 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThrough the Looking-Glass: AI-Mediated Video Communication Reduces Interpersonal Trust and Confidence in Judgments
Mar 19, 2026AI-based tools that mediate, enhance or generate parts of video communication may interfere with how people evaluate trustworthiness and credibility. In two preregistered online experiments (N = 2,000), we examined whether AI-mediated video retouching, background replacement and avatars affect interpersonal trust, people's ability to detect lies and confidence in their judgments. Participants watched short videos of speakers making truthful or deceptive statements across three conditions with varying levels of AI mediation. We observed that perceived trust and confidence in judgments declined in AI-mediated videos, particularly in settings in which some participants used avatars while others did not. However, participants' actual judgment accuracy remained unchanged, and they were no more inclined to suspect those using AI tools of lying. Our findings provide evidence against concerns that AI mediation undermines people's ability to distinguish truth from lies, and against cue-based accounts of lie detection more generally. They highlight the importance of trustworthy AI mediation tools in contexts where not only truth, but also trust and confidence matter.
Reactive Writers: How Co-Writing with AI Changes How We Engage with Ideas
Mar 11, 2026Emerging experimental evidence shows that writing with AI assistance can change both the views people express in writing and the opinions they hold afterwards. Yet, we lack substantive understanding of procedural and behavioral changes in co-writing with AI that underlie the observed opinion-shaping power of AI writing tools. We conducted a mixed-methods study, combining retrospective interviews with 19 participants about their AI co-writing experience with a quantitative analysis tracing engagement with ideas and opinions in 1{,}291 AI co-writing sessions. Our analysis shows that engaging with the AI's suggestions -- reading them and deciding whether to accept them -- becomes a central activity in the writing process, taking away from more traditional processes of ideation and language generation. As writers often do not complete their own ideation before engaging with suggestions, the suggested ideas and opinions seeded directions that writers then elaborated on. At the same time, writers did not notice the AI's influence and felt in full control of their writing, as they -- in principle -- could always edit the final text. We term this shift \textit{Reactive Writing}: an evaluation-first, suggestion-led writing practice that departs substantially from conventional composing in the presence of AI assistance and is highly vulnerable to AI-induced biases and opinion shifts.
Fears about AI-mediated communication are grounded in different expectations for one's own versus others' use
May 02, 2023



The rapid development of AI-mediated communication technologies (AICTs), which are digital tools that use AI to augment interpersonal messages, has raised concerns about the future of interpersonal trust and prompted discussions about disclosure and uptake. This paper contributes to this discussion by assessing perceptions about the acceptability and use of open and secret AICTs for oneself and others. In two studies with representative samples (UK: N=477, US: N=765), we found that secret AICT use is deemed less acceptable than open AICT use, people tend to overestimate others' AICT use, and people expect others to use AICTs irresponsibly. Thus, we raise concerns about the potential for misperceptions and different expectations for others to drive self-fulfilling pessimistic outlooks about AI-mediated communication.
Comparing Sentence-Level Suggestions to Message-Level Suggestions in AI-Mediated Communication
Feb 26, 2023



Traditionally, writing assistance systems have focused on short or even single-word suggestions. Recently, large language models like GPT-3 have made it possible to generate significantly longer natural-sounding suggestions, offering more advanced assistance opportunities. This study explores the trade-offs between sentence- vs. message-level suggestions for AI-mediated communication. We recruited 120 participants to act as staffers from legislators' offices who often need to respond to large volumes of constituent concerns. Participants were asked to reply to emails with different types of assistance. The results show that participants receiving message-level suggestions responded faster and were more satisfied with the experience, as they mainly edited the suggested drafts. In addition, the texts they wrote were evaluated as more helpful by others. In comparison, participants receiving sentence-level assistance retained a higher sense of agency, but took longer for the task as they needed to plan the flow of their responses and decide when to use suggestions. Our findings have implications for designing task-appropriate communication assistance systems.
Co-Writing with Opinionated Language Models Affects Users' Views
Feb 01, 2023



If large language models like GPT-3 preferably produce a particular point of view, they may influence people's opinions on an unknown scale. This study investigates whether a language-model-powered writing assistant that generates some opinions more often than others impacts what users write - and what they think. In an online experiment, we asked participants (N=1,506) to write a post discussing whether social media is good for society. Treatment group participants used a language-model-powered writing assistant configured to argue that social media is good or bad for society. Participants then completed a social media attitude survey, and independent judges (N=500) evaluated the opinions expressed in their writing. Using the opinionated language model affected the opinions expressed in participants' writing and shifted their opinions in the subsequent attitude survey. We discuss the wider implications of our results and argue that the opinions built into AI language technologies need to be monitored and engineered more carefully.
Human Heuristics for AI-Generated Language Are Flawed
Jun 15, 2022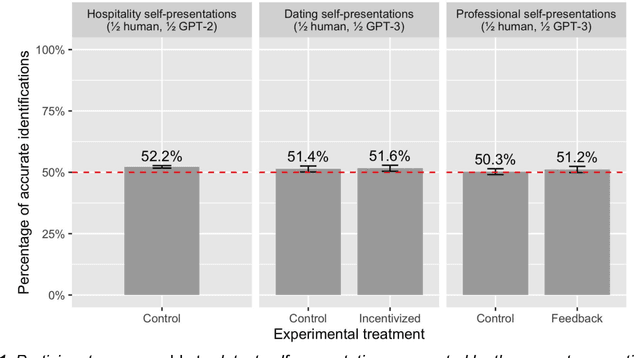
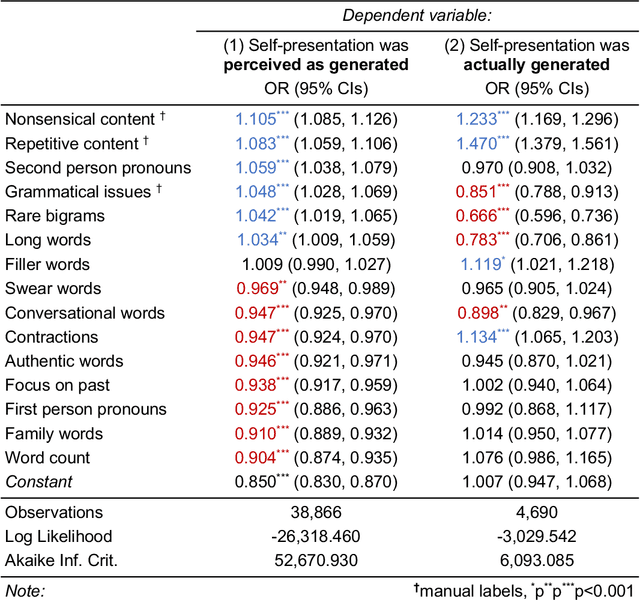
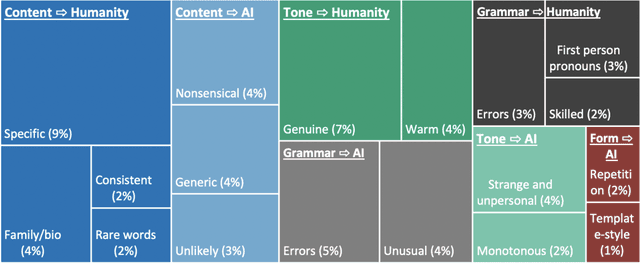
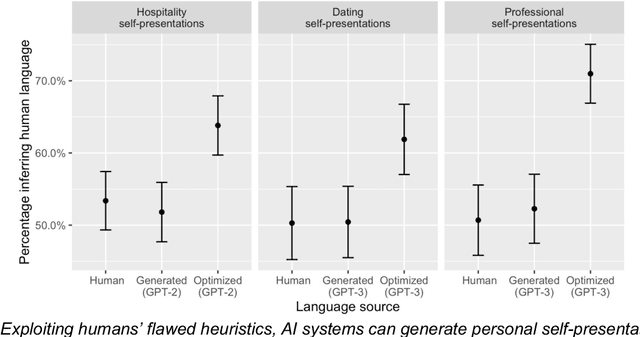
Human communication is increasingly intermixed with language generated by AI. Across chat, email, and social media, AI systems produce smart replies, autocompletes, and translations. AI-generated language is often not identified as such but poses as human language, raising concerns about novel forms of deception and manipulation. Here, we study how humans discern whether one of the most personal and consequential forms of language - a self-presentation - was generated by AI. Across six experiments, participants (N = 4,650) tried to identify self-presentations generated by state-of-the-art language models. Across professional, hospitality, and romantic settings, we find that humans are unable to identify AI-generated self-presentations. Combining qualitative analyses with language feature engineering, we find that human judgments of AI-generated language are handicapped by intuitive but flawed heuristics such as associating first-person pronouns, authentic words, or family topics with humanity. We show that these heuristics make human judgment of generated language predictable and manipulable, allowing AI systems to produce language perceived as more human than human. We conclude by discussing solutions - such as AI accents or fair use policies - to reduce the deceptive potential of generated language, limiting the subversion of human intuition.
How Different Groups Prioritize Ethical Values for Responsible AI
May 16, 2022
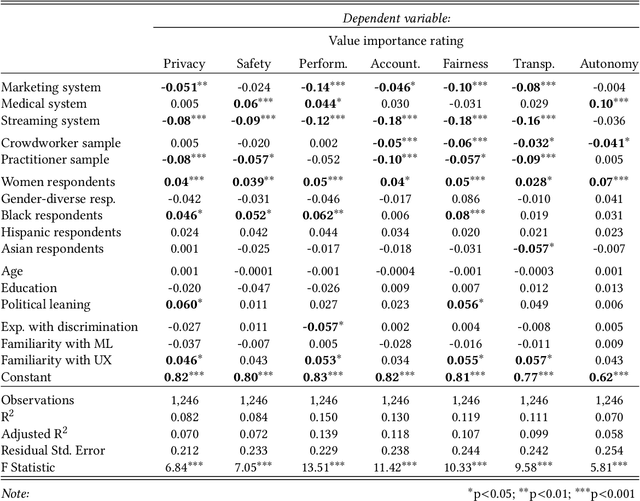
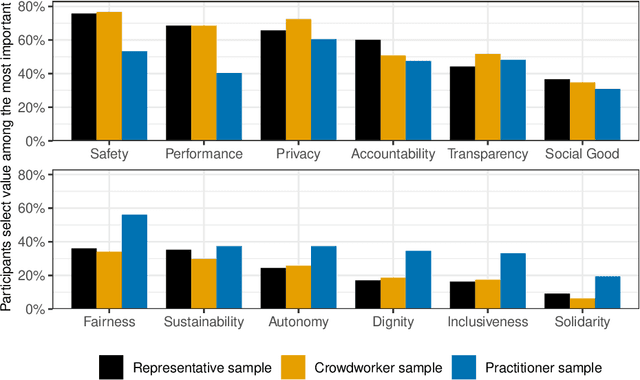
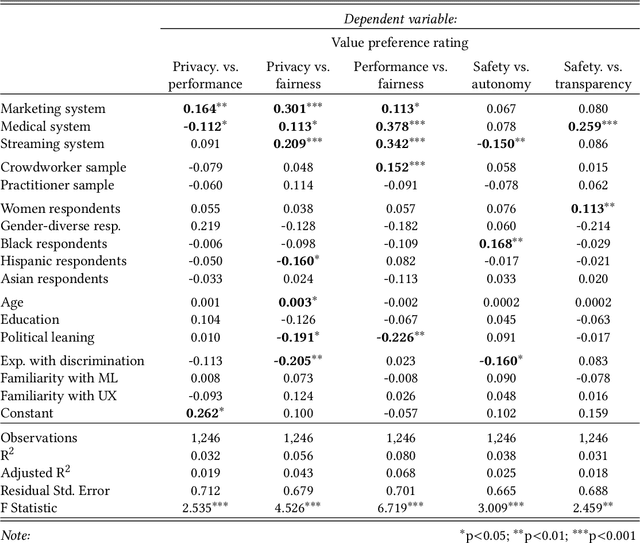
Private companies, public sector organizations, and academic groups have outlined ethical values they consider important for responsible artificial intelligence technologies. While their recommendations converge on a set of central values, little is known about the values a more representative public would find important for the AI technologies they interact with and might be affected by. We conducted a survey examining how individuals perceive and prioritize responsible AI values across three groups: a representative sample of the US population (N=743), a sample of crowdworkers (N=755), and a sample of AI practitioners (N=175). Our results empirically confirm a common concern: AI practitioners' value priorities differ from those of the general public. Compared to the US-representative sample, AI practitioners appear to consider responsible AI values as less important and emphasize a different set of values. In contrast, self-identified women and black respondents found responsible AI values more important than other groups. Surprisingly, more liberal-leaning participants, rather than participants reporting experiences with discrimination, were more likely to prioritize fairness than other groups. Our findings highlight the importance of paying attention to who gets to define responsible AI.