 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Matrix Completion with Heavy-tailed Noise
Jun 09, 2022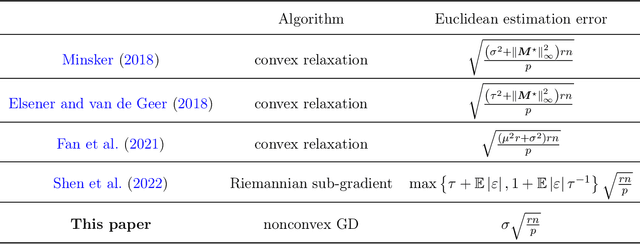
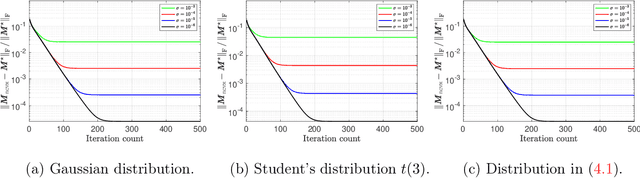
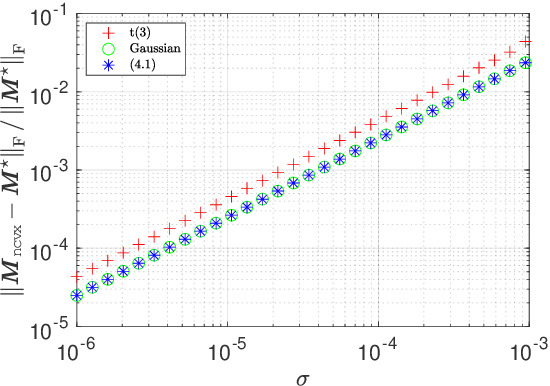
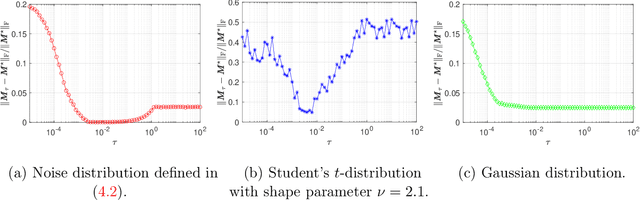
This paper studies low-rank matrix completion in the presence of heavy-tailed and possibly asymmetric noise, where we aim to estimate an underlying low-rank matrix given a set of highly incomplete noisy entries. Though the matrix completion problem has attracted much attention in the past decade, there is still lack of theoretical understanding when the observations are contaminated by heavy-tailed noises. Prior theory falls short of explaining the empirical results and is unable to capture the optimal dependence of the estimation error on the noise level. In this paper, we adopt an adaptive Huber loss to accommodate heavy-tailed noise, which is robust against large and possibly asymmetric errors when the parameter in the loss function is carefully designed to balance the Huberization biases and robustness to outliers. Then, we propose an efficient nonconvex algorithm via a balanced low-rank Burer-Monteiro matrix factorization and gradient decent with robust spectral initialization. We prove that under merely bounded second moment condition on the error distributions, rather than the sub-Gaussian assumption, the Euclidean error of the iterates generated by the proposed algorithm decrease geometrically fast until achieving a minimax-optimal statistical estimation error, which has the same order as that in the sub-Gaussian case. The key technique behind this significant advancement is a powerful leave-one-out analysis framework. The theoretical results are corroborated by our simulation studies.
Model-Based Reinforcement Learning Is Minimax-Optimal for Offline Zero-Sum Markov Games
Jun 08, 2022This paper makes progress towards learning Nash equilibria in two-player zero-sum Markov games from offline data. Specifically, consider a $\gamma$-discounted infinite-horizon Markov game with $S$ states, where the max-player has $A$ actions and the min-player has $B$ actions. We propose a pessimistic model-based algorithm with Bernstein-style lower confidence bounds -- called VI-LCB-Game -- that provably finds an $\varepsilon$-approximate Nash equilibrium with a sample complexity no larger than $\frac{C_{\mathsf{clipped}}^{\star}S(A+B)}{(1-\gamma)^{3}\varepsilon^{2}}$ (up to some log factor). Here, $C_{\mathsf{clipped}}^{\star}$ is some unilateral clipped concentrability coefficient that reflects the coverage and distribution shift of the available data (vis-\`a-vis the target data), and the target accuracy $\varepsilon$ can be any value within $\big(0,\frac{1}{1-\gamma}\big]$. Our sample complexity bound strengthens prior art by a factor of $\min\{A,B\}$, achieving minimax optimality for the entire $\varepsilon$-range. An appealing feature of our result lies in algorithmic simplicity, which reveals the unnecessity of variance reduction and sample splitting in achieving sample optimality.
How do noise tails impact on deep ReLU networks?
Mar 20, 2022

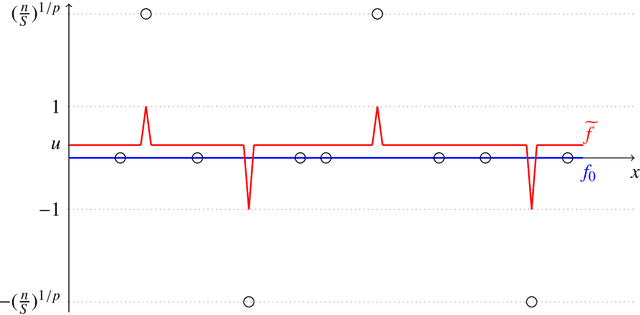
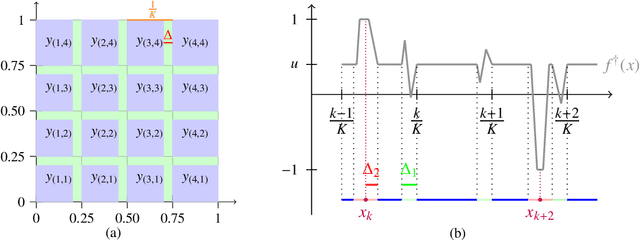
This paper investigates the stability of deep ReLU neural networks for nonparametric regression under the assumption that the noise has only a finite p-th moment. We unveil how the optimal rate of convergence depends on p, the degree of smoothness and the intrinsic dimension in a class of nonparametric regression functions with hierarchical composition structure when both the adaptive Huber loss and deep ReLU neural networks are used. This optimal rate of convergence cannot be obtained by the ordinary least squares but can be achieved by the Huber loss with a properly chosen parameter that adapts to the sample size, smoothness, and moment parameters. A concentration inequality for the adaptive Huber ReLU neural network estimators with allowable optimization errors is also derived. To establish a matching lower bound within the class of neural network estimators using the Huber loss, we employ a different strategy from the traditional route: constructing a deep ReLU network estimator that has a better empirical loss than the true function and the difference between these two functions furnishes a low bound. This step is related to the Huberization bias, yet more critically to the approximability of deep ReLU networks. As a result, we also contribute some new results on the approximation theory of deep ReLU neural networks.
The Efficacy of Pessimism in Asynchronous Q-Learning
Mar 14, 2022This paper is concerned with the asynchronous form of Q-learning, which applies a stochastic approximation scheme to Markovian data samples. Motivated by the recent advances in offline reinforcement learning, we develop an algorithmic framework that incorporates the principle of pessimism into asynchronous Q-learning, which penalizes infrequently-visited state-action pairs based on suitable lower confidence bounds (LCBs). This framework leads to, among other things, improved sample efficiency and enhanced adaptivity in the presence of near-expert data. Our approach permits the observed data in some important scenarios to cover only partial state-action space, which is in stark contrast to prior theory that requires uniform coverage of all state-action pairs. When coupled with the idea of variance reduction, asynchronous Q-learning with LCB penalization achieves near-optimal sample complexity, provided that the target accuracy level is small enough. In comparison, prior works were suboptimal in terms of the dependency on the effective horizon even when i.i.d. sampling is permitted. Our results deliver the first theoretical support for the use of pessimism principle in the presence of Markovian non-i.i.d. data.
Are Latent Factor Regression and Sparse Regression Adequate?
Mar 02, 2022
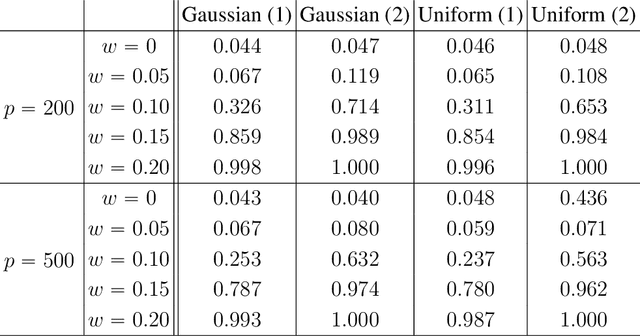
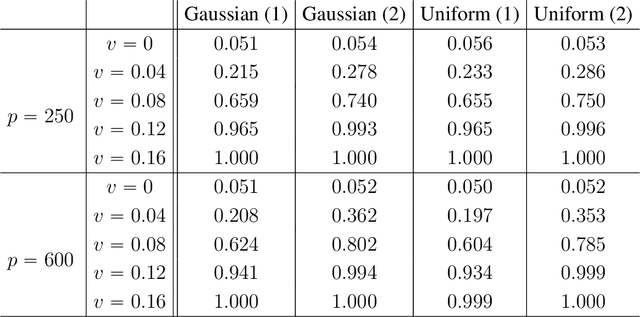
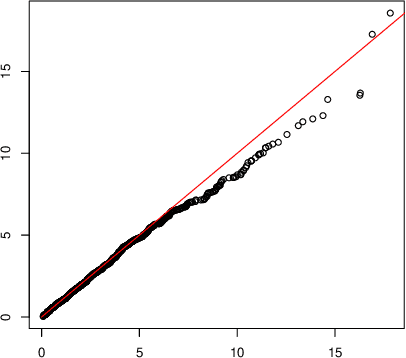
We propose the Factor Augmented sparse linear Regression Model (FARM) that not only encompasses both the latent factor regression and sparse linear regression as special cases but also bridges dimension reduction and sparse regression together. We provide theoretical guarantees for the estimation of our model under the existence of sub-Gaussian and heavy-tailed noises (with bounded (1+x)-th moment, for all x>0), respectively. In addition, the existing works on supervised learning often assume the latent factor regression or the sparse linear regression is the true underlying model without justifying its adequacy. To fill in such an important gap, we also leverage our model as the alternative model to test the sufficiency of the latent factor regression and the sparse linear regression models. To accomplish these goals, we propose the Factor-Adjusted de-Biased Test (FabTest) and a two-stage ANOVA type test respectively. We also conduct large-scale numerical experiments including both synthetic and FRED macroeconomics data to corroborate the theoretical properties of our methods. Numerical results illustrate the robustness and effectiveness of our model against latent factor regression and sparse linear regression models.
Curriculum Learning for Vision-and-Language Navigation
Nov 14, 2021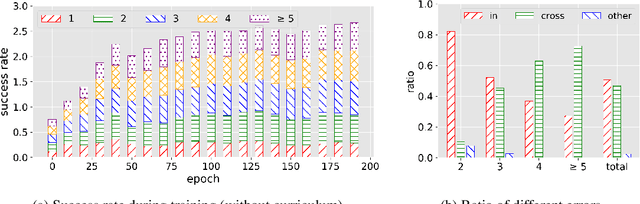
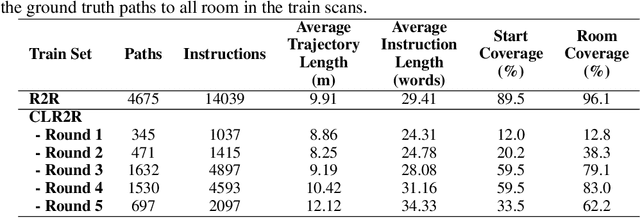


Vision-and-Language Navigation (VLN) is a task where an agent navigates in an embodied indoor environment under human instructions. Previous works ignore the distribution of sample difficulty and we argue that this potentially degrade their agent performance. To tackle this issue, we propose a novel curriculum-based training paradigm for VLN tasks that can balance human prior knowledge and agent learning progress about training samples. We develop the principle of curriculum design and re-arrange the benchmark Room-to-Room (R2R) dataset to make it suitable for curriculum training. Experiments show that our method is model-agnostic and can significantly improve the performance, the generalizability, and the training efficiency of current state-of-the-art navigation agents without increasing model complexity.
Negative Sample is Negative in Its Own Way: Tailoring Negative Sentences for Image-Text Retrieval
Nov 05, 2021
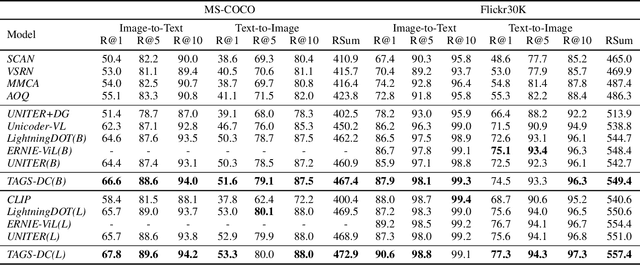

Matching model is essential for Image-Text Retrieval framework. Existing research usually train the model with a triplet loss and explore various strategy to retrieve hard negative sentences in the dataset. We argue that current retrieval-based negative sample construction approach is limited in the scale of the dataset thus fail to identify negative sample of high difficulty for every image. We propose our TAiloring neGative Sentences with Discrimination and Correction (TAGS-DC) to generate synthetic sentences automatically as negative samples. TAGS-DC is composed of masking and refilling to generate synthetic negative sentences with higher difficulty. To keep the difficulty during training, we mutually improve the retrieval and generation through parameter sharing. To further utilize fine-grained semantic of mismatch in the negative sentence, we propose two auxiliary tasks, namely word discrimination and word correction to improve the training. In experiments, we verify the effectiveness of our model on MS-COCO and Flickr30K compared with current state-of-the-art models and demonstrates its robustness and faithfulness in the further analysis. Our code is available in https://github.com/LibertFan/TAGS.
Policy Optimization Using Semiparametric Models for Dynamic Pricing
Sep 13, 2021In this paper, we study the contextual dynamic pricing problem where the market value of a product is linear in its observed features plus some market noise. Products are sold one at a time, and only a binary response indicating success or failure of a sale is observed. Our model setting is similar to Javanmard and Nazerzadeh [2019] except that we expand the demand curve to a semiparametric model and need to learn dynamically both parametric and nonparametric components. We propose a dynamic statistical learning and decision-making policy that combines semiparametric estimation from a generalized linear model with an unknown link and online decision-making to minimize regret (maximize revenue). Under mild conditions, we show that for a market noise c.d.f. $F(\cdot)$ with $m$-th order derivative ($m\geq 2$), our policy achieves a regret upper bound of $\tilde{O}_{d}(T^{\frac{2m+1}{4m-1}})$, where $T$ is time horizon and $\tilde{O}_{d}$ is the order that hides logarithmic terms and the dimensionality of feature $d$. The upper bound is further reduced to $\tilde{O}_{d}(\sqrt{T})$ if $F$ is super smooth whose Fourier transform decays exponentially. In terms of dependence on the horizon $T$, these upper bounds are close to $\Omega(\sqrt{T})$, the lower bound where $F$ belongs to a parametric class. We further generalize these results to the case with dynamically dependent product features under the strong mixing condition.
Constructing Phrase-level Semantic Labels to Form Multi-Grained Supervision for Image-Text Retrieval
Sep 12, 2021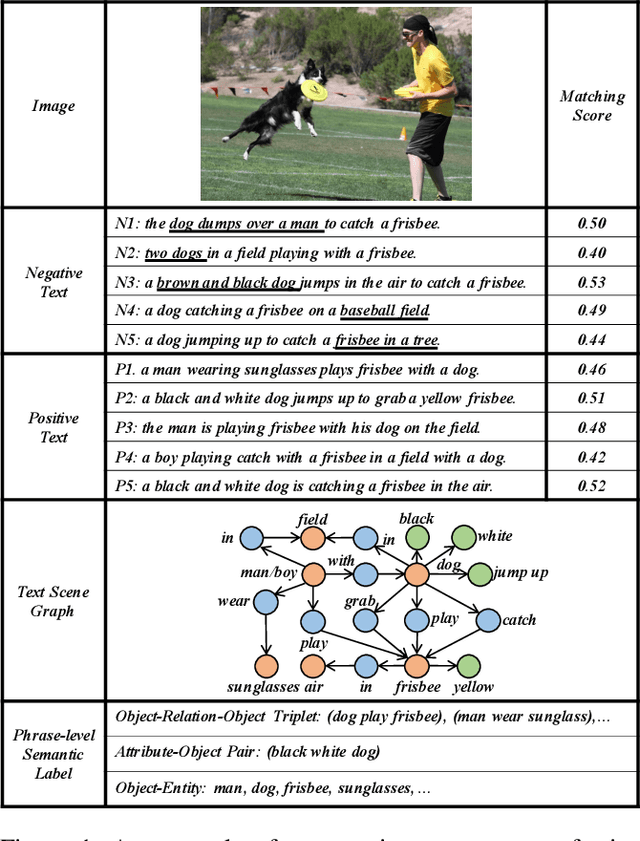
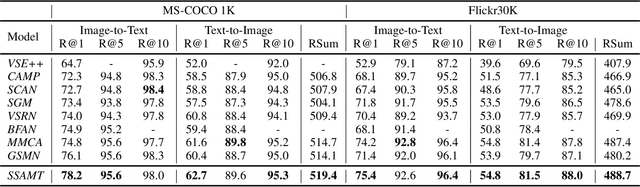
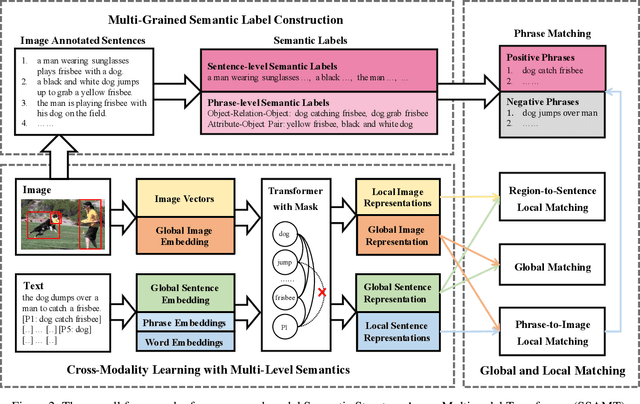
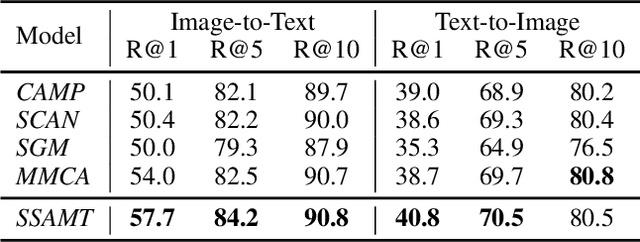
Existing research for image text retrieval mainly relies on sentence-level supervision to distinguish matched and mismatched sentences for a query image. However, semantic mismatch between an image and sentences usually happens in finer grain, i.e., phrase level. In this paper, we explore to introduce additional phrase-level supervision for the better identification of mismatched units in the text. In practice, multi-grained semantic labels are automatically constructed for a query image in both sentence-level and phrase-level. We construct text scene graphs for the matched sentences and extract entities and triples as the phrase-level labels. In order to integrate both supervision of sentence-level and phrase-level, we propose Semantic Structure Aware Multimodal Transformer (SSAMT) for multi-modal representation learning. Inside the SSAMT, we utilize different kinds of attention mechanisms to enforce interactions of multi-grain semantic units in both sides of vision and language. For the training, we propose multi-scale matching losses from both global and local perspectives, and penalize mismatched phrases. Experimental results on MS-COCO and Flickr30K show the effectiveness of our approach compared to some state-of-the-art models.
Inference for Heteroskedastic PCA with Missing Data
Jul 26, 2021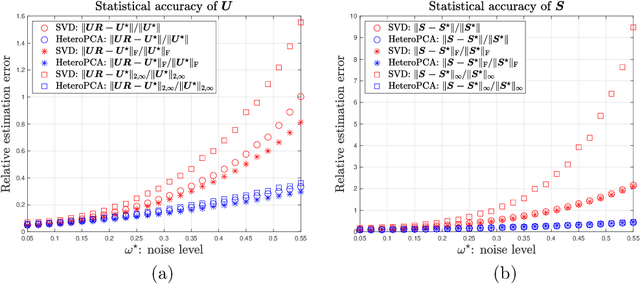
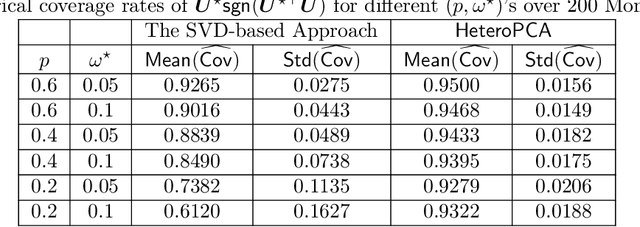
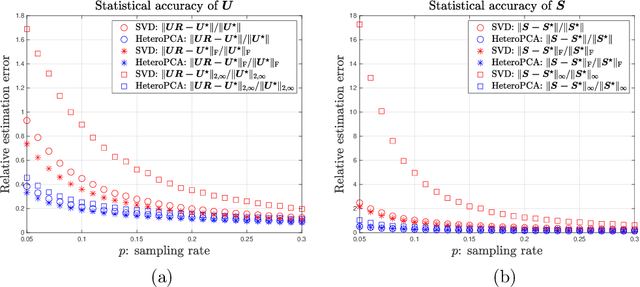
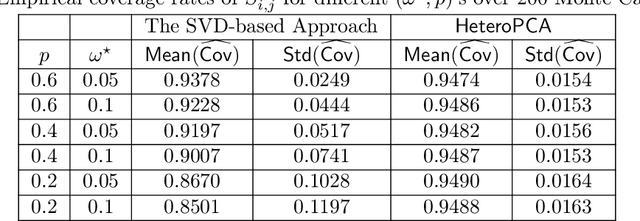
This paper studies how to construct confidence regions for principal component analysis (PCA) in high dimension, a problem that has been vastly under-explored. While computing measures of uncertainty for nonlinear/nonconvex estimators is in general difficult in high dimension, the challenge is further compounded by the prevalent presence of missing data and heteroskedastic noise. We propose a suite of solutions to perform valid inference on the principal subspace based on two estimators: a vanilla SVD-based approach, and a more refined iterative scheme called $\textsf{HeteroPCA}$ (Zhang et al., 2018). We develop non-asymptotic distributional guarantees for both estimators, and demonstrate how these can be invoked to compute both confidence regions for the principal subspace and entrywise confidence intervals for the spiked covariance matrix. Particularly worth highlighting is the inference procedure built on top of $\textsf{HeteroPCA}$, which is not only valid but also statistically efficient for broader scenarios (e.g., it covers a wider range of missing rates and signal-to-noise ratios). Our solutions are fully data-driven and adaptive to heteroskedastic random noise, without requiring prior knowledge about the noise levels and noise distributions.