 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Learning of Kalman Filtering: From Output to State Estimation
Mar 28, 2026In this paper, we study the problem of learning Kalman filtering with unknown system model in partially observed linear dynamical systems. We propose a unified algorithmic framework based on online optimization that can be used to solve both the output estimation and state estimation scenarios. By exploring the properties of the estimation error cost functions, such as conditionally strong convexity, we show that our algorithm achieves a $\log T$-regret in the horizon length $T$ for the output estimation scenario. More importantly, we tackle the more challenging scenario of learning Kalman filtering for state estimation, which is an open problem in the literature. We first characterize a fundamental limitation of the problem, demonstrating the impossibility of any algorithm to achieve sublinear regret in $T$. By further introducing a random query scheme into our algorithm, we show that a $\sqrt{T}$-regret is achievable when rendering the algorithm limited query access to more informative measurements of the system state in practice. Our algorithm and regret readily capture the trade-off between the number of queries and the achieved regret, and shed light on online learning problems with limited observations. We validate the performance of our algorithms using numerical examples.
Simulation Studies on Deep Reinforcement Learning for Building Control with Human Interaction
Mar 14, 2021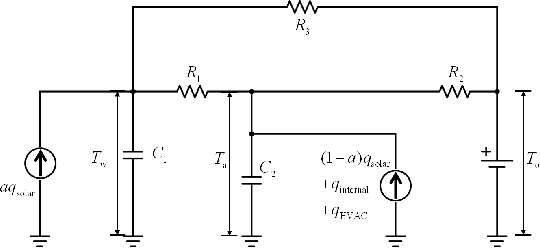
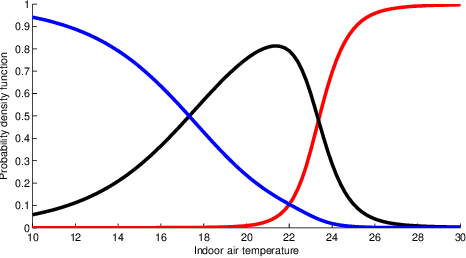
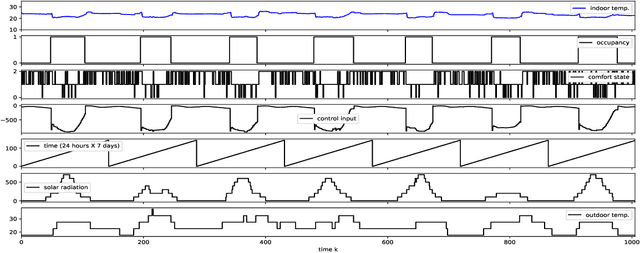
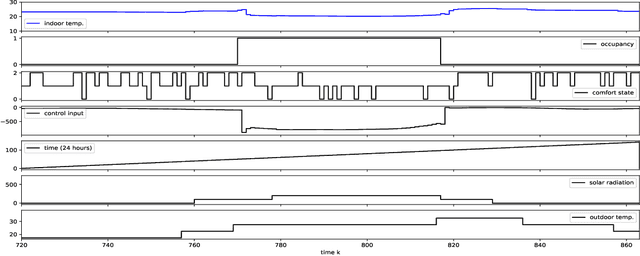
The building sector consumes the largest energy in the world, and there have been considerable research interests in energy consumption and comfort management of buildings. Inspired by recent advances in reinforcement learning (RL), this paper aims at assessing the potential of RL in building climate control problems with occupant interaction. We apply a recent RL approach, called DDPG (deep deterministic policy gradient), for the continuous building control tasks and assess its performance with simulation studies in terms of its ability to handle (a) the partial state observability due to sensor limitations; (b) complex stochastic system with high-dimensional state-spaces, which are jointly continuous and discrete; (c) uncertainties due to ambient weather conditions, occupant's behavior, and comfort feelings. Especially, the partial observability and uncertainty due to the occupant interaction significantly complicate the control problem. Through simulation studies, the policy learned by DDPG demonstrates reasonable performance and computational tractability.