 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems
Mar 16, 2016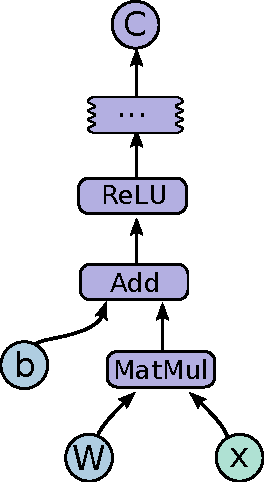

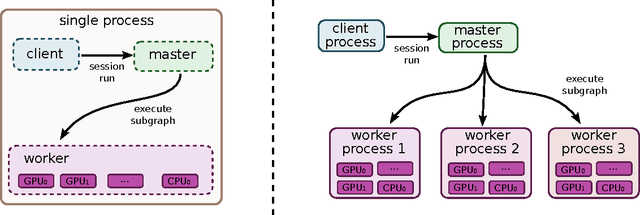
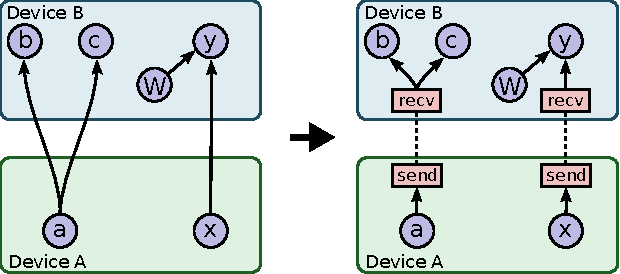
TensorFlow is an interface for expressing machine learning algorithms, and an implementation for executing such algorithms. A computation expressed using TensorFlow can be executed with little or no change on a wide variety of heterogeneous systems, ranging from mobile devices such as phones and tablets up to large-scale distributed systems of hundreds of machines and thousands of computational devices such as GPU cards. The system is flexible and can be used to express a wide variety of algorithms, including training and inference algorithms for deep neural network models, and it has been used for conducting research and for deploying machine learning systems into production across more than a dozen areas of computer science and other fields, including speech recognition, computer vision, robotics, information retrieval, natural language processing, geographic information extraction, and computational drug discovery. This paper describes the TensorFlow interface and an implementation of that interface that we have built at Google. The TensorFlow API and a reference implementation were released as an open-source package under the Apache 2.0 license in November, 2015 and are available at www.tensorflow.org.
Zero-Shot Learning by Convex Combination of Semantic Embeddings
Mar 21, 2014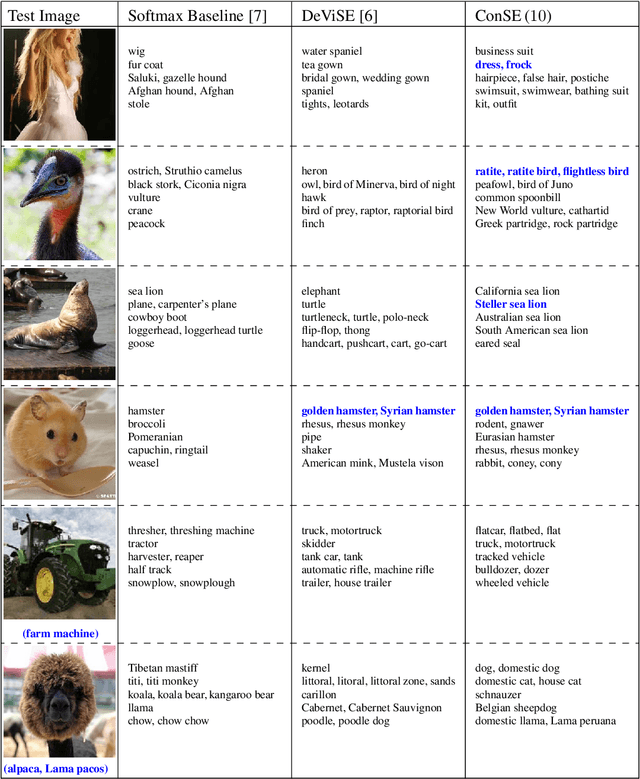
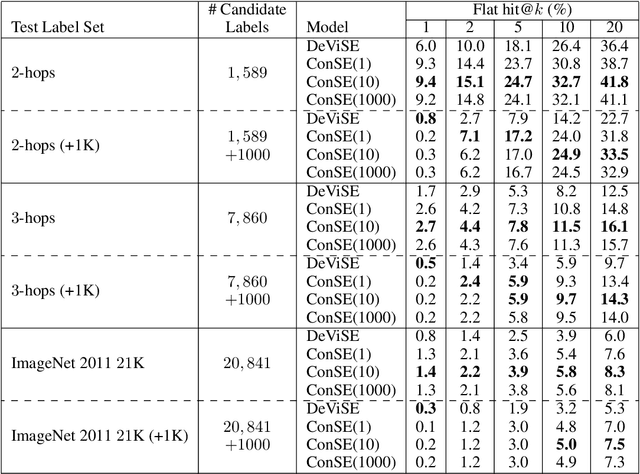
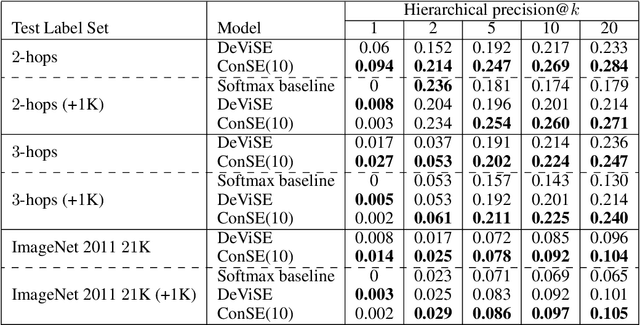
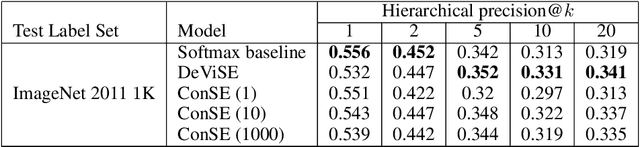
Several recent publications have proposed methods for mapping images into continuous semantic embedding spaces. In some cases the embedding space is trained jointly with the image transformation. In other cases the semantic embedding space is established by an independent natural language processing task, and then the image transformation into that space is learned in a second stage. Proponents of these image embedding systems have stressed their advantages over the traditional \nway{} classification framing of image understanding, particularly in terms of the promise for zero-shot learning -- the ability to correctly annotate images of previously unseen object categories. In this paper, we propose a simple method for constructing an image embedding system from any existing \nway{} image classifier and a semantic word embedding model, which contains the $\n$ class labels in its vocabulary. Our method maps images into the semantic embedding space via convex combination of the class label embedding vectors, and requires no additional training. We show that this simple and direct method confers many of the advantages associated with more complex image embedding schemes, and indeed outperforms state of the art methods on the ImageNet zero-shot learning task.
Distributed Representations of Words and Phrases and their Compositionality
Oct 16, 2013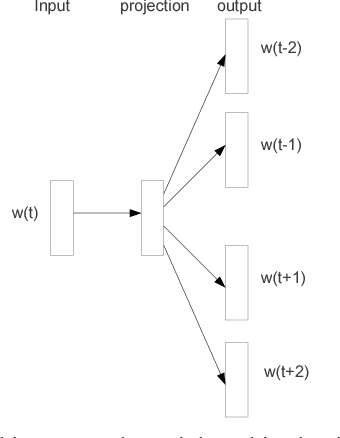
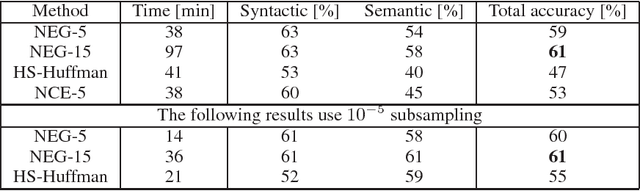
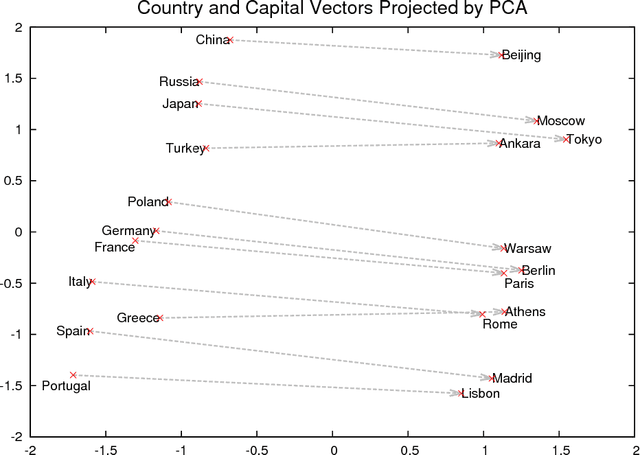
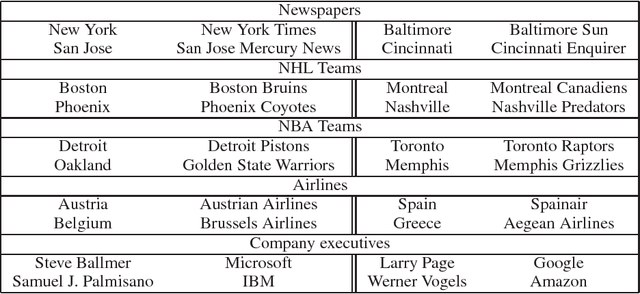
The recently introduced continuous Skip-gram model is an efficient method for learning high-quality distributed vector representations that capture a large number of precise syntactic and semantic word relationships. In this paper we present several extensions that improve both the quality of the vectors and the training speed. By subsampling of the frequent words we obtain significant speedup and also learn more regular word representations. We also describe a simple alternative to the hierarchical softmax called negative sampling. An inherent limitation of word representations is their indifference to word order and their inability to represent idiomatic phrases. For example, the meanings of "Canada" and "Air" cannot be easily combined to obtain "Air Canada". Motivated by this example, we present a simple method for finding phrases in text, and show that learning good vector representations for millions of phrases is possible.
Efficient Estimation of Word Representations in Vector Space
Sep 07, 2013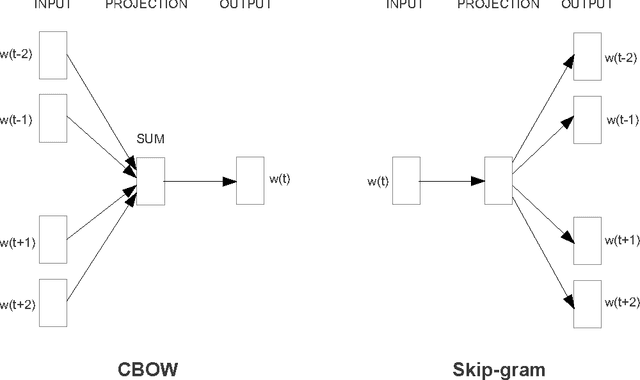
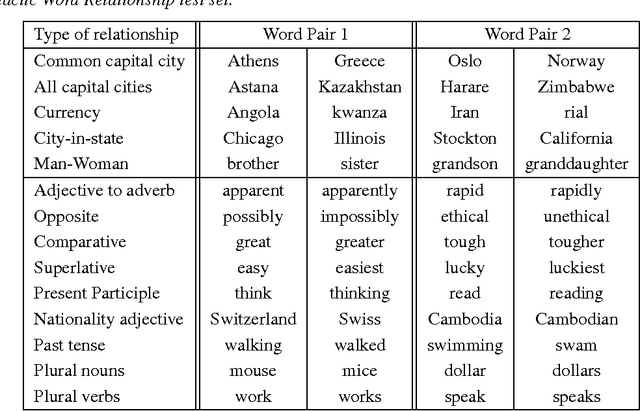
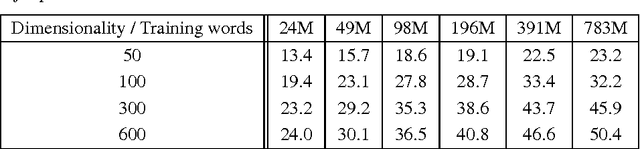
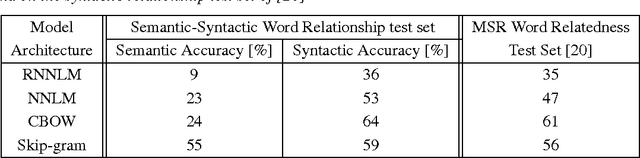
We propose two novel model architectures for computing continuous vector representations of words from very large data sets. The quality of these representations is measured in a word similarity task, and the results are compared to the previously best performing techniques based on different types of neural networks. We observe large improvements in accuracy at much lower computational cost, i.e. it takes less than a day to learn high quality word vectors from a 1.6 billion words data set. Furthermore, we show that these vectors provide state-of-the-art performance on our test set for measuring syntactic and semantic word similarities.