 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDADA: A Large-scale Benchmark and Model for Driver Attention Prediction in Accidental Scenarios
Dec 18, 2019


Driver attention prediction has recently absorbed increasing attention in traffic scene understanding and is prone to be an essential problem in vision-centered and human-like driving systems. This work, different from other attempts, makes an attempt to predict the driver attention in accidental scenarios containing normal, critical and accidental situations simultaneously. However, challenges tread on the heels of that because of the dynamic traffic scene, intricate and imbalanced accident categories. With the hypothesis that driver attention can provide a selective role of crash-object for assisting driving accident detection or prediction, this paper designs a multi-path semantic-guided attentive fusion network (MSAFNet) that learns the spatio-temporal semantic and scene variation in prediction. For fulfilling this, a large-scale benchmark with 2000 video sequences (named as DADA-2000) is contributed with laborious annotation for driver attention (fixation, saccade, focusing time), accident objects/intervals, as well as the accident categories, and superior performance to state-of-the-arts are provided by thorough evaluations. As far as we know, this is the first comprehensive and quantitative study for the human-eye sensing exploration in accidental scenarios. DADA-2000 is available at https://github.com/JWFangit/LOTVS-DADA.
DADA-2000: Can Driving Accident be Predicted by Driver Attention? Analyzed by A Benchmark
Apr 23, 2019

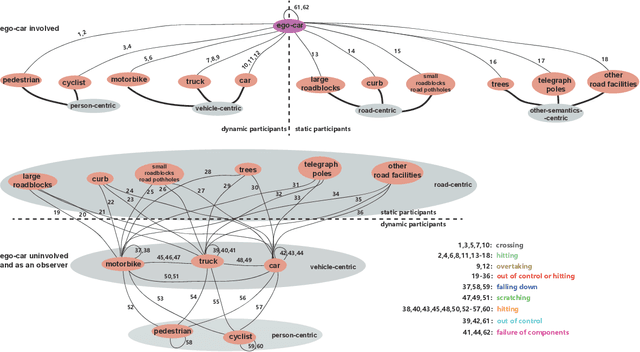
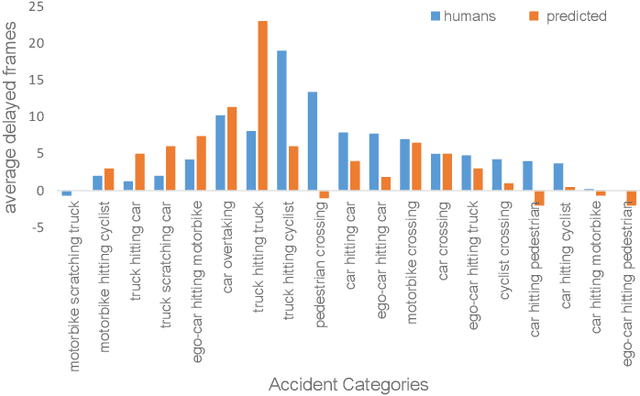
Driver attention prediction is currently becoming the focus in safe driving research community, such as the DR(eye)VE project and newly emerged Berkeley DeepDrive Attention (BDD-A) database in critical situations. In safe driving, an essential task is to predict the incoming accidents as early as possible. BDD-A was aware of this problem and collected the driver attention in laboratory because of the rarity of such scenes. Nevertheless, BDD-A focuses the critical situations which do not encounter actual accidents, and just faces the driver attention prediction task, without a close step for accident prediction. In contrast to this, we explore the view of drivers' eyes for capturing multiple kinds of accidents, and construct a more diverse and larger video benchmark than ever before with the driver attention and the driving accident annotation simultaneously (named as DADA-2000), which has 2000 video clips owning about 658,476 frames on 54 kinds of accidents. These clips are crowd-sourced and captured in various occasions (highway, urban, rural, and tunnel), weather (sunny, rainy and snowy) and light conditions (daytime and nighttime). For the driver attention representation, we collect the maps of fixations, saccade scan path and focusing time. The accidents are annotated by their categories, the accident window in clips and spatial locations of the crash-objects. Based on the analysis, we obtain a quantitative and positive answer for the question in this paper.