 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DTeethSAM: Taming SAM2 for 3D Teeth Segmentation
Dec 12, 2025



3D teeth segmentation, involving the localization of tooth instances and their semantic categorization in 3D dental models, is a critical yet challenging task in digital dentistry due to the complexity of real-world dentition. In this paper, we propose 3DTeethSAM, an adaptation of the Segment Anything Model 2 (SAM2) for 3D teeth segmentation. SAM2 is a pretrained foundation model for image and video segmentation, demonstrating a strong backbone in various downstream scenarios. To adapt SAM2 for 3D teeth data, we render images of 3D teeth models from predefined views, apply SAM2 for 2D segmentation, and reconstruct 3D results using 2D-3D projections. Since SAM2's performance depends on input prompts and its initial outputs often have deficiencies, and given its class-agnostic nature, we introduce three light-weight learnable modules: (1) a prompt embedding generator to derive prompt embeddings from image embeddings for accurate mask decoding, (2) a mask refiner to enhance SAM2's initial segmentation results, and (3) a mask classifier to categorize the generated masks. Additionally, we incorporate Deformable Global Attention Plugins (DGAP) into SAM2's image encoder. The DGAP enhances both the segmentation accuracy and the speed of the training process. Our method has been validated on the 3DTeethSeg benchmark, achieving an IoU of 91.90% on high-resolution 3D teeth meshes, establishing a new state-of-the-art in the field.
3D Facial Geometry Recovery from a Depth View with Attention Guided Generative Adversarial Network
Sep 02, 2020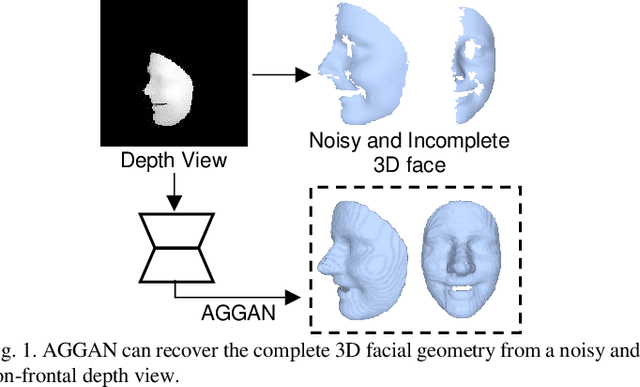
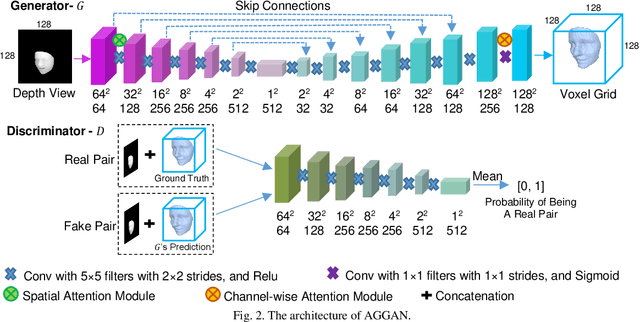
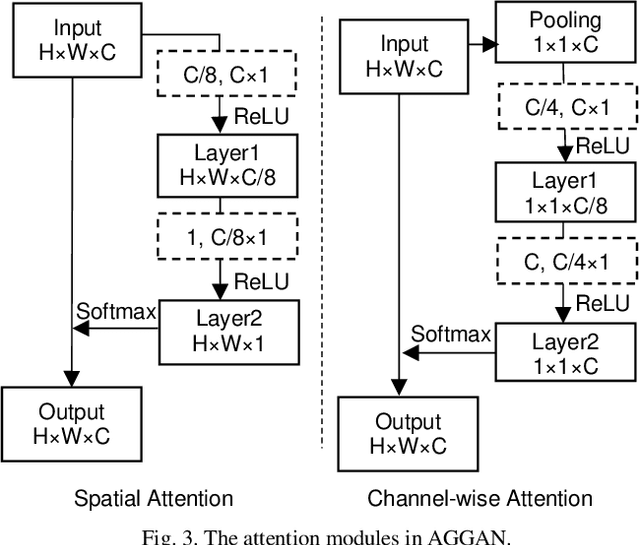
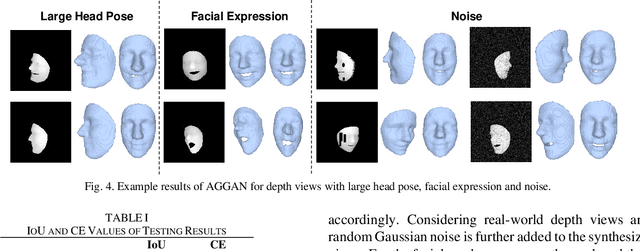
We present to recover the complete 3D facial geometry from a single depth view by proposing an Attention Guided Generative Adversarial Networks (AGGAN). In contrast to existing work which normally requires two or more depth views to recover a full 3D facial geometry, the proposed AGGAN is able to generate a dense 3D voxel grid of the face from a single unconstrained depth view. Specifically, AGGAN encodes the 3D facial geometry within a voxel space and utilizes an attention-guided GAN to model the illposed 2.5D depth-3D mapping. Multiple loss functions, which enforce the 3D facial geometry consistency, together with a prior distribution of facial surface points in voxel space are incorporated to guide the training process. Both qualitative and quantitative comparisons show that AGGAN recovers a more complete and smoother 3D facial shape, with the capability to handle a much wider range of view angles and resist to noise in the depth view than conventional methods
Real-time 3D Facial Tracking via Cascaded Compositional Learning
Sep 02, 2020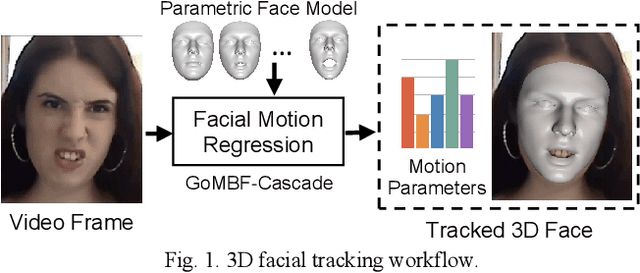
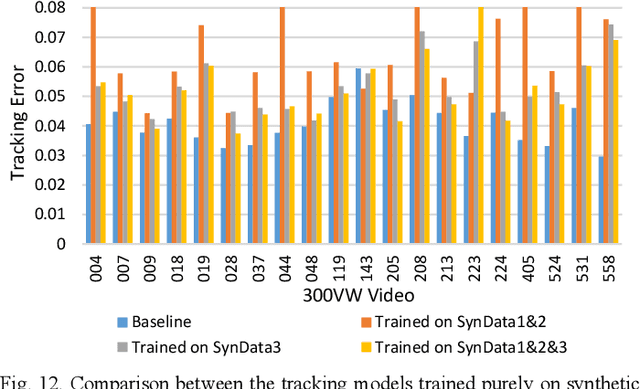
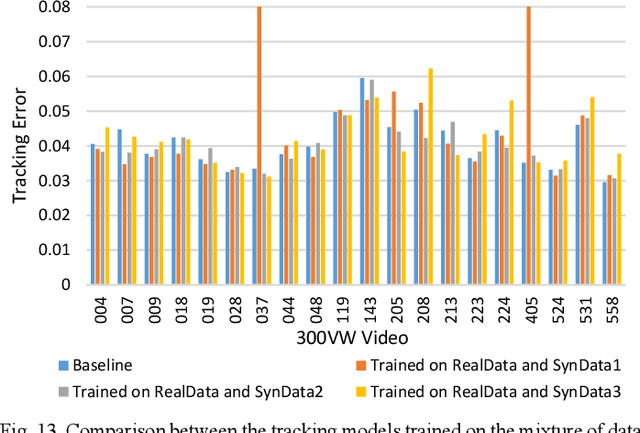
We propose to learn a cascade of globally-optimized modular boosted ferns (GoMBF) to solve multi-modal facial motion regression for real-time 3D facial tracking from a monocular RGB camera. GoMBF is a deep composition of multiple regression models with each is a boosted ferns initially trained to predict partial motion parameters of the same modality, and then concatenated together via a global optimization step to form a singular strong boosted ferns that can effectively handle the whole regression target. It can explicitly cope with the modality variety in output variables, while manifesting increased fitting power and a faster learning speed comparing against the conventional boosted ferns. By further cascading a sequence of GoMBFs (GoMBF-Cascade) to regress facial motion parameters, we achieve competitive tracking performance on a variety of in-the-wild videos comparing to the state-of-the-art methods, which require much more training data or have higher computational complexity. It provides a robust and highly elegant solution to real-time 3D facial tracking using a small set of training data and hence makes it more practical in real-world applications.