 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAct While Thinking: Accelerating LLM Agents via Pattern-Aware Speculative Tool Execution
Mar 19, 2026LLM-powered agents are emerging as a dominant paradigm for autonomous task solving. Unlike standard inference workloads, agents operate in a strictly serial "LLM-tool" loop, where the LLM must wait for external tool execution at every step. This execution model introduces severe latency bottlenecks. To address this problem, we propose PASTE, a Pattern-Aware Speculative Tool Execution method designed to hide tool latency through speculation. PASTE is based on the insight that although agent requests are semantically diverse, they exhibit stable application level control flows (recurring tool-call sequences) and predictable data dependencies (parameter passing between tools). By exploiting these properties, PASTE improves agent serving performance through speculative tool execution. Experimental results against state of the art baselines show that PASTE reduces average task completion time by 48.5% and improves tool execution throughput by 1.8x.
MLOW: Interpretable Low-Rank Frequency Magnitude Decomposition of Multiple Effects for Time Series Forecasting
Mar 19, 2026Separating multiple effects in time series is fundamental yet challenging for time-series forecasting (TSF). However, existing TSF models cannot effectively learn interpretable multi-effect decomposition by their smoothing-based temporal techniques. Here, a new interpretable frequency-based decomposition pipeline MLOW captures the insight: a time series can be represented as a magnitude spectrum multiplied by the corresponding phase-aware basis functions, and the magnitude spectrum distribution of a time series always exhibits observable patterns for different effects. MLOW learns a low-rank representation of the magnitude spectrum to capture dominant trending and seasonal effects. We explore low-rank methods, including PCA, NMF, and Semi-NMF, and find that none can simultaneously achieve interpretable, efficient and generalizable decomposition. Thus, we propose hyperplane-nonnegative matrix factorization (Hyperplane-NMF). Further, to address the frequency (spectral) leakage restricting high-quality low-rank decomposition, MLOW enables a flexible selection of input horizons and frequency levels via a mathematical mechanism. Visual analysis demonstrates that MLOW enables interpretable and hierarchical multiple-effect decomposition, robust to noises. It can also enable plug-and-play in existing TSF backbones with remarkable performance improvement but minimal architectural modifications.
Few to Big: Prototype Expansion Network via Diffusion Learner for Point Cloud Few-shot Semantic Segmentation
Sep 16, 2025Few-shot 3D point cloud semantic segmentation aims to segment novel categories using a minimal number of annotated support samples. While existing prototype-based methods have shown promise, they are constrained by two critical challenges: (1) Intra-class Diversity, where a prototype's limited representational capacity fails to cover a class's full variations, and (2) Inter-set Inconsistency, where prototypes derived from the support set are misaligned with the query feature space. Motivated by the powerful generative capability of diffusion model, we re-purpose its pre-trained conditional encoder to provide a novel source of generalizable features for expanding the prototype's representational range. Under this setup, we introduce the Prototype Expansion Network (PENet), a framework that constructs big-capacity prototypes from two complementary feature sources. PENet employs a dual-stream learner architecture: it retains a conventional fully supervised Intrinsic Learner (IL) to distill representative features, while introducing a novel Diffusion Learner (DL) to provide rich generalizable features. The resulting dual prototypes are then processed by a Prototype Assimilation Module (PAM), which adopts a novel push-pull cross-guidance attention block to iteratively align the prototypes with the query space. Furthermore, a Prototype Calibration Mechanism (PCM) regularizes the final big capacity prototype to prevent semantic drift. Extensive experiments on the S3DIS and ScanNet datasets demonstrate that PENet significantly outperforms state-of-the-art methods across various few-shot settings.
ServerlessLoRA: Minimizing Latency and Cost in Serverless Inference for LoRA-Based LLMs
May 20, 2025Serverless computing has grown rapidly for serving Large Language Model (LLM) inference due to its pay-as-you-go pricing, fine-grained GPU usage, and rapid scaling. However, our analysis reveals that current serverless can effectively serve general LLM but fail with Low-Rank Adaptation (LoRA) inference due to three key limitations: 1) massive parameter redundancy among functions where 99% of weights are unnecessarily duplicated, 2) costly artifact loading latency beyond LLM loading, and 3) magnified resource contention when serving multiple LoRA LLMs. These inefficiencies lead to massive GPU wastage, increased Time-To-First-Token (TTFT), and high monetary costs. We propose ServerlessLoRA, a novel serverless inference system designed for faster and cheaper LoRA LLM serving. ServerlessLoRA enables secure backbone LLM sharing across isolated LoRA functions to reduce redundancy. We design a pre-loading method that pre-loads comprehensive LoRA artifacts to minimize cold-start latency. Furthermore, ServerlessLoRA employs contention aware batching and offloading to mitigate GPU resource conflicts during bursty workloads. Experiment on industrial workloads demonstrates that ServerlessLoRA reduces TTFT by up to 86% and cuts monetary costs by up to 89% compared to state-of-the-art LLM inference solutions.
An Approach for GCI Fusion With Labeled Multitarget Densities
Oct 28, 2020
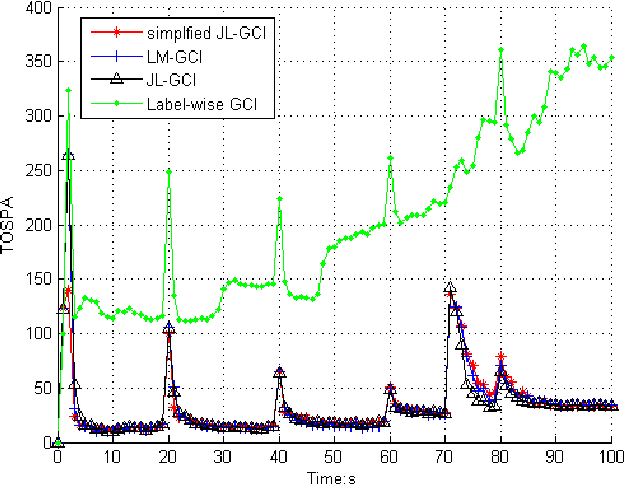
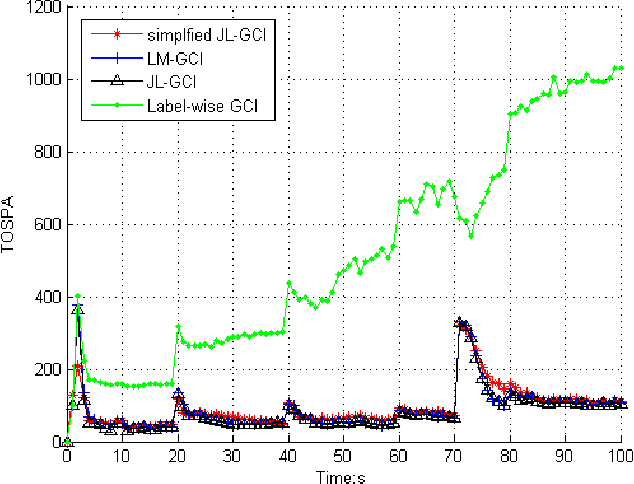
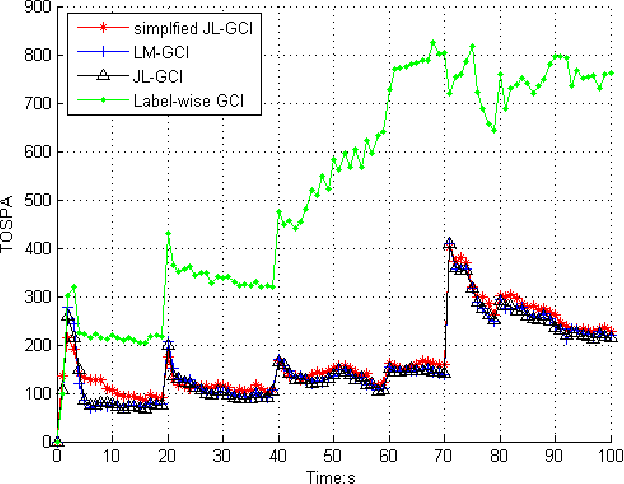
This paper addresses the Generalized Covariance Intersection (GCI) fusion method for labeled random finite sets. We propose a joint label space for the support of fused labeled random finite sets to represent the label association between different agents, avoiding the label consistency condition for the label-wise GCI fusion algorithm. Specifically, we devise the joint label space by the direct product of all label spaces for each agent. Then we apply the GCI fusion method to obtain the joint labeled multi-target density. The joint labeled RFS is then marginalized into a general labeled RFS, providing that each target is represented by a single Bernoulli component with a unique label. The joint labeled GCI (JL-GCI) for fusing LMB RFSs from different agents is demonstrated. We also propose the simplified JL-GCI method given the assumption that targets are well-separated in the scenario. The simulation result presents the effectiveness of label inconsistency and excellent performance in challenging tracking scenarios.