 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASAP-MO:Advanced Situational Awareness and Perception for Mission-critical Operations
May 02, 2025Deploying robotic missions can be challenging due to the complexity of controlling robots with multiple degrees of freedom, fusing diverse sensory inputs, and managing communication delays and interferences. In nuclear inspection, robots can be crucial in assessing environments where human presence is limited, requiring precise teleoperation and coordination. Teleoperation requires extensive training, as operators must process multiple outputs while ensuring safe interaction with critical assets. These challenges are amplified when operating a fleet of heterogeneous robots across multiple environments, as each robot may have distinct control interfaces, sensory systems, and operational constraints. Efficient coordination in such settings remains an open problem. This paper presents a field report on how we integrated robot fleet capabilities - including mapping, localization, and telecommunication - toward a joint mission. We simulated a nuclear inspection scenario for exposed areas, using lights to represent a radiation source. We deployed two Unmanned Ground Vehicles (UGVs) tasked with mapping indoor and outdoor environments while remotely controlled from a single base station. Despite having distinct operational goals, the robots produced a unified map output, demonstrating the feasibility of coordinated multi-robot missions. Our results highlight key operational challenges and provide insights into improving adaptability and situational awareness in remote robotic deployments.
UAV-Assisted Self-Supervised Terrain Awareness for Off-Road Navigation
Sep 26, 2024



Terrain awareness is an essential milestone to enable truly autonomous off-road navigation. Accurately predicting terrain characteristics allows optimizing a vehicle's path against potential hazards. Recent methods use deep neural networks to predict traversability-related terrain properties in a self-supervised manner, relying on proprioception as a training signal. However, onboard cameras are inherently limited by their point-of-view relative to the ground, suffering from occlusions and vanishing pixel density with distance. This paper introduces a novel approach for self-supervised terrain characterization using an aerial perspective from a hovering drone. We capture terrain-aligned images while sampling the environment with a ground vehicle, effectively training a simple predictor for vibrations, bumpiness, and energy consumption. Our dataset includes 2.8 km of off-road data collected in forest environment, comprising 13 484 ground-based images and 12 935 aerial images. Our findings show that drone imagery improves terrain property prediction by 21.37 % on the whole dataset and 37.35 % in high vegetation, compared to ground robot images. We conduct ablation studies to identify the main causes of these performance improvements. We also demonstrate the real-world applicability of our approach by scouting an unseen area with a drone, planning and executing an optimized path on the ground.
Field Report on a Wearable and Versatile Solution for Field Acquisition and Exploration
Apr 30, 2024



This report presents a wearable plug-and-play platform for data acquisition in the field. The platform, extending a waterproof Pelican Case into a 20 kg backpack offers 5.5 hours of power autonomy, while recording data with two cameras, a lidar, an Inertial Measurement Unit (IMU), and a Global Navigation Satellite System (GNSS) receiver. The system only requires a single operator and is readily controlled with a built-in screen and buttons. Due to its small footprint, it offers greater flexibility than large vehicles typically deployed in off-trail environments. We describe the platform's design, detailing the mechanical parts, electrical components, and software stack. We explain the system's limitations, drawing from its extensive deployment spanning over 20 kilometers of trajectories across various seasons, environments, and weather conditions. We derive valuable lessons learned from these deployments and present several possible applications for the system. The possible use cases consider not only academic research but also insights from consultations with our industrial partners. The mechanical design including all CAD files, as well as the software stack, are publicly available at https://github.com/norlab-ulaval/backpack_workspace.
Exposing the Unseen: Exposure Time Emulation for Offline Benchmarking of Vision Algorithms
Sep 22, 2023Visual Odometry (VO) is one of the fundamental tasks in computer vision for robotics. However, its performance is deeply affected by High Dynamic Range (HDR) scenes, omnipresent outdoor. While new Automatic-Exposure (AE) approaches to mitigate this have appeared, their comparison in a reproducible manner is problematic. This stems from the fact that the behavior of AE depends on the environment, and it affects the image acquisition process. Consequently, AE has traditionally only been benchmarked in an online manner, making the experiments non-reproducible. To solve this, we propose a new methodology based on an emulator that can generate images at any exposure time. It leverages BorealHDR, a unique multi-exposure stereo dataset collected over 8.4 km, on 50 trajectories with challenging illumination conditions. Moreover, it contains pose ground truth for each image and a global 3D map, based on lidar data. We show that using these images acquired at different exposure times, we can emulate realistic images keeping a Root-Mean-Square Error (RMSE) below 1.78 % compared to ground truth images. To demonstrate the practicality of our approach for offline benchmarking, we compared three state-of-the-art AE algorithms on key elements of Visual Simultaneous Localization And Mapping (VSLAM) pipeline, against four baselines. Consequently, reproducible evaluation of AE is now possible, speeding up the development of future approaches. Our code and dataset are available online at this link: https://github.com/norlab-ulaval/BorealHDR
MaskBEV: Joint Object Detection and Footprint Completion for Bird's-eye View 3D Point Clouds
Jul 04, 2023Recent works in object detection in LiDAR point clouds mostly focus on predicting bounding boxes around objects. This prediction is commonly achieved using anchor-based or anchor-free detectors that predict bounding boxes, requiring significant explicit prior knowledge about the objects to work properly. To remedy these limitations, we propose MaskBEV, a bird's-eye view (BEV) mask-based object detector neural architecture. MaskBEV predicts a set of BEV instance masks that represent the footprints of detected objects. Moreover, our approach allows object detection and footprint completion in a single pass. MaskBEV also reformulates the detection problem purely in terms of classification, doing away with regression usually done to predict bounding boxes. We evaluate the performance of MaskBEV on both SemanticKITTI and KITTI datasets while analyzing the architecture advantages and limitations.
Tree Detection and Diameter Estimation Based on Deep Learning
Oct 31, 2022Tree perception is an essential building block toward autonomous forestry operations. Current developments generally consider input data from lidar sensors to solve forest navigation, tree detection and diameter estimation problems. Whereas cameras paired with deep learning algorithms usually address species classification or forest anomaly detection. In either of these cases, data unavailability and forest diversity restrain deep learning developments for autonomous systems. So, we propose two densely annotated image datasets - 43k synthetic, 100 real - for bounding box, segmentation mask and keypoint detections to assess the potential of vision-based methods. Deep neural network models trained on our datasets achieve a precision of 90.4% for tree detection, 87.2% for tree segmentation, and centimeter accurate keypoint estimations. We measure our models' generalizability when testing it on other forest datasets, and their scalability with different dataset sizes and architectural improvements. Overall, the experimental results offer promising avenues toward autonomous tree felling operations and other applied forestry problems. The datasets and pre-trained models in this article are publicly available on \href{https://github.com/norlab-ulaval/PercepTreeV1}{GitHub} (https://github.com/norlab-ulaval/PercepTreeV1).
Instance Segmentation for Autonomous Log Grasping in Forestry Operations
Mar 03, 2022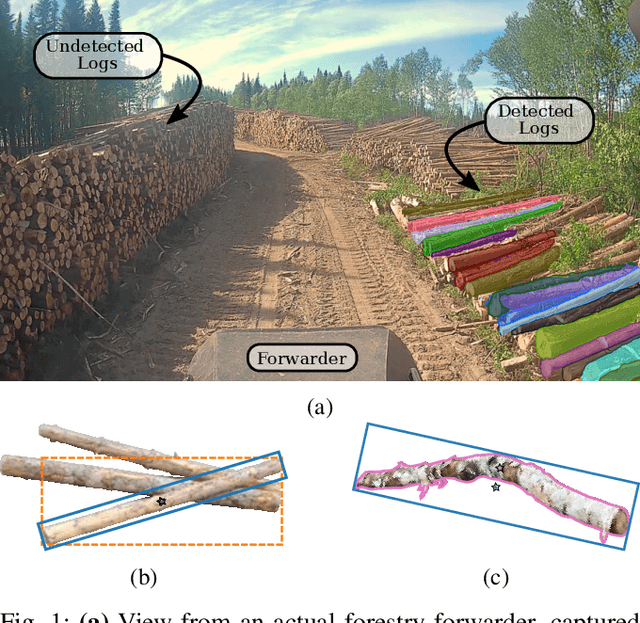
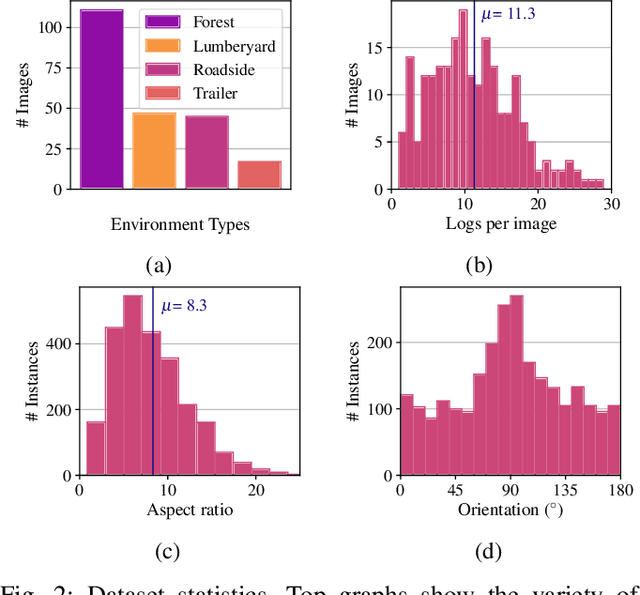
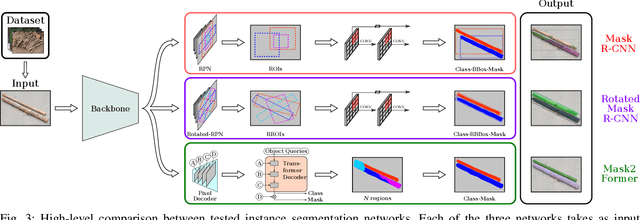
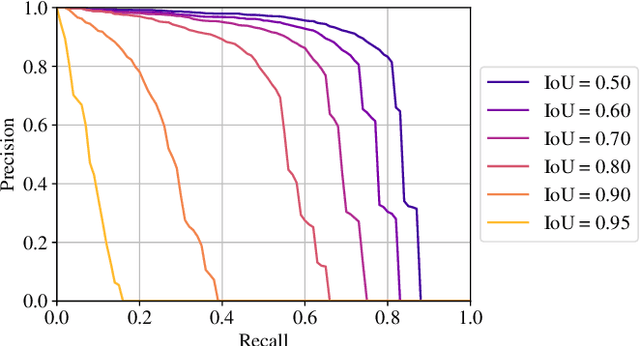
Wood logs picking is a challenging task to automate. Indeed, logs usually come in cluttered configurations, randomly orientated and overlapping. Recent work on log picking automation usually assume that the logs' pose is known, with little consideration given to the actual perception problem. In this paper, we squarely address the latter, using a data-driven approach. First, we introduce a novel dataset, named TimberSeg 1.0, that is densely annotated, i.e., that includes both bounding boxes and pixel-level mask annotations for logs. This dataset comprises 220 images with 2500 individually segmented logs. Using our dataset, we then compare three neural network architectures on the task of individual logs detection and segmentation; two region-based methods and one attention-based method. Unsurprisingly, our results show that axis-aligned proposals, failing to take into account the directional nature of logs, underperform with 19.03 mAP. A rotation-aware proposal method significantly improve results to 31.83 mAP. More interestingly, a Transformer-based approach, without any inductive bias on rotations, outperformed the two others, achieving a mAP of 57.53 on our dataset. Our use case demonstrates the limitations of region-based approaches for cluttered, elongated objects. It also highlights the potential of attention-based methods on this specific task, as they work directly at the pixel-level. These encouraging results indicate that such a perception system could be used to assist the operators on the short-term, or to fully automate log picking operations in the future.