 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"What's important here?": Opportunities and Challenges of Using LLMs in Retrieving Information from Web Interfaces
Dec 11, 2023Large language models (LLMs) that have been trained on a corpus that includes large amount of code exhibit a remarkable ability to understand HTML code. As web interfaces are primarily constructed using HTML, we design an in-depth study to see how LLMs can be used to retrieve and locate important elements for a user given query (i.e. task description) in a web interface. In contrast with prior works, which primarily focused on autonomous web navigation, we decompose the problem as an even atomic operation - Can LLMs identify the important information in the web page for a user given query? This decomposition enables us to scrutinize the current capabilities of LLMs and uncover the opportunities and challenges they present. Our empirical experiments show that while LLMs exhibit a reasonable level of performance in retrieving important UI elements, there is still a substantial room for improvement. We hope our investigation will inspire follow-up works in overcoming the current challenges in this domain.
Latent Phrase Matching for Dysarthric Speech
Jun 08, 2023



Many consumer speech recognition systems are not tuned for people with speech disabilities, resulting in poor recognition and user experience, especially for severe speech differences. Recent studies have emphasized interest in personalized speech models from people with atypical speech patterns. We propose a query-by-example-based personalized phrase recognition system that is trained using small amounts of speech, is language agnostic, does not assume a traditional pronunciation lexicon, and generalizes well across speech difference severities. On an internal dataset collected from 32 people with dysarthria, this approach works regardless of severity and shows a 60% improvement in recall relative to a commercial speech recognition system. On the public EasyCall dataset of dysarthric speech, our approach improves accuracy by 30.5%. Performance degrades as the number of phrases increases, but consistently outperforms ASR systems when trained with 50 unique phrases.
USB: A Unified Summarization Benchmark Across Tasks and Domains
May 23, 2023An abundance of datasets exist for training and evaluating models on the task of summary generation.However, these datasets are often derived heuristically, and lack sufficient annotations to support research into all aspects of summarization, such as evidence extraction and controllable summarization. We introduce a benchmark comprising 8 tasks that require multi-dimensional understanding of summarization, e.g., surfacing evidence for a summary, assessing its correctness, and gauging its relevance to different topics. We compare various methods on this benchmark and discover that on multiple tasks, moderately-sized fine-tuned models consistently outperform much larger few-shot prompted language models. For factuality related tasks, we also evaluate existing heuristics to create training data and find that training on them performs worse than training on $20\times$ less human-labeled data. Our benchmark consists of data from 6 different domains, allowing us to study cross-domain performance of trained models. We find that for some tasks, the amount of training data matters more than the domain where it comes from, while for other tasks training specifically on data from the target domain, even if limited, is more beneficial. Our work fulfills the need for a well-annotated summarization benchmark with diverse tasks, and provides useful insights about the impact of the quality, size and domain of training data.
Downstream Datasets Make Surprisingly Good Pretraining Corpora
Sep 28, 2022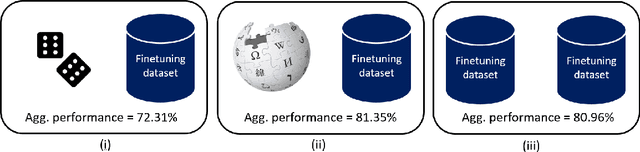
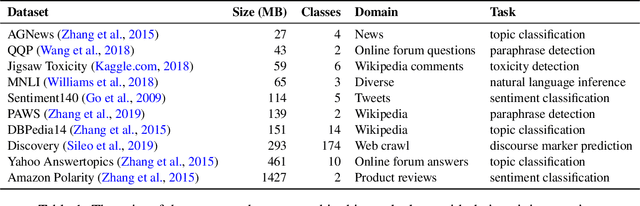
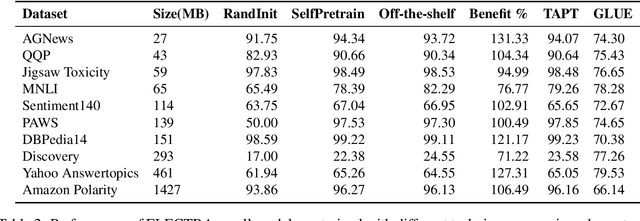
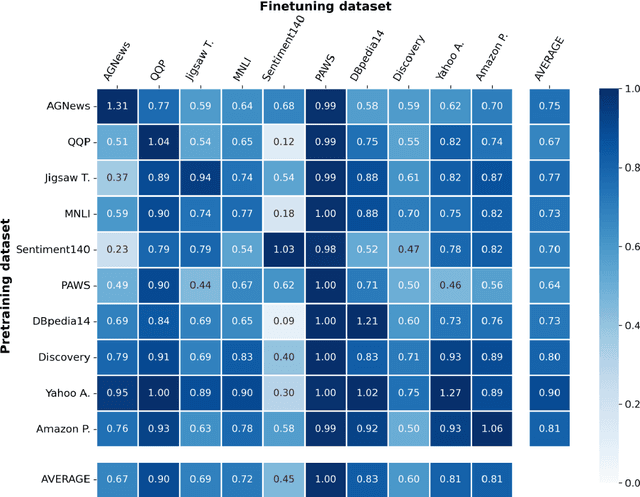
For most natural language processing tasks, the dominant practice is to finetune large pretrained transformer models (e.g., BERT) using smaller downstream datasets. Despite the success of this approach, it remains unclear to what extent these gains are attributable to the massive background corpora employed for pretraining versus to the pretraining objectives themselves. This paper introduces a large-scale study of self-pretraining, where the same (downstream) training data is used for both pretraining and finetuning. In experiments addressing both ELECTRA and RoBERTa models and 10 distinct downstream datasets, we observe that self-pretraining rivals standard pretraining on the BookWiki corpus (despite using around $10\times$--$500\times$ less data), outperforming the latter on $7$ and $5$ datasets, respectively. Surprisingly, these task-specific pretrained models often perform well on other tasks, including the GLUE benchmark. Our results suggest that in many scenarios, performance gains attributable to pretraining are driven primarily by the pretraining objective itself and are not always attributable to the incorporation of massive datasets. These findings are especially relevant in light of concerns about intellectual property and offensive content in web-scale pretraining data.
Improving Zero and Few-shot Generalization in Dialogue through Instruction Tuning
May 25, 2022
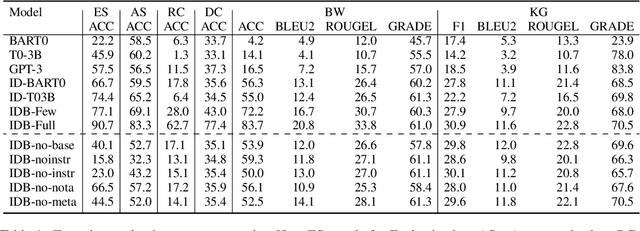
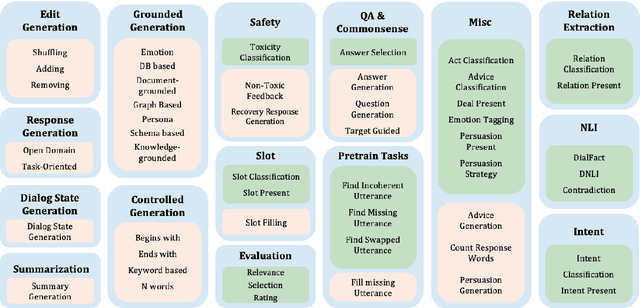
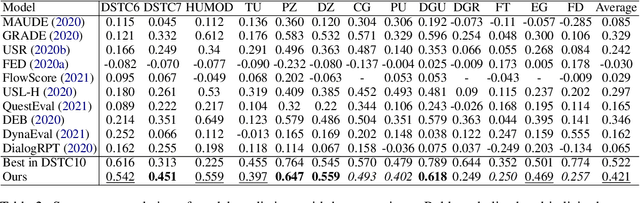
Instruction tuning is an emergent paradigm in NLP wherein natural language instructions are leveraged with language models to induce zero-shot performance on unseen tasks. Instructions have been shown to enable good performance on unseen tasks and datasets in both large and small language models. Dialogue is an especially interesting area to explore instruction tuning because dialogue systems perform multiple kinds of tasks related to language (e.g., natural language understanding and generation, domain-specific interaction), yet instruction tuning has not been systematically explored for dialogue-related tasks. We introduce InstructDial, an instruction tuning framework for dialogue, which consists of a repository of 48 diverse dialogue tasks in a unified text-to-text format created from 59 openly available dialogue datasets. Next, we explore cross-task generalization ability on models tuned on InstructDial across diverse dialogue tasks. Our analysis reveals that InstructDial enables good zero-shot performance on unseen datasets and tasks such as dialogue evaluation and intent detection, and even better performance in a few-shot setting. To ensure that models adhere to instructions, we introduce novel meta-tasks. We establish benchmark zero-shot and few-shot performance of models trained using the proposed framework on multiple dialogue tasks.
Target-Guided Dialogue Response Generation Using Commonsense and Data Augmentation
May 19, 2022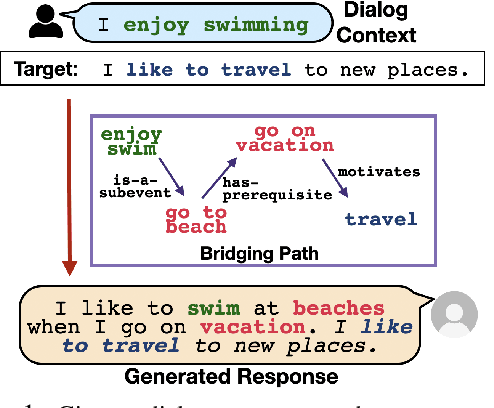
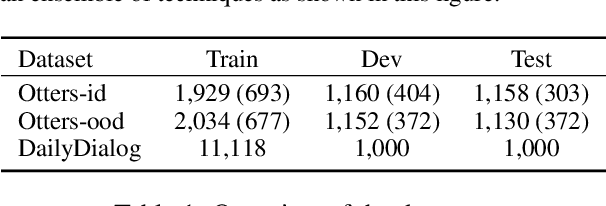
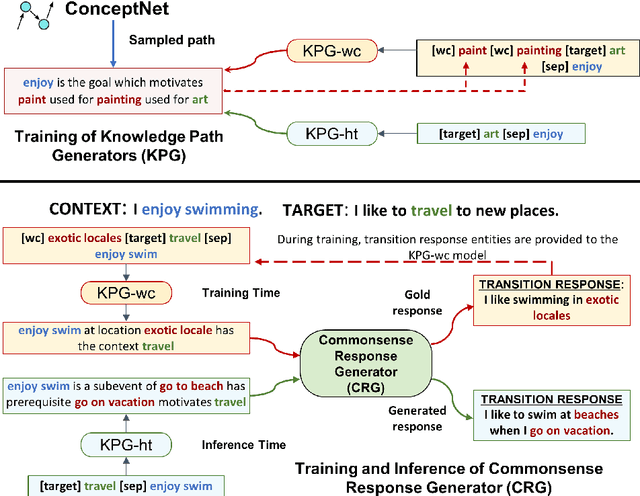
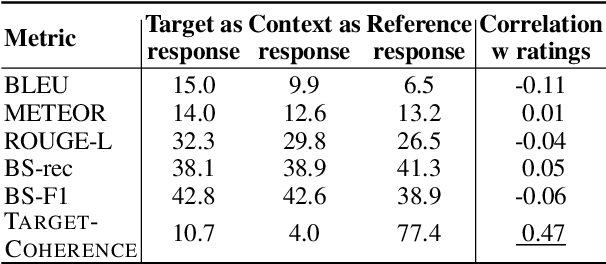
Target-guided response generation enables dialogue systems to smoothly transition a conversation from a dialogue context toward a target sentence. Such control is useful for designing dialogue systems that direct a conversation toward specific goals, such as creating non-obtrusive recommendations or introducing new topics in the conversation. In this paper, we introduce a new technique for target-guided response generation, which first finds a bridging path of commonsense knowledge concepts between the source and the target, and then uses the identified bridging path to generate transition responses. Additionally, we propose techniques to re-purpose existing dialogue datasets for target-guided generation. Experiments reveal that the proposed techniques outperform various baselines on this task. Finally, we observe that the existing automated metrics for this task correlate poorly with human judgement ratings. We propose a novel evaluation metric that we demonstrate is more reliable for target-guided response evaluation. Our work generally enables dialogue system designers to exercise more control over the conversations that their systems produce.
Nonverbal Sound Detection for Disordered Speech
Feb 15, 2022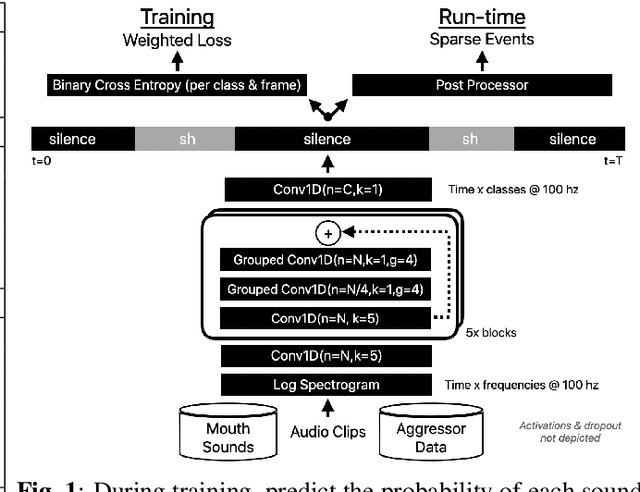
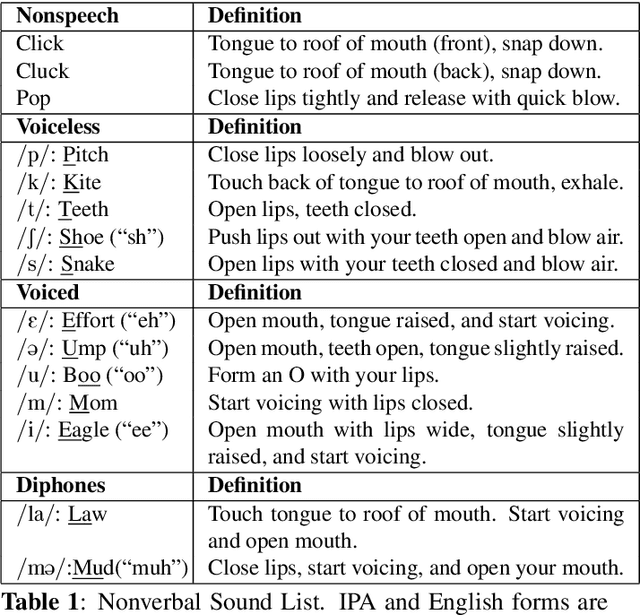
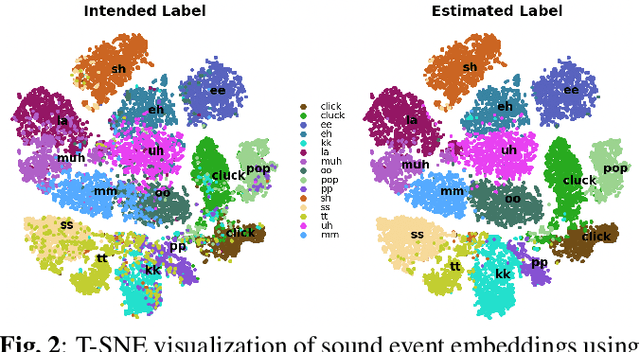
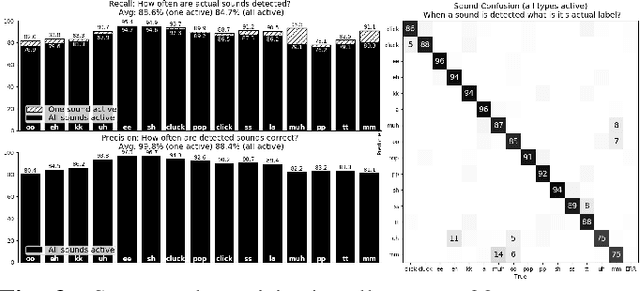
Voice assistants have become an essential tool for people with various disabilities because they enable complex phone- or tablet-based interactions without the need for fine-grained motor control, such as with touchscreens. However, these systems are not tuned for the unique characteristics of individuals with speech disorders, including many of those who have a motor-speech disorder, are deaf or hard of hearing, have a severe stutter, or are minimally verbal. We introduce an alternative voice-based input system which relies on sound event detection using fifteen nonverbal mouth sounds like "pop," "click," or "eh." This system was designed to work regardless of ones' speech abilities and allows full access to existing technology. In this paper, we describe the design of a dataset, model considerations for real-world deployment, and efforts towards model personalization. Our fully-supervised model achieves segment-level precision and recall of 88.6% and 88.4% on an internal dataset of 710 adults, while achieving 0.31 false positives per hour on aggressors such as speech. Five-shot personalization enables satisfactory performance in 84.5% of cases where the generic model fails.
Synthesizing Adversarial Negative Responses for Robust Response Ranking and Evaluation
Jun 10, 2021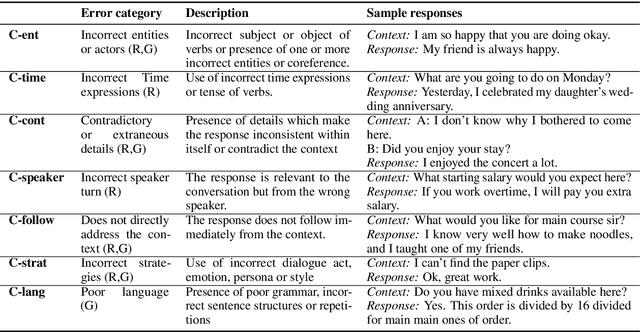
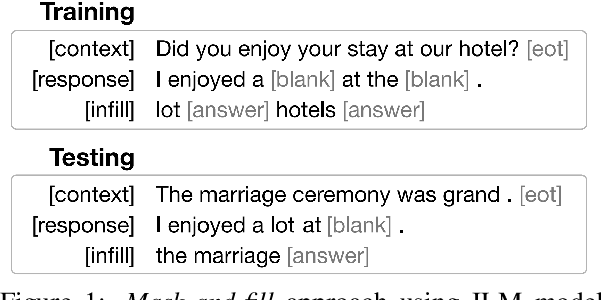

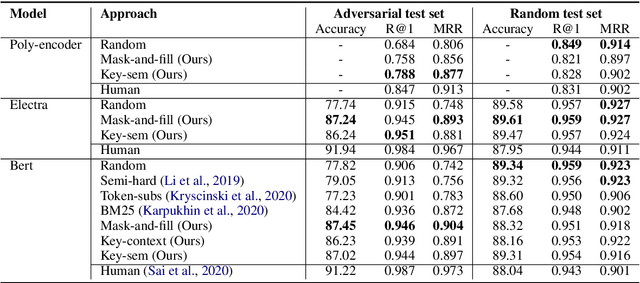
Open-domain neural dialogue models have achieved high performance in response ranking and evaluation tasks. These tasks are formulated as a binary classification of responses given in a dialogue context, and models generally learn to make predictions based on context-response content similarity. However, over-reliance on content similarity makes the models less sensitive to the presence of inconsistencies, incorrect time expressions and other factors important for response appropriateness and coherence. We propose approaches for automatically creating adversarial negative training data to help ranking and evaluation models learn features beyond content similarity. We propose mask-and-fill and keyword-guided approaches that generate negative examples for training more robust dialogue systems. These generated adversarial responses have high content similarity with the contexts but are either incoherent, inappropriate or not fluent. Our approaches are fully data-driven and can be easily incorporated in existing models and datasets. Experiments on classification, ranking and evaluation tasks across multiple datasets demonstrate that our approaches outperform strong baselines in providing informative negative examples for training dialogue systems.
SEP-28k: A Dataset for Stuttering Event Detection From Podcasts With People Who Stutter
Feb 24, 2021
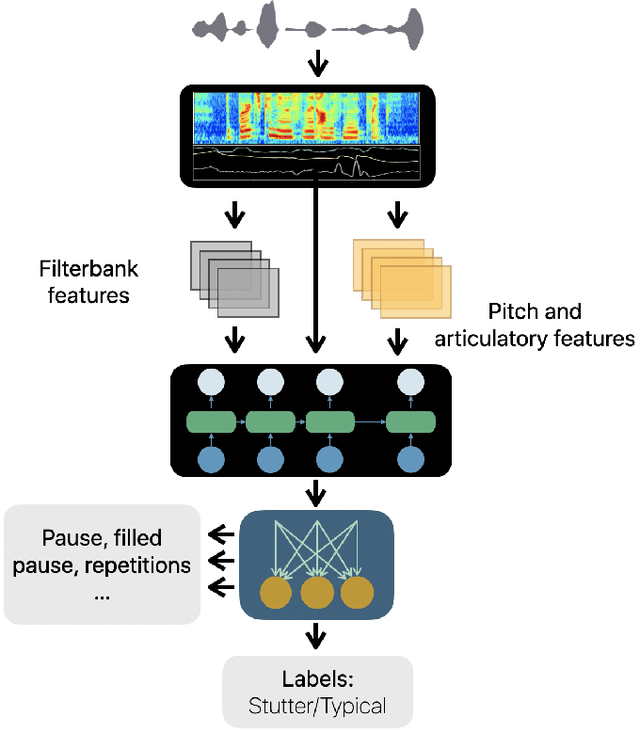
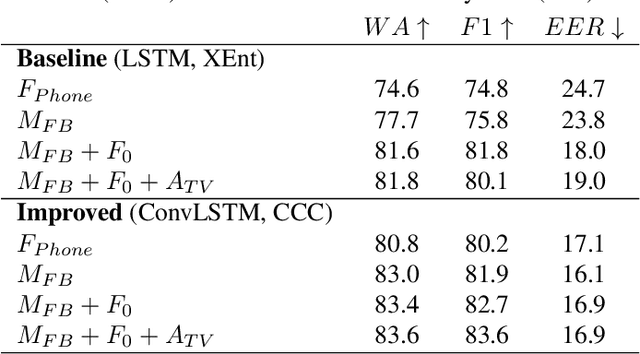
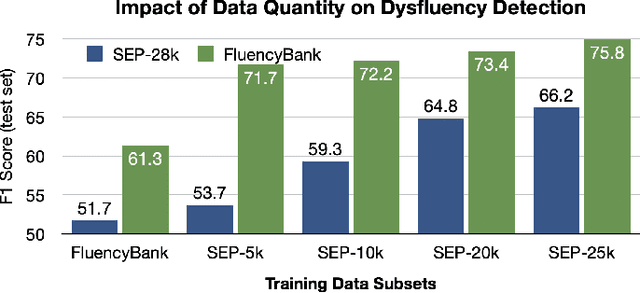
The ability to automatically detect stuttering events in speech could help speech pathologists track an individual's fluency over time or help improve speech recognition systems for people with atypical speech patterns. Despite increasing interest in this area, existing public datasets are too small to build generalizable dysfluency detection systems and lack sufficient annotations. In this work, we introduce Stuttering Events in Podcasts (SEP-28k), a dataset containing over 28k clips labeled with five event types including blocks, prolongations, sound repetitions, word repetitions, and interjections. Audio comes from public podcasts largely consisting of people who stutter interviewing other people who stutter. We benchmark a set of acoustic models on SEP-28k and the public FluencyBank dataset and highlight how simply increasing the amount of training data improves relative detection performance by 28\% and 24\% F1 on each. Annotations from over 32k clips across both datasets will be publicly released.
Controlling Dialogue Generation with Semantic Exemplars
Aug 20, 2020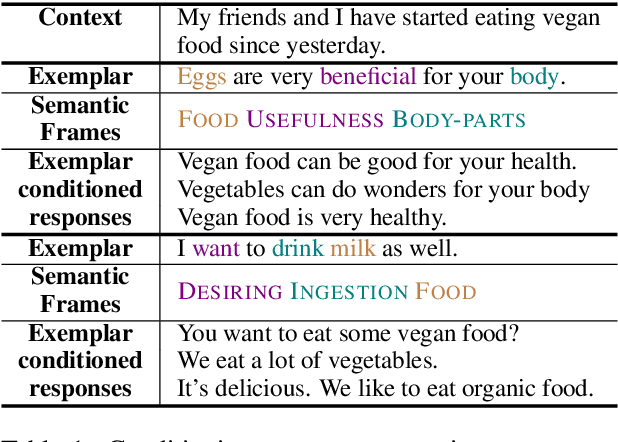
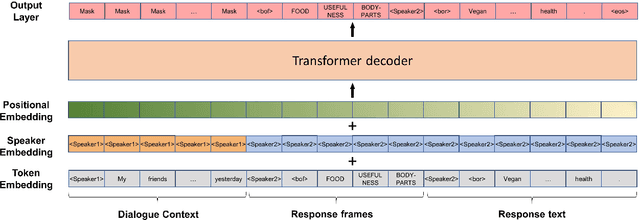
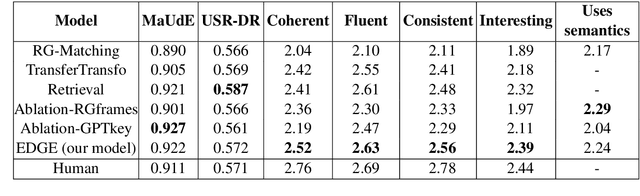
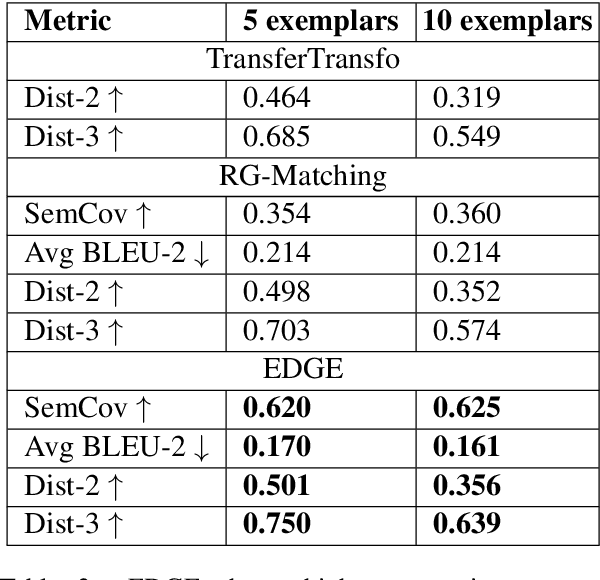
Dialogue systems pretrained with large language models generate locally coherent responses, but lack the fine-grained control over responses necessary to achieve specific goals. A promising method to control response generation is exemplar-based generation, in which models edit exemplar responses that are retrieved from training data, or hand-written to strategically address discourse-level goals, to fit new dialogue contexts. But, current exemplar-based approaches often excessively copy words from the exemplar responses, leading to incoherent replies. We present an Exemplar-based Dialogue Generation model, EDGE, that uses the semantic frames present in exemplar responses to guide generation. We show that controlling dialogue generation based on the semantic frames of exemplars, rather than words in the exemplar itself, improves the coherence of generated responses, while preserving semantic meaning and conversation goals present in exemplar responses.