 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADP: Adversarial Dynamics Priors for Physically Grounded Humanoid Locomotion
Jul 03, 2026In this paper, we propose Adversarial Dynamics Priors (ADP) for perturbation-resilient humanoid locomotion control. Existing motion prior-based methods induce natural motion styles by imitating kinematic motion features, but they do not directly regularize dynamics features, such as CoM motion, centroidal momentum, contact forces, and contact states. To address this limitation, we replace kinematic motion-style feature with selected dynamics features extracted from locomotion trajectories as the target of adversarial regularization.To this end, we use trajectory optimization to construct a reference dataset and train a discriminator to evaluate whether policy-induced temporal windows are consistent with the resulting reference distribution.Without explicit motion tracking, ADP encourages policy rollouts to remain close to the reference support, even after perturbations. Experimental results show that, compared with AMP, the strongest baseline in our evaluation, ADP improves the $80\%$-success impulse threshold ($J_{80}$) by $16.7\%$, while reducing direction-averaged recovery time and velocity tracking error by $47.9\%$ and $35.4\%$, respectively.
PrefillShare: A Shared Prefill Module for KV Reuse in Multi-LLM Disaggregated Serving
Feb 12, 2026Multi-agent systems increasingly orchestrate multiple specialized language models to solve complex real-world problems, often invoking them over a shared context. This execution pattern repeatedly processes the same prompt prefix across models. Consequently, each model redundantly executes the prefill stage and maintains its own key-value (KV) cache, increasing aggregate prefill load and worsening tail latency by intensifying prefill-decode interference in existing LLM serving stacks. Disaggregated serving reduces such interference by placing prefill and decode on separate GPUs, but disaggregation does not fundamentally eliminate inter-model redundancy in computation and KV storage for the same prompt. To address this issue, we propose PrefillShare, a novel algorithm that enables sharing the prefill stage across multiple models in a disaggregated setting. PrefillShare factorizes the model into prefill and decode modules, freezes the prefill module, and fine-tunes only the decode module. This design allows multiple task-specific models to share a prefill module and the KV cache generated for the same prompt. We further introduce a routing mechanism that enables effective prefill sharing across heterogeneous models in a vLLM-based disaggregated system. PrefillShare not only matches full fine-tuning accuracy on a broad range of tasks and models, but also delivers 4.5x lower p95 latency and 3.9x higher throughput in multi-model agent workloads.
Lifelong Learning with Dynamically Expandable Networks
Jun 11, 2018
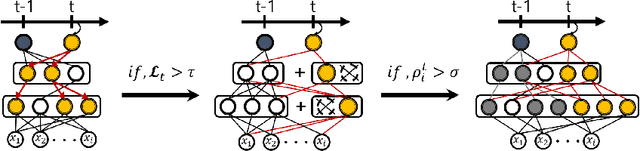


We propose a novel deep network architecture for lifelong learning which we refer to as Dynamically Expandable Network (DEN), that can dynamically decide its network capacity as it trains on a sequence of tasks, to learn a compact overlapping knowledge sharing structure among tasks. DEN is efficiently trained in an online manner by performing selective retraining, dynamically expands network capacity upon arrival of each task with only the necessary number of units, and effectively prevents semantic drift by splitting/duplicating units and timestamping them. We validate DEN on multiple public datasets under lifelong learning scenarios, on which it not only significantly outperforms existing lifelong learning methods for deep networks, but also achieves the same level of performance as the batch counterparts with substantially fewer number of parameters. Further, the obtained network fine-tuned on all tasks obtained significantly better performance over the batch models, which shows that it can be used to estimate the optimal network structure even when all tasks are available in the first place.