 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSilencer: From Discovery to Mitigation of Self-Bias in LLM-as-Benchmark-Generator
Paper and Code
May 27, 2025


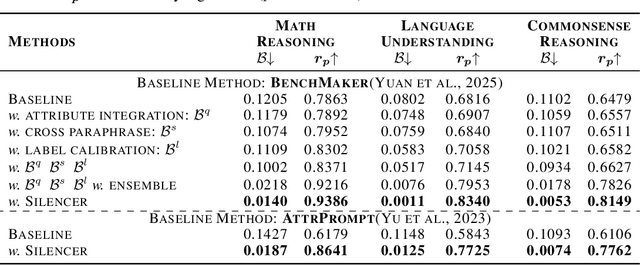
LLM-as-Benchmark-Generator methods have been widely studied as a supplement to human annotators for scalable evaluation, while the potential biases within this paradigm remain underexplored. In this work, we systematically define and validate the phenomenon of inflated performance in models evaluated on their self-generated benchmarks, referred to as self-bias, and attribute it to sub-biases arising from question domain, language style, and wrong labels. On this basis, we propose Silencer, a general framework that leverages the heterogeneity between multiple generators at both the sample and benchmark levels to neutralize bias and generate high-quality, self-bias-silenced benchmark. Experimental results across various settings demonstrate that Silencer can suppress self-bias to near zero, significantly improve evaluation effectiveness of the generated benchmark (with an average improvement from 0.655 to 0.833 in Pearson correlation with high-quality human-annotated benchmark), while also exhibiting strong generalizability.