 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReproducibility Study on Adversarial Attacks Against Robust Transformer Trackers
Jun 03, 2024New transformer networks have been integrated into object tracking pipelines and have demonstrated strong performance on the latest benchmarks. This paper focuses on understanding how transformer trackers behave under adversarial attacks and how different attacks perform on tracking datasets as their parameters change. We conducted a series of experiments to evaluate the effectiveness of existing adversarial attacks on object trackers with transformer and non-transformer backbones. We experimented on 7 different trackers, including 3 that are transformer-based, and 4 which leverage other architectures. These trackers are tested against 4 recent attack methods to assess their performance and robustness on VOT2022ST, UAV123 and GOT10k datasets. Our empirical study focuses on evaluating adversarial robustness of object trackers based on bounding box versus binary mask predictions, and attack methods at different levels of perturbations. Interestingly, our study found that altering the perturbation level may not significantly affect the overall object tracking results after the attack. Similarly, the sparsity and imperceptibility of the attack perturbations may remain stable against perturbation level shifts. By applying a specific attack on all transformer trackers, we show that new transformer trackers having a stronger cross-attention modeling achieve a greater adversarial robustness on tracking datasets, such as VOT2022ST and GOT10k. Our results also indicate the necessity for new attack methods to effectively tackle the latest types of transformer trackers. The codes necessary to reproduce this study are available at https://github.com/fatemehN/ReproducibilityStudy.
Towards a Perceptual Evaluation Framework for Lighting Estimation
Dec 13, 2023



Progress in lighting estimation is tracked by computing existing image quality assessment (IQA) metrics on images from standard datasets. While this may appear to be a reasonable approach, we demonstrate that doing so does not correlate to human preference when the estimated lighting is used to relight a virtual scene into a real photograph. To study this, we design a controlled psychophysical experiment where human observers must choose their preference amongst rendered scenes lit using a set of lighting estimation algorithms selected from the recent literature, and use it to analyse how these algorithms perform according to human perception. Then, we demonstrate that none of the most popular IQA metrics from the literature, taken individually, correctly represent human perception. Finally, we show that by learning a combination of existing IQA metrics, we can more accurately represent human preference. This provides a new perceptual framework to help evaluate future lighting estimation algorithms.
Domain Agnostic Image-to-image Translation using Low-Resolution Conditioning
May 11, 2023Generally, image-to-image translation (i2i) methods aim at learning mappings across domains with the assumption that the images used for translation share content (e.g., pose) but have their own domain-specific information (a.k.a. style). Conditioned on a target image, such methods extract the target style and combine it with the source image content, keeping coherence between the domains. In our proposal, we depart from this traditional view and instead consider the scenario where the target domain is represented by a very low-resolution (LR) image, proposing a domain-agnostic i2i method for fine-grained problems, where the domains are related. More specifically, our domain-agnostic approach aims at generating an image that combines visual features from the source image with low-frequency information (e.g. pose, color) of the LR target image. To do so, we present a novel approach that relies on training the generative model to produce images that both share distinctive information of the associated source image and correctly match the LR target image when downscaled. We validate our method on the CelebA-HQ and AFHQ datasets by demonstrating improvements in terms of visual quality. Qualitative and quantitative results show that when dealing with intra-domain image translation, our method generates realistic samples compared to state-of-the-art methods such as StarGAN v2. Ablation studies also reveal that our method is robust to changes in color, it can be applied to out-of-distribution images, and it allows for manual control over the final results.
EverLight: Indoor-Outdoor Editable HDR Lighting Estimation
Apr 26, 2023



Because of the diversity in lighting environments, existing illumination estimation techniques have been designed explicitly on indoor or outdoor environments. Methods have focused specifically on capturing accurate energy (e.g., through parametric lighting models), which emphasizes shading and strong cast shadows; or producing plausible texture (e.g., with GANs), which prioritizes plausible reflections. Approaches which provide editable lighting capabilities have been proposed, but these tend to be with simplified lighting models, offering limited realism. In this work, we propose to bridge the gap between these recent trends in the literature, and propose a method which combines a parametric light model with 360{\deg} panoramas, ready to use as HDRI in rendering engines. We leverage recent advances in GAN-based LDR panorama extrapolation from a regular image, which we extend to HDR using parametric spherical gaussians. To achieve this, we introduce a novel lighting co-modulation method that injects lighting-related features throughout the generator, tightly coupling the original or edited scene illumination within the panorama generation process. In our representation, users can easily edit light direction, intensity, number, etc. to impact shading while providing rich, complex reflections while seamlessly blending with the edits. Furthermore, our method encompasses indoor and outdoor environments, demonstrating state-of-the-art results even when compared to domain-specific methods.
Beyond the Pixel: a Photometrically Calibrated HDR Dataset for Luminance and Color Temperature Prediction
Apr 24, 2023Light plays an important role in human well-being. However, most computer vision tasks treat pixels without considering their relationship to physical luminance. To address this shortcoming, we present the first large-scale photometrically calibrated dataset of high dynamic range \ang{360} panoramas. Our key contribution is the calibration of an existing, uncalibrated HDR Dataset. We do so by accurately capturing RAW bracketed exposures simultaneously with a professional photometric measurement device (chroma meter) for multiple scenes across a variety of lighting conditions. Using the resulting measurements, we establish the calibration coefficients to be applied to the HDR images. The resulting dataset is a rich representation of indoor scenes which displays a wide range of illuminance and color temperature, and varied types of light sources. We exploit the dataset to introduce three novel tasks: where per-pixel luminance, per-pixel temperature and planar illuminance can be predicted from a single input image. Finally, we also capture another smaller calibrated dataset with a commercial \ang{360} camera, to experiment on generalization across cameras. We are optimistic that the release of our datasets and associated code will spark interest in physically accurate light estimation within the community.
Robust Unsupervised StyleGAN Image Restoration
Feb 13, 2023GAN-based image restoration inverts the generative process to repair images corrupted by known degradations. Existing unsupervised methods must be carefully tuned for each task and degradation level. In this work, we make StyleGAN image restoration robust: a single set of hyperparameters works across a wide range of degradation levels. This makes it possible to handle combinations of several degradations, without the need to retune. Our proposed approach relies on a 3-phase progressive latent space extension and a conservative optimizer, which avoids the need for any additional regularization terms. Extensive experiments demonstrate robustness on inpainting, upsampling, denoising, and deartifacting at varying degradations levels, outperforming other StyleGAN-based inversion techniques. Our approach also favorably compares to diffusion-based restoration by yielding much more realistic inversion results. Code will be released upon publication.
The Differentiable Lens: Compound Lens Search over Glass Surfaces and Materials for Object Detection
Dec 08, 2022Most camera lens systems are designed in isolation, separately from downstream computer vision methods. Recently, joint optimization approaches that design lenses alongside other components of the image acquisition and processing pipeline -- notably, downstream neural networks -- have achieved improved imaging quality or better performance on vision tasks. However, these existing methods optimize only a subset of lens parameters and cannot optimize glass materials given their categorical nature. In this work, we develop a differentiable spherical lens simulation model that accurately captures geometrical aberrations. We propose an optimization strategy to address the challenges of lens design -- notorious for non-convex loss function landscapes and many manufacturing constraints -- that are exacerbated in joint optimization tasks. Specifically, we introduce quantized continuous glass variables to facilitate the optimization and selection of glass materials in an end-to-end design context, and couple this with carefully designed constraints to support manufacturability. In automotive object detection, we show improved detection performance over existing designs even when simplifying designs to two- or three-element lenses, despite significantly degrading the image quality. Code and optical designs will be made publicly available.
Editable Indoor Lighting Estimation
Nov 09, 2022



We present a method for estimating lighting from a single perspective image of an indoor scene. Previous methods for predicting indoor illumination usually focus on either simple, parametric lighting that lack realism, or on richer representations that are difficult or even impossible to understand or modify after prediction. We propose a pipeline that estimates a parametric light that is easy to edit and allows renderings with strong shadows, alongside with a non-parametric texture with high-frequency information necessary for realistic rendering of specular objects. Once estimated, the predictions obtained with our model are interpretable and can easily be modified by an artist/user with a few mouse clicks. Quantitative and qualitative results show that our approach makes indoor lighting estimation easier to handle by a casual user, while still producing competitive results.
A Deep Perceptual Measure for Lens and Camera Calibration
Aug 25, 2022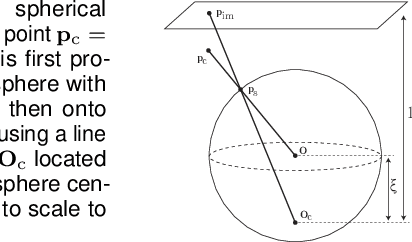


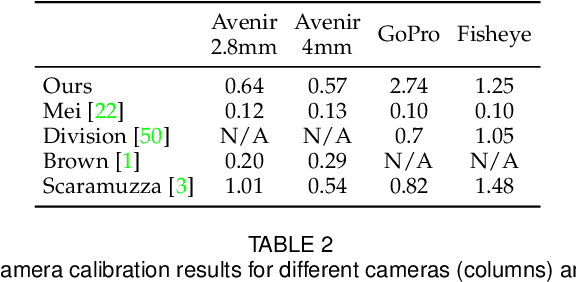
Image editing and compositing have become ubiquitous in entertainment, from digital art to AR and VR experiences. To produce beautiful composites, the camera needs to be geometrically calibrated, which can be tedious and requires a physical calibration target. In place of the traditional multi-images calibration process, we propose to infer the camera calibration parameters such as pitch, roll, field of view, and lens distortion directly from a single image using a deep convolutional neural network. We train this network using automatically generated samples from a large-scale panorama dataset, yielding competitive accuracy in terms of standard l2 error. However, we argue that minimizing such standard error metrics might not be optimal for many applications. In this work, we investigate human sensitivity to inaccuracies in geometric camera calibration. To this end, we conduct a large-scale human perception study where we ask participants to judge the realism of 3D objects composited with correct and biased camera calibration parameters. Based on this study, we develop a new perceptual measure for camera calibration and demonstrate that our deep calibration network outperforms previous single-image based calibration methods both on standard metrics as well as on this novel perceptual measure. Finally, we demonstrate the use of our calibration network for several applications, including virtual object insertion, image retrieval, and compositing. A demonstration of our approach is available at https://lvsn.github.io/deepcalib .
Casual Indoor HDR Radiance Capture from Omnidirectional Images
Aug 16, 2022
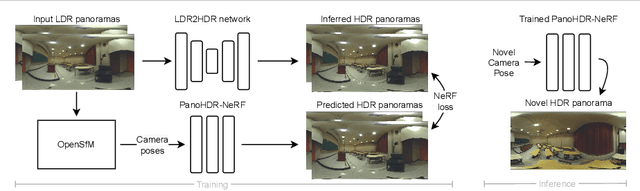


We present PanoHDR-NeRF, a novel pipeline to casually capture a plausible full HDR radiance field of a large indoor scene without elaborate setups or complex capture protocols. First, a user captures a low dynamic range (LDR) omnidirectional video of the scene by freely waving an off-the-shelf camera around the scene. Then, an LDR2HDR network uplifts the captured LDR frames to HDR, subsequently used to train a tailored NeRF++ model. The resulting PanoHDR-NeRF pipeline can estimate full HDR panoramas from any location of the scene. Through experiments on a novel test dataset of a variety of real scenes with the ground truth HDR radiance captured at locations not seen during training, we show that PanoHDR-NeRF predicts plausible radiance from any scene point. We also show that the HDR images produced by PanoHDR-NeRF can synthesize correct lighting effects, enabling the augmentation of indoor scenes with synthetic objects that are lit correctly.