 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Aspect Term Extraction using Spiking Neural Network
Jan 10, 2026Aspect Term Extraction (ATE) identifies aspect terms in review sentences, a key subtask of sentiment analysis. While most existing approaches use energy-intensive deep neural networks (DNNs) for ATE as sequence labeling, this paper proposes a more energy-efficient alternative using Spiking Neural Networks (SNNs). Using sparse activations and event-driven inferences, SNNs capture temporal dependencies between words, making them suitable for ATE. The proposed architecture, SpikeATE, employs ternary spiking neurons and direct spike training fine-tuned with pseudo-gradients. Evaluated on four benchmark SemEval datasets, SpikeATE achieves performance comparable to state-of-the-art DNNs with significantly lower energy consumption. This highlights the use of SNNs as a practical and sustainable choice for ATE tasks.
Mapping and Scheduling Spiking Neural Networks On Segmented Ladder Bus Architectures
Jun 12, 2025Large-scale neuromorphic architectures consist of computing tiles that communicate spikes using a shared interconnect. The communication patterns in these systems are inherently sparse, asynchronous, and localized, as neural activity is characterized by temporal sparsity with occasional bursts of high traffic. These characteristics require optimized interconnects to handle high-activity bursts while consuming minimal power during idle periods. Among the proposed interconnect solutions, the dynamic segmented bus has gained attention due to its structural simplicity, scalability, and energy efficiency. Since the benefits of a dynamic segmented bus stem from its simplicity, it is essential to develop a streamlined control plane that can scale efficiently with the network. In this paper, we present a design methodology for a scenario-aware control plane tailored to a segmented ladder bus, with the aim of minimizing control overhead and optimizing energy and area utilization. We evaluated our approach using a combination of FPGA implementation and software simulation to assess scalability. The results demonstrated that our design process effectively reduces the control plane's area footprint compared to the data plane while maintaining scalability with network size.
Wafer2Spike: Spiking Neural Network for Wafer Map Pattern Classification
Nov 29, 2024



In integrated circuit design, the analysis of wafer map patterns is critical to improve yield and detect manufacturing issues. We develop Wafer2Spike, an architecture for wafer map pattern classification using a spiking neural network (SNN), and demonstrate that a well-trained SNN achieves superior performance compared to deep neural network-based solutions. Wafer2Spike achieves an average classification accuracy of 98\% on the WM-811k wafer benchmark dataset. It is also superior to existing approaches for classifying defect patterns that are underrepresented in the original dataset. Wafer2Spike achieves this improved precision with great computational efficiency.
A Coupled Neural Circuit Design for Guillain-Barre Syndrome
Jun 27, 2022

Guillain-Barre syndrome is a rare neurological condition in which the human immune system attacks the peripheral nervous system. A peripheral nervous system appears as a diffusively connected system of mathematical models of neuron models, and the system's period becomes shorter than the periods of each neural circuit. The stimuli in the conduction path that will address the myelin sheath that has lost its function are received by the axons and are conveyed externally to the target organ, aiming to solve the problem of decreased nerve conduction. In the NEURON simulation environment, one can create a neuron model and define biophysical events that take place within the system for study. In this environment, signal transmission between cells and dendrites is obtained graphically. The simulated potassium and sodium conductance are replicated adequately, and the electronic action potentials are quite comparable to those measured experimentally. In this work, we propose an analog and digital coupled neuron model comprising individual excitatory and inhibitory neural circuit blocks for a low-cost and energy-efficient system. Compared to digital design, our analog design performs in lower frequency but gives a 32.3\% decreased energy efficiency. Thus, the resulting coupled analog hardware neuron model can be a proposed model for the simulation of reduced nerve conduction. As a result, the analog coupled neuron, (even with its greater design complexity) serious contender for the future development of a wearable sensor device that could help with Guillain-Barre syndrome and other neurologic diseases.
Multiscale Voxel Based Decoding For Enhanced Natural Image Reconstruction From Brain Activity
May 27, 2022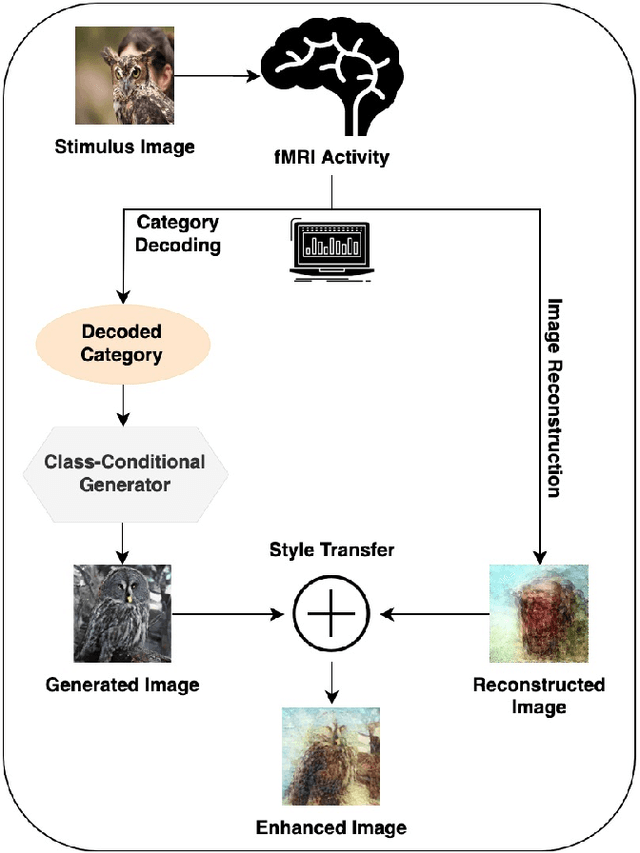



Reconstructing perceived images from human brain activity monitored by functional magnetic resonance imaging (fMRI) is hard, especially for natural images. Existing methods often result in blurry and unintelligible reconstructions with low fidelity. In this study, we present a novel approach for enhanced image reconstruction, in which existing methods for object decoding and image reconstruction are merged together. This is achieved by conditioning the reconstructed image to its decoded image category using a class-conditional generative adversarial network and neural style transfer. The results indicate that our approach improves the semantic similarity of the reconstructed images and can be used as a general framework for enhanced image reconstruction.
Learning in Feedback-driven Recurrent Spiking Neural Networks using full-FORCE Training
May 26, 2022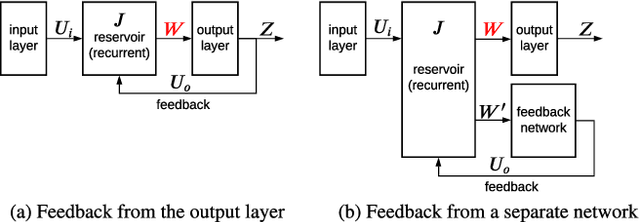
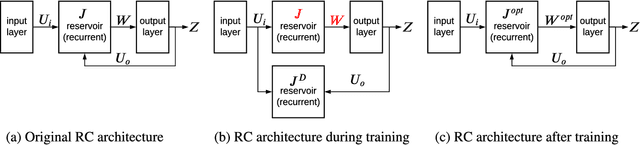
Feedback-driven recurrent spiking neural networks (RSNNs) are powerful computational models that can mimic dynamical systems. However, the presence of a feedback loop from the readout to the recurrent layer de-stabilizes the learning mechanism and prevents it from converging. Here, we propose a supervised training procedure for RSNNs, where a second network is introduced only during the training, to provide hint for the target dynamics. The proposed training procedure consists of generating targets for both recurrent and readout layers (i.e., for a full RSNN system). It uses the recursive least square-based First-Order and Reduced Control Error (FORCE) algorithm to fit the activity of each layer to its target. The proposed full-FORCE training procedure reduces the amount of modifications needed to keep the error between the output and target close to zero. These modifications control the feedback loop, which causes the training to converge. We demonstrate the improved performance and noise robustness of the proposed full-FORCE training procedure to model 8 dynamical systems using RSNNs with leaky integrate and fire (LIF) neurons and rate coding. For energy-efficient hardware implementation, an alternative time-to-first-spike (TTFS) coding is implemented for the full- FORCE training procedure. Compared to rate coding, full-FORCE with TTFS coding generates fewer spikes and facilitates faster convergence to the target dynamics.
A Design Methodology for Fault-Tolerant Computing using Astrocyte Neural Networks
Apr 06, 2022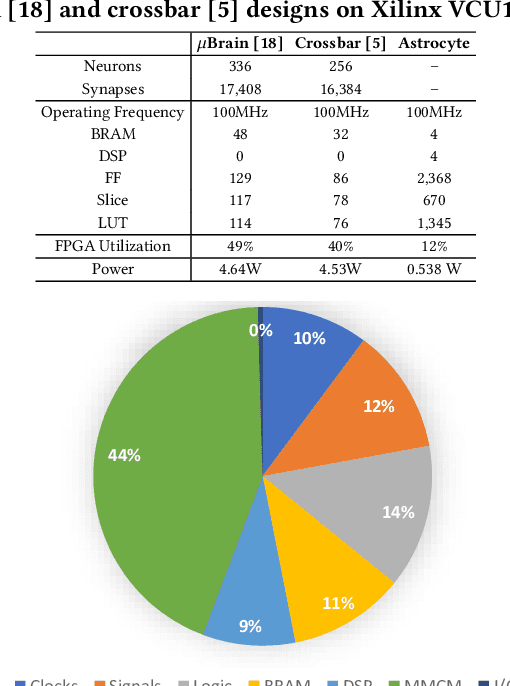
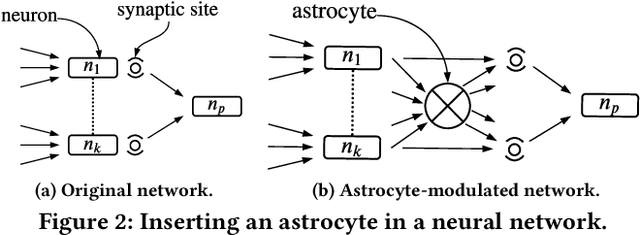
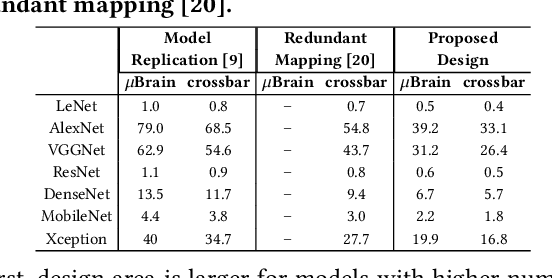
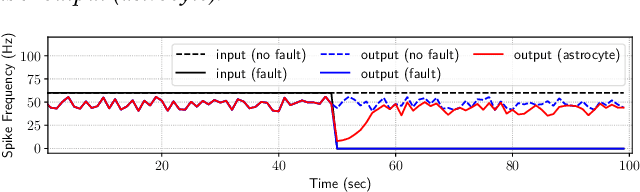
We propose a design methodology to facilitate fault tolerance of deep learning models. First, we implement a many-core fault-tolerant neuromorphic hardware design, where neuron and synapse circuitries in each neuromorphic core are enclosed with astrocyte circuitries, the star-shaped glial cells of the brain that facilitate self-repair by restoring the spike firing frequency of a failed neuron using a closed-loop retrograde feedback signal. Next, we introduce astrocytes in a deep learning model to achieve the required degree of tolerance to hardware faults. Finally, we use a system software to partition the astrocyte-enabled model into clusters and implement them on the proposed fault-tolerant neuromorphic design. We evaluate this design methodology using seven deep learning inference models and show that it is both area and power efficient.
Design-Technology Co-Optimization for NVM-based Neuromorphic Processing Elements
Mar 10, 2022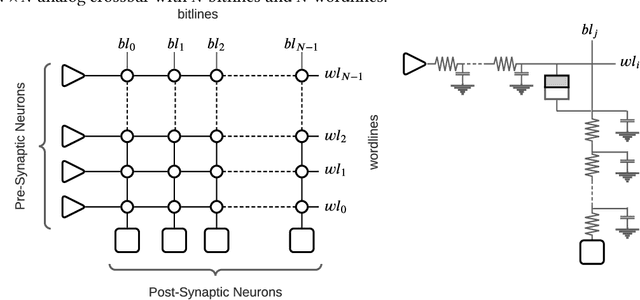
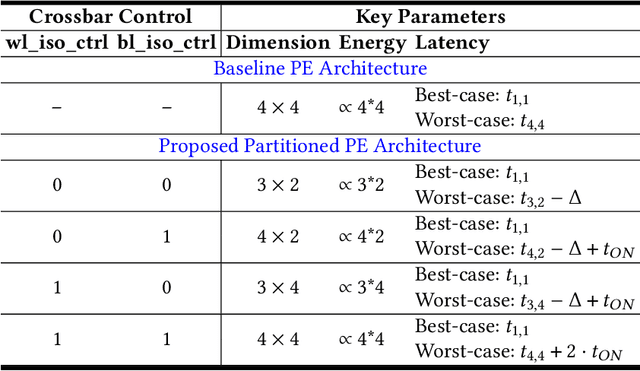
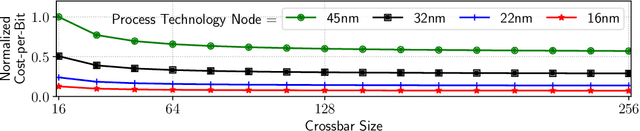
Neuromorphic hardware platforms can significantly lower the energy overhead of a machine learning inference task. We present a design-technology tradeoff analysis to implement such inference tasks on the processing elements (PEs) of a Non- Volatile Memory (NVM)-based neuromorphic hardware. Through detailed circuit-level simulations at scaled process technology nodes, we show the negative impact of technology scaling on the information-processing latency, which impacts the quality-of-service (QoS) of an embedded ML system. At a finer granularity, the latency inside a PE depends on 1) the delay introduced by parasitic components on its current paths, and 2) the varying delay to sense different resistance states of its NVM cells. Based on these two observations, we make the following three contributions. First, on the technology front, we propose an optimization scheme where the NVM resistance state that takes the longest time to sense is set on current paths having the least delay, and vice versa, reducing the average PE latency, which improves the QoS. Second, on the architecture front, we introduce isolation transistors within each PE to partition it into regions that can be individually power-gated, reducing both latency and energy. Finally, on the system-software front, we propose a mechanism to leverage the proposed technological and architectural enhancements when implementing a machine-learning inference task on neuromorphic PEs of the hardware. Evaluations with a recent neuromorphic hardware architecture show that our proposed design-technology co-optimization approach improves both performance and energy efficiency of machine-learning inference tasks without incurring high cost-per-bit.
Energy-Efficient Respiratory Anomaly Detection in Premature Newborn Infants
Feb 21, 2022



Precise monitoring of respiratory rate in premature infants is essential to initiate medical interventions as required. Wired technologies can be invasive and obtrusive to the patients. We propose a Deep Learning enabled wearable monitoring system for premature newborn infants, where respiratory cessation is predicted using signals that are collected wirelessly from a non-invasive wearable Bellypatch put on infant's body. We propose a five-stage design pipeline involving data collection and labeling, feature scaling, model selection with hyperparameter tuning, model training and validation, model testing and deployment. The model used is a 1-D Convolutional Neural Network (1DCNN) architecture with 1 convolutional layer, 1 pooling layer and 3 fully-connected layers, achieving 97.15% accuracy. To address energy limitations of wearable processing, several quantization techniques are explored and their performance and energy consumption are analyzed. We propose a novel Spiking-Neural-Network(SNN) based respiratory classification solution, which can be implemented on event-driven neuromorphic hardware. We propose an approach to convert the analog operations of our baseline 1DCNN to their spiking equivalent. We perform a design-space exploration using the parameters of the converted SNN to generate inference solutions having different accuracy and energy footprints. We select a solution that achieves 93.33% accuracy with 18 times lower energy compared with baseline 1DCNN model. Additionally the proposed SNN solution achieves similar accuracy but with 4 times less energy.
Implementing Spiking Neural Networks on Neuromorphic Architectures: A Review
Feb 17, 2022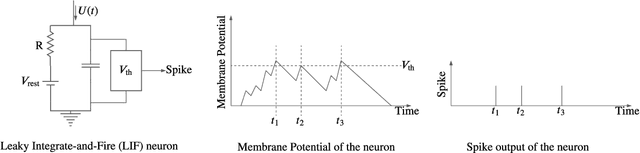
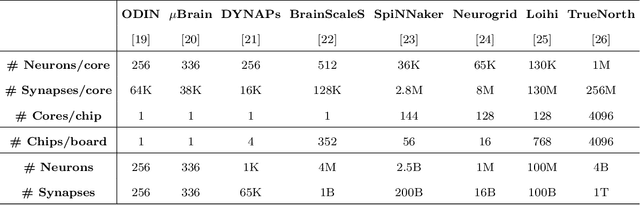
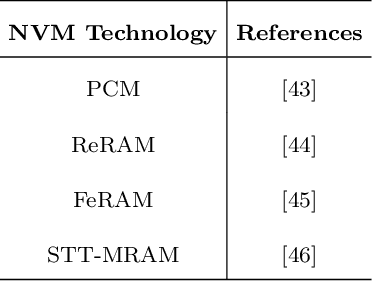
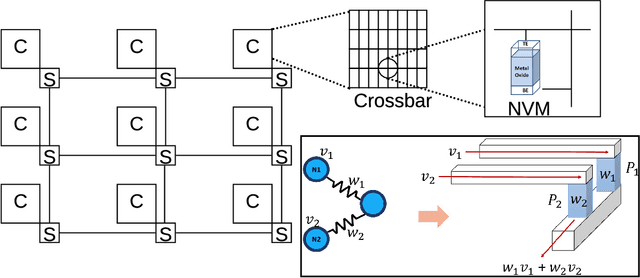
Recently, both industry and academia have proposed several different neuromorphic systems to execute machine learning applications that are designed using Spiking Neural Networks (SNNs). With the growing complexity on design and technology fronts, programming such systems to admit and execute a machine learning application is becoming increasingly challenging. Additionally, neuromorphic systems are required to guarantee real-time performance, consume lower energy, and provide tolerance to logic and memory failures. Consequently, there is a clear need for system software frameworks that can implement machine learning applications on current and emerging neuromorphic systems, and simultaneously address performance, energy, and reliability. Here, we provide a comprehensive overview of such frameworks proposed for both, platform-based design and hardware-software co-design. We highlight challenges and opportunities that the future holds in the area of system software technology for neuromorphic computing.