 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Augmented LLMs Achieve Therapist-Level Responses in Motivational Interviewing
May 23, 2025Large language models (LLMs) like GPT-4 show potential for scaling motivational interviewing (MI) in addiction care, but require systematic evaluation of therapeutic capabilities. We present a computational framework assessing user-perceived quality (UPQ) through expected and unexpected MI behaviors. Analyzing human therapist and GPT-4 MI sessions via human-AI collaboration, we developed predictive models integrating deep learning and explainable AI to identify 17 MI-consistent (MICO) and MI-inconsistent (MIIN) behavioral metrics. A customized chain-of-thought prompt improved GPT-4's MI performance, reducing inappropriate advice while enhancing reflections and empathy. Although GPT-4 remained marginally inferior to therapists overall, it demonstrated superior advice management capabilities. The model achieved measurable quality improvements through prompt engineering, yet showed limitations in addressing complex emotional nuances. This framework establishes a pathway for optimizing LLM-based therapeutic tools through targeted behavioral metric analysis and human-AI co-evaluation. Findings highlight both the scalability potential and current constraints of LLMs in clinical communication applications.
A Human-ML Collaboration Framework for Improving Video Content Reviews
Oct 18, 2022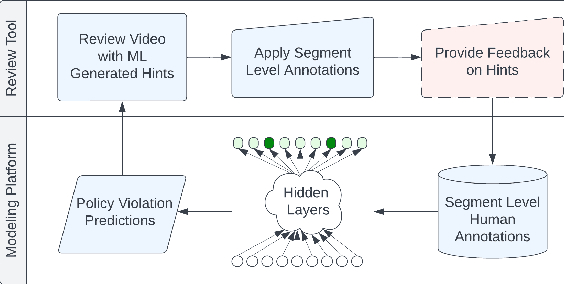
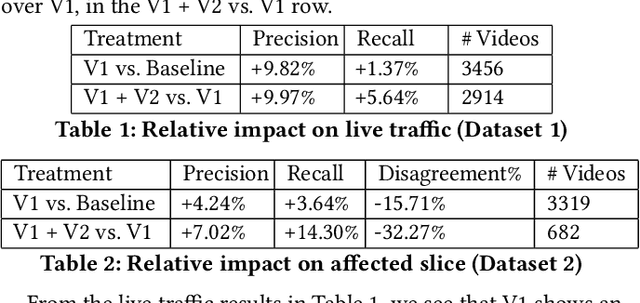

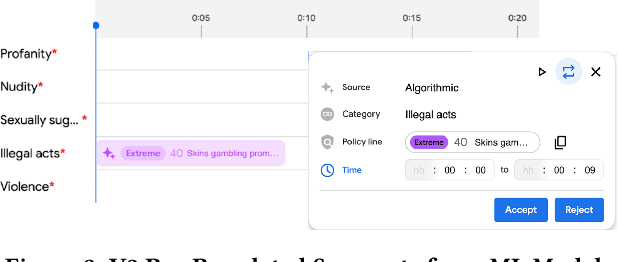
We deal with the problem of localized in-video taxonomic human annotation in the video content moderation domain, where the goal is to identify video segments that violate granular policies, e.g., community guidelines on an online video platform. High quality human labeling is critical for enforcement in content moderation. This is challenging due to the problem of information overload - raters need to apply a large taxonomy of granular policy violations with ambiguous definitions, within a limited review duration to relatively long videos. Our key contribution is a novel human-machine learning (ML) collaboration framework aimed at maximizing the quality and efficiency of human decisions in this setting - human labels are used to train segment-level models, the predictions of which are displayed as "hints" to human raters, indicating probable regions of the video with specific policy violations. The human verified/corrected segment labels can help refine the model further, hence creating a human-ML positive feedback loop. Experiments show improved human video moderation decision quality, and efficiency through more granular annotations submitted within a similar review duration, which enable a 5-8% AUC improvement in the hint generation models.