 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIND: From Passive Mimicry to Active Reasoning through Capability-Aware Multi-Perspective CoT Distillation
Jan 07, 2026While Large Language Models (LLMs) have emerged with remarkable capabilities in complex tasks through Chain-of-Thought reasoning, practical resource constraints have sparked interest in transferring these abilities to smaller models. However, achieving both domain performance and cross-domain generalization remains challenging. Existing approaches typically restrict students to following a single golden rationale and treat different reasoning paths independently. Due to distinct inductive biases and intrinsic preferences, alongside the student's evolving capacity and reasoning preferences during training, a teacher's "optimal" rationale could act as out-of-distribution noise. This misalignment leads to a degeneration of the student's latent reasoning distribution, causing suboptimal performance. To bridge this gap, we propose MIND, a capability-adaptive framework that transitions distillation from passive mimicry to active cognitive construction. We synthesize diverse teacher perspectives through a novel "Teaching Assistant" network. By employing a Feedback-Driven Inertia Calibration mechanism, this network utilizes inertia-filtered training loss to align supervision with the student's current adaptability, effectively enhancing performance while mitigating catastrophic forgetting. Extensive experiments demonstrate that MIND achieves state-of-the-art performance on both in-distribution and out-of-distribution benchmarks, and our sophisticated latent space analysis further confirms the mechanism of reasoning ability internalization.
DeepKD: A Deeply Decoupled and Denoised Knowledge Distillation Trainer
May 21, 2025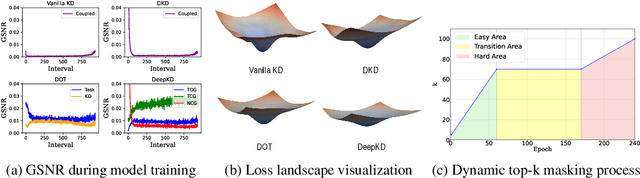
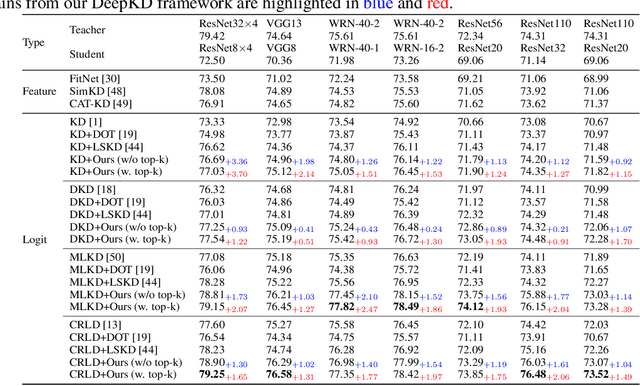
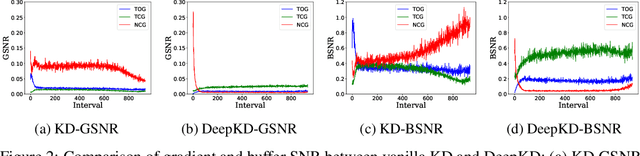
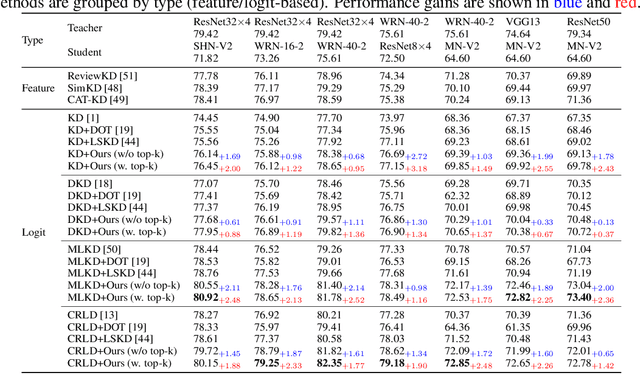
Recent advances in knowledge distillation have emphasized the importance of decoupling different knowledge components. While existing methods utilize momentum mechanisms to separate task-oriented and distillation gradients, they overlook the inherent conflict between target-class and non-target-class knowledge flows. Furthermore, low-confidence dark knowledge in non-target classes introduces noisy signals that hinder effective knowledge transfer. To address these limitations, we propose DeepKD, a novel training framework that integrates dual-level decoupling with adaptive denoising. First, through theoretical analysis of gradient signal-to-noise ratio (GSNR) characteristics in task-oriented and non-task-oriented knowledge distillation, we design independent momentum updaters for each component to prevent mutual interference. We observe that the optimal momentum coefficients for task-oriented gradient (TOG), target-class gradient (TCG), and non-target-class gradient (NCG) should be positively related to their GSNR. Second, we introduce a dynamic top-k mask (DTM) mechanism that gradually increases K from a small initial value to incorporate more non-target classes as training progresses, following curriculum learning principles. The DTM jointly filters low-confidence logits from both teacher and student models, effectively purifying dark knowledge during early training. Extensive experiments on CIFAR-100, ImageNet, and MS-COCO demonstrate DeepKD's effectiveness. Our code is available at https://github.com/haiduo/DeepKD.