 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColor Names in Vision-Language Models
Sep 26, 2025Color serves as a fundamental dimension of human visual perception and a primary means of communicating about objects and scenes. As vision-language models (VLMs) become increasingly prevalent, understanding whether they name colors like humans is crucial for effective human-AI interaction. We present the first systematic evaluation of color naming capabilities across VLMs, replicating classic color naming methodologies using 957 color samples across five representative models. Our results show that while VLMs achieve high accuracy on prototypical colors from classical studies, performance drops significantly on expanded, non-prototypical color sets. We identify 21 common color terms that consistently emerge across all models, revealing two distinct approaches: constrained models using predominantly basic terms versus expansive models employing systematic lightness modifiers. Cross-linguistic analysis across nine languages demonstrates severe training imbalances favoring English and Chinese, with hue serving as the primary driver of color naming decisions. Finally, ablation studies reveal that language model architecture significantly influences color naming independent of visual processing capabilities.
Contrast Sensitivity Function of Multimodal Vision-Language Models
Aug 14, 2025Assessing the alignment of multimodal vision-language models~(VLMs) with human perception is essential to understand how they perceive low-level visual features. A key characteristic of human vision is the contrast sensitivity function (CSF), which describes sensitivity to spatial frequency at low-contrasts. Here, we introduce a novel behavioral psychophysics-inspired method to estimate the CSF of chat-based VLMs by directly prompting them to judge pattern visibility at different contrasts for each frequency. This methodology is closer to the real experiments in psychophysics than the previously reported. Using band-pass filtered noise images and a diverse set of prompts, we assess model responses across multiple architectures. We find that while some models approximate human-like CSF shape or magnitude, none fully replicate both. Notably, prompt phrasing has a large effect on the responses, raising concerns about prompt stability. Our results provide a new framework for probing visual sensitivity in multimodal models and reveal key gaps between their visual representations and human perception.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Parametric Enhancement of PerceptNet: A Human-Inspired Approach for Image Quality Assessment
Dec 04, 2024



While deep learning models can learn human-like features at earlier levels, which suggests their utility in modeling human vision, few attempts exist to incorporate these features by design. Current approaches mostly optimize all parameters blindly, only constraining minor architectural aspects. This paper demonstrates how parametrizing neural network layers enables more biologically-plausible operations while reducing trainable parameters and improving interpretability. We constrain operations to functional forms present in human vision, optimizing only these functions' parameters rather than all convolutional tensor elements independently. We present two parametric model versions: one with hand-chosen biologically plausible parameters, and another fitted to human perception experimental data. We compare these with a non-parametric version. All models achieve comparable state-of-the-art results, with parametric versions showing orders of magnitude parameter reduction for minimal performance loss. The parametric models demonstrate improved interpretability and training behavior. Notably, the model fitted to human perception, despite biological initialization, converges to biologically incorrect results. This raises scientific questions and highlights the need for diverse evaluation methods to measure models' humanness, rather than assuming task performance correlates with human-like behavior.
Image Segmentation via Divisive Normalization: dealing with environmental diversity
Jul 25, 2024



Autonomous driving is a challenging scenario for image segmentation due to the presence of uncontrolled environmental conditions and the eventually catastrophic consequences of failures. Previous work suggested that a biologically motivated computation, the so-called Divisive Normalization, could be useful to deal with image variability, but its effects have not been systematically studied over different data sources and environmental factors. Here we put segmentation U-nets augmented with Divisive Normalization to work far from training conditions to find where this adaptation is more critical. We categorize the scenes according to their radiance level and dynamic range (day/night), and according to their achromatic/chromatic contrasts. We also consider video game (synthetic) images to broaden the range of environments. We check the performance in the extreme percentiles of such categorization. Then, we push the limits further by artificially modifying the images in perceptually/environmentally relevant dimensions: luminance, contrasts and spectral radiance. Results show that neural networks with Divisive Normalization get better results in all the scenarios and their performance remains more stable with regard to the considered environmental factors and nature of the source. Finally, we explain the improvements in segmentation performance in two ways: (1) by quantifying the invariance of the responses that incorporate Divisive Normalization, and (2) by illustrating the adaptive nonlinearity of the different layers that depends on the local activity.
Analysis of Deep Image Quality Models
Feb 26, 2023



Subjective image quality measures based on deep neural networks are very related to models of visual neuroscience. This connection benefits engineering but, more interestingly, the freedom to optimize deep networks in different ways, make them an excellent tool to explore the principles behind visual perception (both human and artificial). Recently, a myriad of networks have been successfully optimized for many interesting visual tasks. Although these nets were not specifically designed to predict image quality or other psychophysics, they have shown surprising human-like behavior. The reasons for this remain unclear. In this work, we perform a thorough analysis of the perceptual properties of pre-trained nets (particularly their ability to predict image quality) by isolating different factors: the goal (the function), the data (learning environment), the architecture, and the readout: selected layer(s), fine-tuning of channel relevance, and use of statistical descriptors as opposed to plain readout of responses. Several conclusions can be drawn. All the models correlate better with human opinion than SSIM. More importantly, some of the nets are in pair of state-of-the-art with no extra refinement or perceptual information. Nets trained for supervised tasks such as classification correlate substantially better with humans than LPIPS (a net specifically tuned for image quality). Interestingly, self-supervised tasks such as jigsaw also perform better than LPIPS. Simpler architectures are better than very deep nets. In simpler nets, correlation with humans increases with depth as if deeper layers were closer to human judgement. This is not true in very deep nets. Consistently with reports on illusions and contrast sensitivity, small changes in the image environment does not make a big difference. Finally, the explored statistical descriptors and concatenations had no major impact.
Neural Networks with Divisive normalization for image segmentation with application in cityscapes dataset
Mar 25, 2022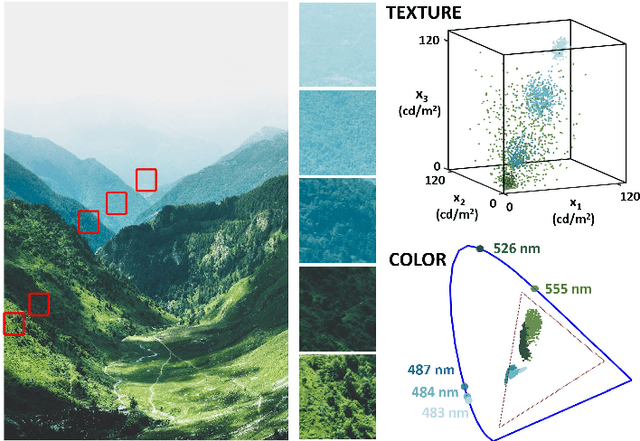
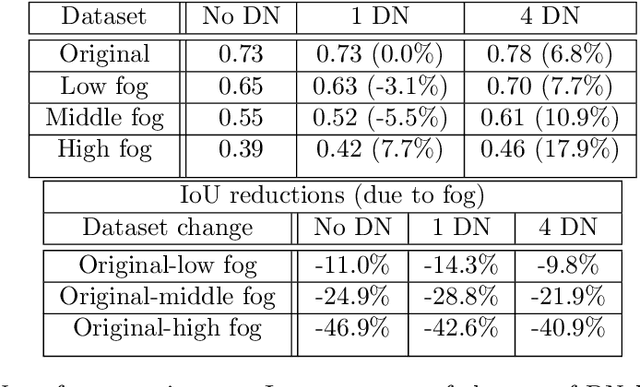

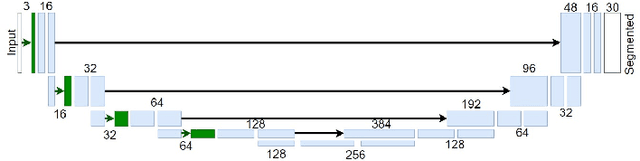
One of the key problems in computer vision is adaptation: models are too rigid to follow the variability of the inputs. The canonical computation that explains adaptation in sensory neuroscience is divisive normalization, and it has appealing effects on image manifolds. In this work we show that including divisive normalization in current deep networks makes them more invariant to non-informative changes in the images. In particular, we focus on U-Net architectures for image segmentation. Experiments show that the inclusion of divisive normalization in the U-Net architecture leads to better segmentation results with respect to conventional U-Net. The gain increases steadily when dealing with images acquired in bad weather conditions. In addition to the results on the Cityscapes and Foggy Cityscapes datasets, we explain these advantages through visualization of the responses: the equalization induced by the divisive normalization leads to more invariant features to local changes in contrast and illumination.