 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Dataset Selection for Continual Adaptation of Generative Recommenders
Apr 09, 2026Recommendation systems must continuously adapt to evolving user behavior, yet the volume of data generated in large-scale streaming environments makes frequent full retraining impractical. This work investigates how targeted data selection can mitigate performance degradation caused by temporal distributional drift while maintaining scalability. We evaluate a range of representation choices and sampling strategies for curating small but informative subsets of user interaction data. Our results demonstrate that gradient-based representations, coupled with distribution-matching, improve downstream model performance, achieving training efficiency gains while preserving robustness to drift. These findings highlight data curation as a practical mechanism for scalable monitoring and adaptive model updates in production-scale recommendation systems.
In-Context Probing Approximates Influence Function for Data Valuation
Jul 17, 2024Data valuation quantifies the value of training data, and is used for data attribution (i.e., determining the contribution of training data towards model predictions), and data selection; both of which are important for curating high-quality datasets to train large language models. In our paper, we show that data valuation through in-context probing (i.e., prompting a LLM) approximates influence functions for selecting training data. We provide a theoretical sketch on this connection based on transformer models performing "implicit" gradient descent on its in-context inputs. Our empirical findings show that in-context probing and gradient-based influence frameworks are similar in how they rank training data. Furthermore, fine-tuning experiments on data selected by either method reveal similar model performance.
ET tu, CLIP? Addressing Common Object Errors for Unseen Environments
Jun 25, 2024


We introduce a simple method that employs pre-trained CLIP encoders to enhance model generalization in the ALFRED task. In contrast to previous literature where CLIP replaces the visual encoder, we suggest using CLIP as an additional module through an auxiliary object detection objective. We validate our method on the recently proposed Episodic Transformer architecture and demonstrate that incorporating CLIP improves task performance on the unseen validation set. Additionally, our analysis results support that CLIP especially helps with leveraging object descriptions, detecting small objects, and interpreting rare words.
Understanding the Effectiveness of Very Large Language Models on Dialog Evaluation
Jan 27, 2023



Language models have steadily increased in size over the past few years. They achieve a high level of performance on various natural language processing (NLP) tasks such as question answering and summarization. Large language models (LLMs) have been used for generation and can now output human-like text. Due to this, there are other downstream tasks in the realm of dialog that can now harness the LLMs' language understanding capabilities. Dialog evaluation is one task that this paper will explore. It concentrates on prompting with LLMs: BLOOM, OPT, GPT-3, Flan-T5, InstructDial and TNLGv2. The paper shows that the choice of datasets used for training a model contributes to how well it performs on a task as well as on how the prompt should be structured. Specifically, the more diverse and relevant the group of datasets that a model is trained on, the better dialog evaluation performs. This paper also investigates how the number of examples in the prompt and the type of example selection used affect the model's performance.
The DialPort tools
Aug 18, 2022
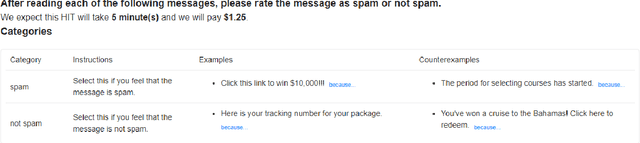
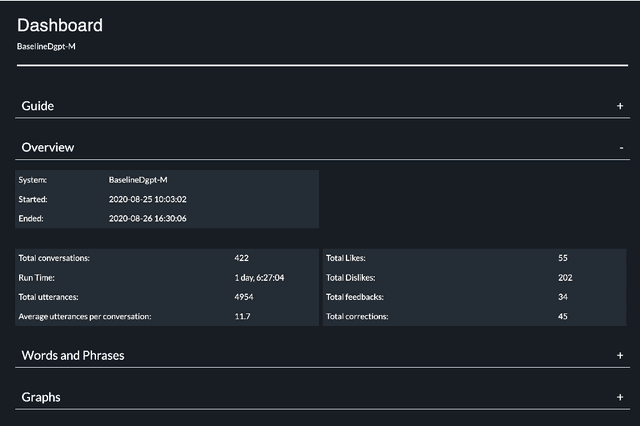
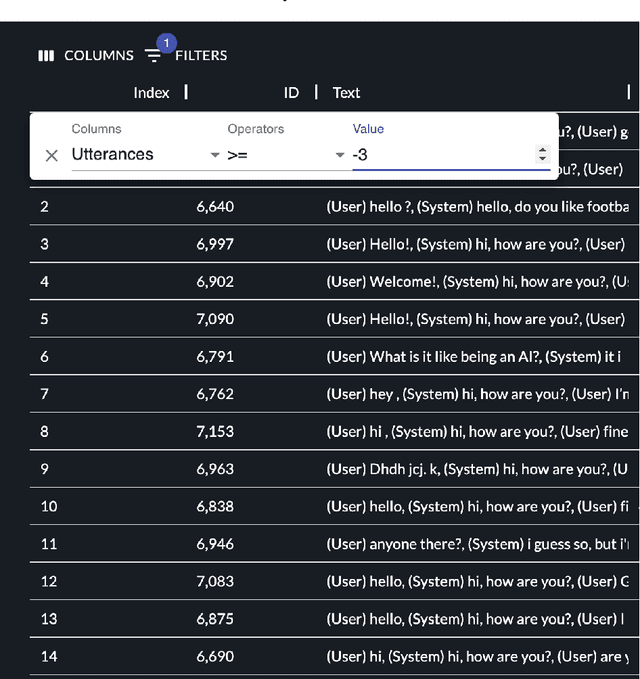
The DialPort project http://dialport.org/, funded by the National Science Foundation (NSF), covers a group of tools and services that aim at fulfilling the needs of the dialog research community. Over the course of six years, several offerings have been created, including the DialPort Portal and DialCrowd. This paper describes these contributions, which will be demoed at SIGDIAL, including implementation, prior studies, corresponding discoveries, and the locations at which the tools will remain freely available to the community going forward.
Improving Zero and Few-shot Generalization in Dialogue through Instruction Tuning
May 25, 2022
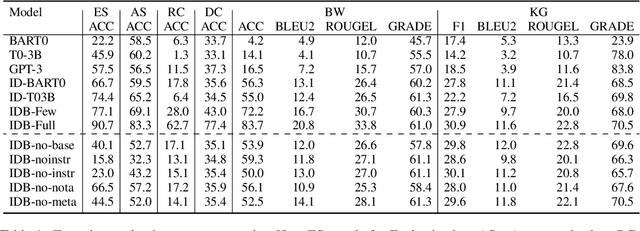
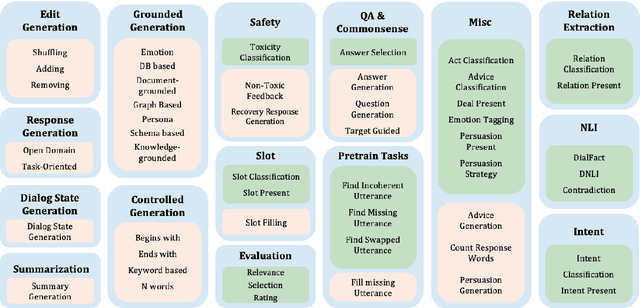
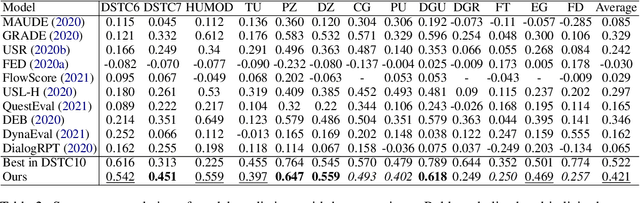
Instruction tuning is an emergent paradigm in NLP wherein natural language instructions are leveraged with language models to induce zero-shot performance on unseen tasks. Instructions have been shown to enable good performance on unseen tasks and datasets in both large and small language models. Dialogue is an especially interesting area to explore instruction tuning because dialogue systems perform multiple kinds of tasks related to language (e.g., natural language understanding and generation, domain-specific interaction), yet instruction tuning has not been systematically explored for dialogue-related tasks. We introduce InstructDial, an instruction tuning framework for dialogue, which consists of a repository of 48 diverse dialogue tasks in a unified text-to-text format created from 59 openly available dialogue datasets. Next, we explore cross-task generalization ability on models tuned on InstructDial across diverse dialogue tasks. Our analysis reveals that InstructDial enables good zero-shot performance on unseen datasets and tasks such as dialogue evaluation and intent detection, and even better performance in a few-shot setting. To ensure that models adhere to instructions, we introduce novel meta-tasks. We establish benchmark zero-shot and few-shot performance of models trained using the proposed framework on multiple dialogue tasks.