 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept-based model explanations for Electronic Health Records
Dec 03, 2020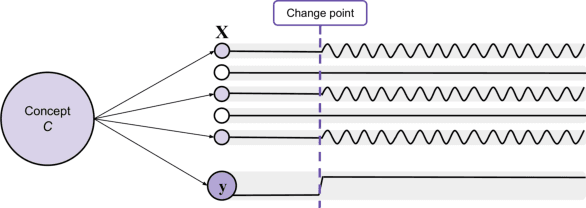
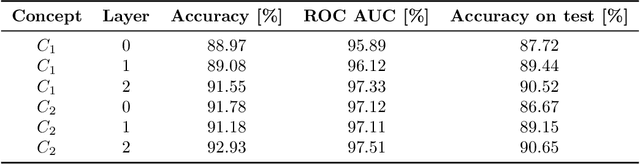
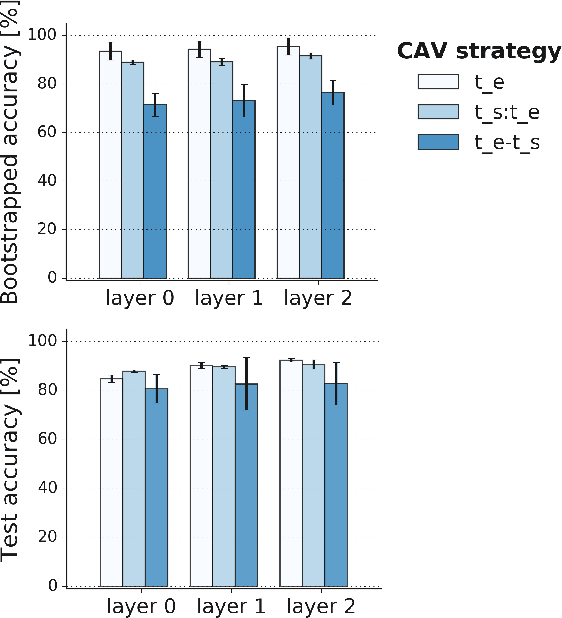
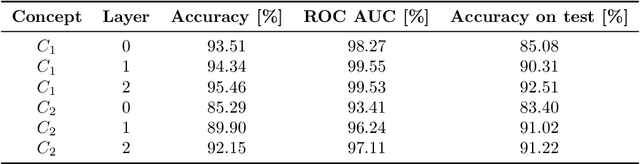
Recurrent Neural Networks (RNNs) are often used for sequential modeling of adverse outcomes in electronic health records (EHRs) due to their ability to encode past clinical states. These deep, recurrent architectures have displayed increased performance compared to other modeling approaches in a number of tasks, fueling the interest in deploying deep models in clinical settings. One of the key elements in ensuring safe model deployment and building user trust is model explainability. Testing with Concept Activation Vectors (TCAV) has recently been introduced as a way of providing human-understandable explanations by comparing high-level concepts to the network's gradients. While the technique has shown promising results in real-world imaging applications, it has not been applied to structured temporal inputs. To enable an application of TCAV to sequential predictions in the EHR, we propose an extension of the method to time series data. We evaluate the proposed approach on an open EHR benchmark from the intensive care unit, as well as synthetic data where we are able to better isolate individual effects.
Underspecification Presents Challenges for Credibility in Modern Machine Learning
Nov 06, 2020


ML models often exhibit unexpectedly poor behavior when they are deployed in real-world domains. We identify underspecification as a key reason for these failures. An ML pipeline is underspecified when it can return many predictors with equivalently strong held-out performance in the training domain. Underspecification is common in modern ML pipelines, such as those based on deep learning. Predictors returned by underspecified pipelines are often treated as equivalent based on their training domain performance, but we show here that such predictors can behave very differently in deployment domains. This ambiguity can lead to instability and poor model behavior in practice, and is a distinct failure mode from previously identified issues arising from structural mismatch between training and deployment domains. We show that this problem appears in a wide variety of practical ML pipelines, using examples from computer vision, medical imaging, natural language processing, clinical risk prediction based on electronic health records, and medical genomics. Our results show the need to explicitly account for underspecification in modeling pipelines that are intended for real-world deployment in any domain.
Inferring Javascript types using Graph Neural Networks
May 16, 2019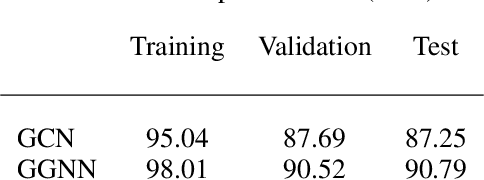
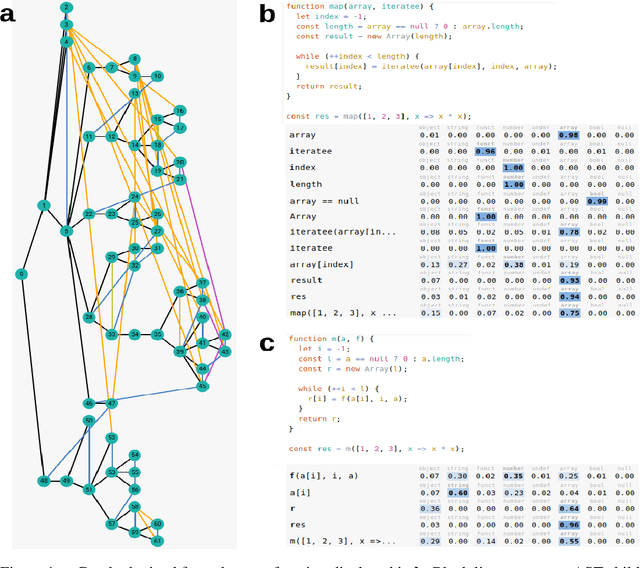
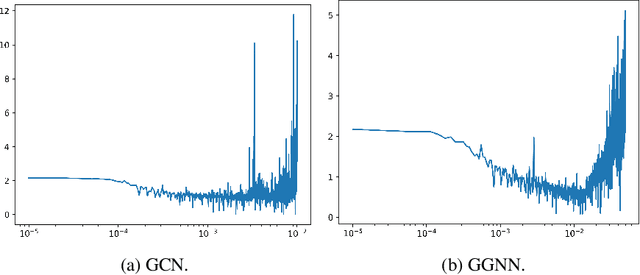
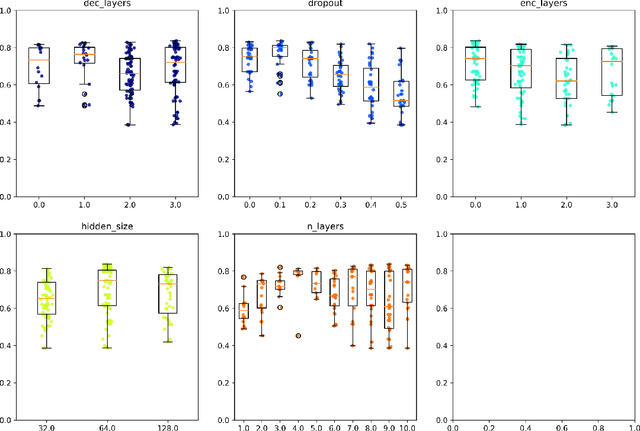
The recent use of `Big Code' with state-of-the-art deep learning methods offers promising avenues to ease program source code writing and correction. As a first step towards automatic code repair, we implemented a graph neural network model that predicts token types for Javascript programs. The predictions achieve an accuracy above $90\%$, which improves on previous similar work.
Interpreting weight maps in terms of cognitive or clinical neuroscience: nonsense?
Apr 30, 2018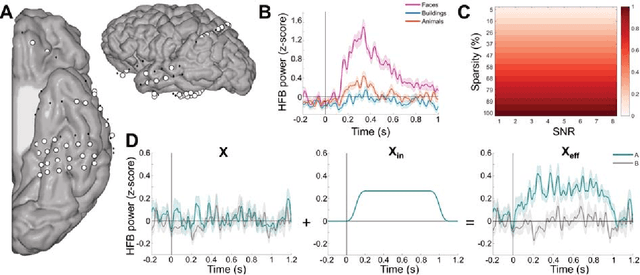
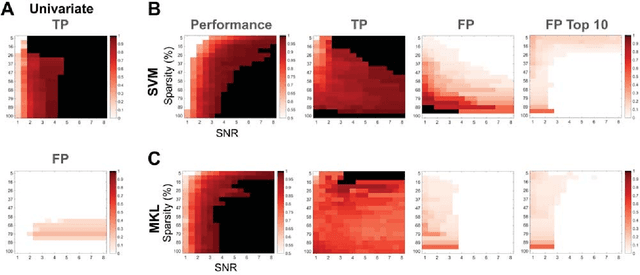
Since machine learning models have been applied to neuroimaging data, researchers have drawn conclusions from the derived weight maps. In particular, weight maps of classifiers between two conditions are often described as a proxy for the underlying signal differences between the conditions. Recent studies have however suggested that such weight maps could not reliably recover the source of the neural signals and even led to false positives (FP). In this work, we used semi-simulated data from ElectroCorticoGraphy (ECoG) to investigate how the signal-to-noise ratio and sparsity of the neural signal affect the similarity between signal and weights. We show that not all cases produce FP and that it is unlikely for FP features to have a high weight in most cases.
* conference article