model to deal with various bias features, which ignore the learnability of those features. In this paper, we analyze a set of existing bias features and demonstrate there is no single model that works best for all the cases. We further show that by choosing an appropriate bias model, we can obtain a better robustness result than baselines with a more sophisticated model design.
A Human-ML Collaboration Framework for Improving Video Content Reviews
Oct 18, 2022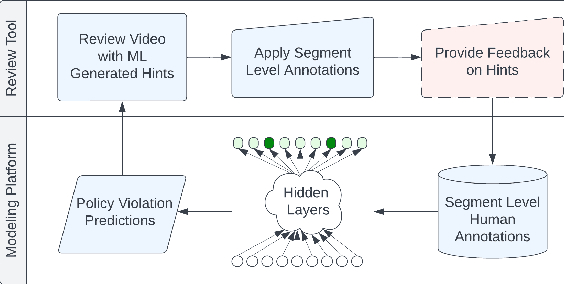

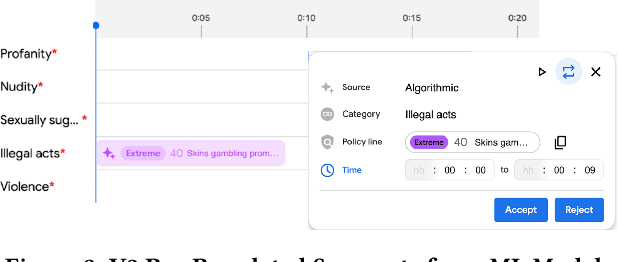
We deal with the problem of localized in-video taxonomic human annotation in the video content moderation domain, where the goal is to identify video segments that violate granular policies, e.g., community guidelines on an online video platform. High quality human labeling is critical for enforcement in content moderation. This is challenging due to the problem of information overload - raters need to apply a large taxonomy of granular policy violations with ambiguous definitions, within a limited review duration to relatively long videos. Our key contribution is a novel human-machine learning (ML) collaboration framework aimed at maximizing the quality and efficiency of human decisions in this setting - human labels are used to train segment-level models, the predictions of which are displayed as "hints" to human raters, indicating probable regions of the video with specific policy violations. The human verified/corrected segment labels can help refine the model further, hence creating a human-ML positive feedback loop. Experiments show improved human video moderation decision quality, and efficiency through more granular annotations submitted within a similar review duration, which enable a 5-8% AUC improvement in the hint generation models.
Simpson's Paradox in Recommender Fairness: Reconciling differences between per-user and aggregated evaluations
Oct 14, 2022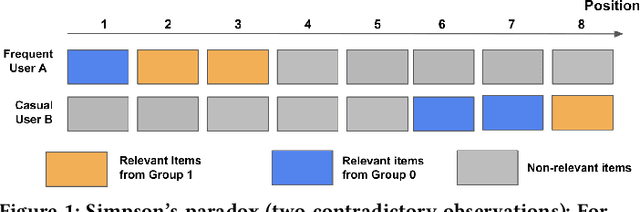
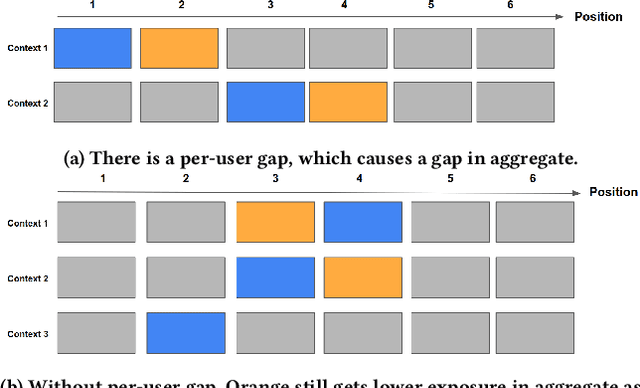
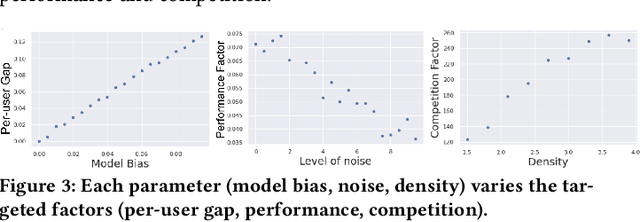
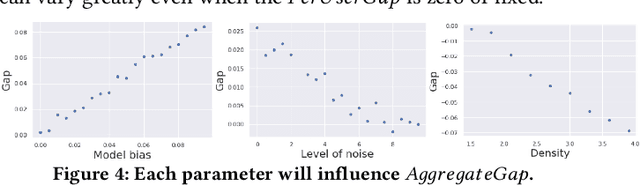
There has been a flurry of research in recent years on notions of fairness in ranking and recommender systems, particularly on how to evaluate if a recommender allocates exposure equally across groups of relevant items (also known as provider fairness). While this research has laid an important foundation, it gave rise to different approaches depending on whether relevant items are compared per-user/per-query or aggregated across users. Despite both being established and intuitive, we discover that these two notions can lead to opposite conclusions, a form of Simpson's Paradox. We reconcile these notions and show that the tension is due to differences in distributions of users where items are relevant, and break down the important factors of the user's recommendations. Based on this new understanding, practitioners might be interested in either notions, but might face challenges with the per-user metric due to partial observability of the relevance and user satisfaction, typical in real-world recommenders. We describe a technique based on distribution matching to estimate it in such a scenario. We demonstrate on simulated and real-world recommender data the effectiveness and usefulness of such an approach.
Flexible text generation for counterfactual fairness probing
Jun 28, 2022

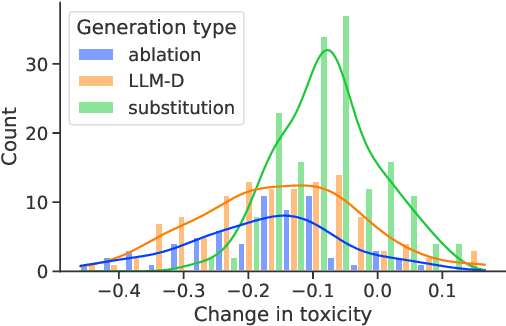
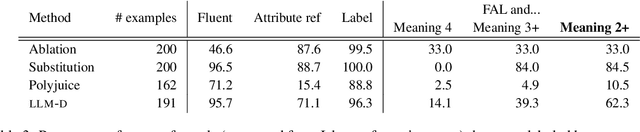
A common approach for testing fairness issues in text-based classifiers is through the use of counterfactuals: does the classifier output change if a sensitive attribute in the input is changed? Existing counterfactual generation methods typically rely on wordlists or templates, producing simple counterfactuals that don't take into account grammar, context, or subtle sensitive attribute references, and could miss issues that the wordlist creators had not considered. In this paper, we introduce a task for generating counterfactuals that overcomes these shortcomings, and demonstrate how large language models (LLMs) can be leveraged to make progress on this task. We show that this LLM-based method can produce complex counterfactuals that existing methods cannot, comparing the performance of various counterfactual generation methods on the Civil Comments dataset and showing their value in evaluating a toxicity classifier.
Understanding and Improving Fairness-Accuracy Trade-offs in Multi-Task Learning
Jun 04, 2021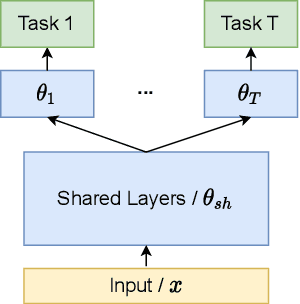
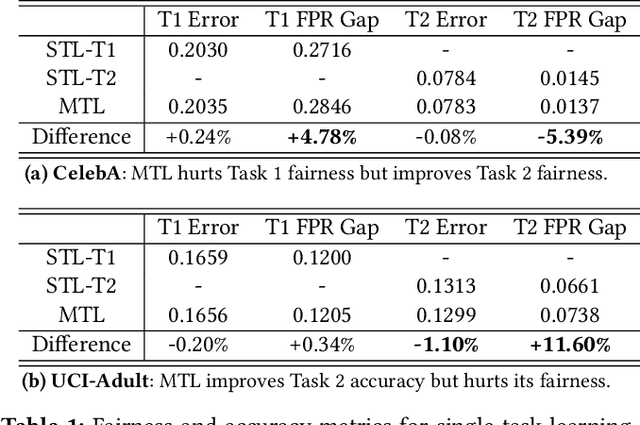
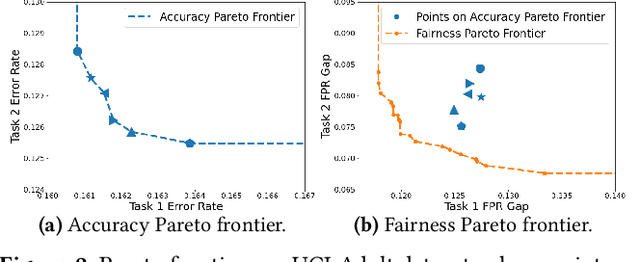
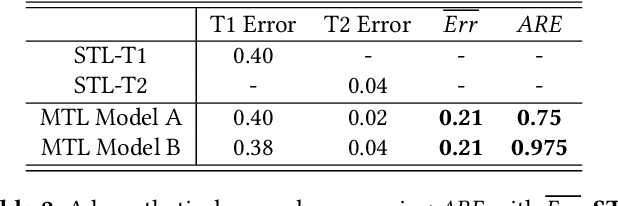
As multi-task models gain popularity in a wider range of machine learning applications, it is becoming increasingly important for practitioners to understand the fairness implications associated with those models. Most existing fairness literature focuses on learning a single task more fairly, while how ML fairness interacts with multiple tasks in the joint learning setting is largely under-explored. In this paper, we are concerned with how group fairness (e.g., equal opportunity, equalized odds) as an ML fairness concept plays out in the multi-task scenario. In multi-task learning, several tasks are learned jointly to exploit task correlations for a more efficient inductive transfer. This presents a multi-dimensional Pareto frontier on (1) the trade-off between group fairness and accuracy with respect to each task, as well as (2) the trade-offs across multiple tasks. We aim to provide a deeper understanding on how group fairness interacts with accuracy in multi-task learning, and we show that traditional approaches that mainly focus on optimizing the Pareto frontier of multi-task accuracy might not perform well on fairness goals. We propose a new set of metrics to better capture the multi-dimensional Pareto frontier of fairness-accuracy trade-offs uniquely presented in a multi-task learning setting. We further propose a Multi-Task-Aware Fairness (MTA-F) approach to improve fairness in multi-task learning. Experiments on several real-world datasets demonstrate the effectiveness of our proposed approach.
Measuring Model Fairness under Noisy Covariates: A Theoretical Perspective
May 20, 2021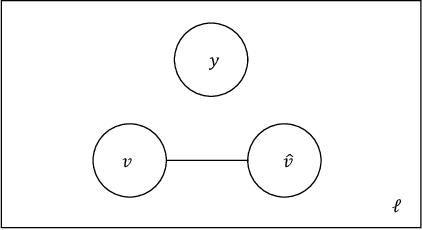
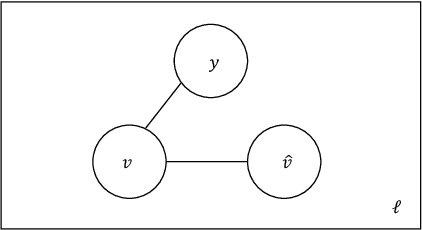
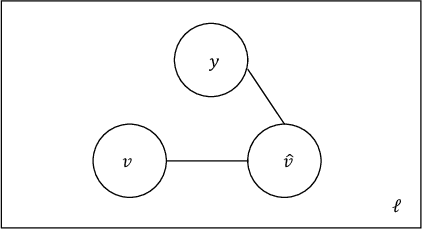
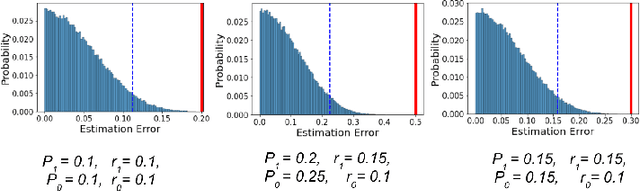
In this work we study the problem of measuring the fairness of a machine learning model under noisy information. Focusing on group fairness metrics, we investigate the particular but common situation when the evaluation requires controlling for the confounding effect of covariate variables. In a practical setting, we might not be able to jointly observe the covariate and group information, and a standard workaround is to then use proxies for one or more of these variables. Prior works have demonstrated the challenges with using a proxy for sensitive attributes, and strong independence assumptions are needed to provide guarantees on the accuracy of the noisy estimates. In contrast, in this work we study using a proxy for the covariate variable and present a theoretical analysis that aims to characterize weaker conditions under which accurate fairness evaluation is possible. Furthermore, our theory identifies potential sources of errors and decouples them into two interpretable parts $\gamma$ and $\epsilon$. The first part $\gamma$ depends solely on the performance of the proxy such as precision and recall, whereas the second part $\epsilon$ captures correlations between all the variables of interest. We show that in many scenarios the error in the estimates is dominated by $\gamma$ via a linear dependence, whereas the dependence on the correlations $\epsilon$ only constitutes a lower order term. As a result we expand the understanding of scenarios where measuring model fairness via proxies can be an effective approach. Finally, we compare, via simulations, the theoretical upper-bounds to the distribution of simulated estimation errors and show that assuming some structure on the data, even weak, is key to significantly improve both theoretical guarantees and empirical results.
Measuring Recommender System Effects with Simulated Users
Jan 12, 2021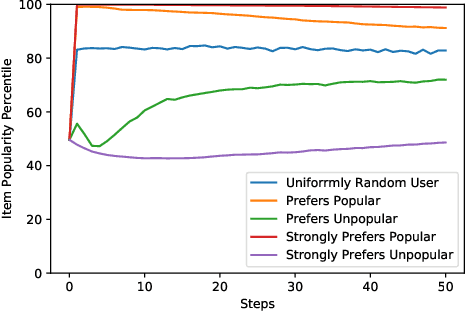

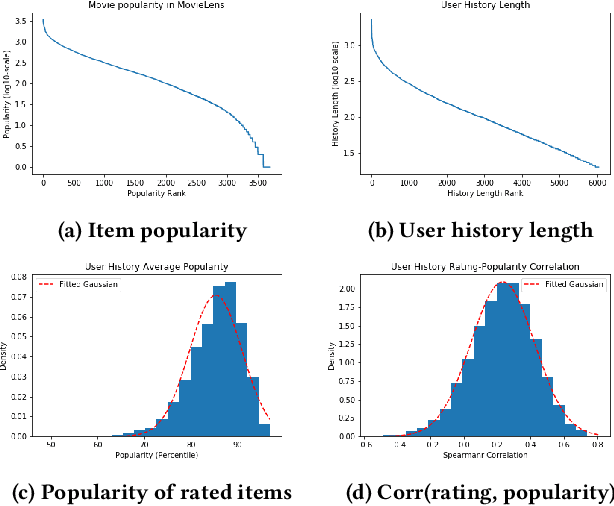
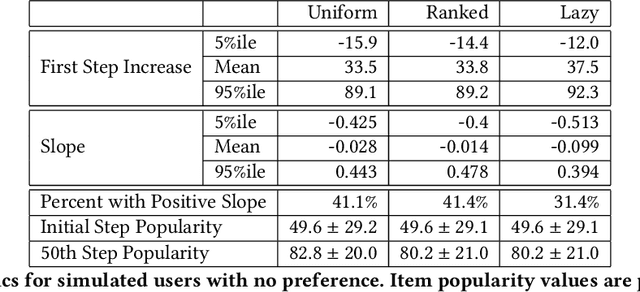
Imagine a food recommender system -- how would we check if it is \emph{causing} and fostering unhealthy eating habits or merely reflecting users' interests? How much of a user's experience over time with a recommender is caused by the recommender system's choices and biases, and how much is based on the user's preferences and biases? Popularity bias and filter bubbles are two of the most well-studied recommender system biases, but most of the prior research has focused on understanding the system behavior in a single recommendation step. How do these biases interplay with user behavior, and what types of user experiences are created from repeated interactions? In this work, we offer a simulation framework for measuring the impact of a recommender system under different types of user behavior. Using this simulation framework, we can (a) isolate the effect of the recommender system from the user preferences, and (b) examine how the system performs not just on average for an "average user" but also the extreme experiences under atypical user behavior. As part of the simulation framework, we propose a set of evaluation metrics over the simulations to understand the recommender system's behavior. Finally, we present two empirical case studies -- one on traditional collaborative filtering in MovieLens and one on a large-scale production recommender system -- to understand how popularity bias manifests over time.