 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Counterfactual Generators using Deep Model Inversion
Oct 05, 2021
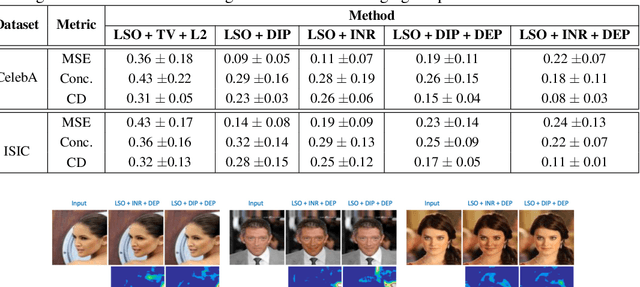

Explanation techniques that synthesize small, interpretable changes to a given image while producing desired changes in the model prediction have become popular for introspecting black-box models. Commonly referred to as counterfactuals, the synthesized explanations are required to contain discernible changes (for easy interpretability) while also being realistic (consistency to the data manifold). In this paper, we focus on the case where we have access only to the trained deep classifier and not the actual training data. While the problem of inverting deep models to synthesize images from the training distribution has been explored, our goal is to develop a deep inversion approach to generate counterfactual explanations for a given query image. Despite their effectiveness in conditional image synthesis, we show that existing deep inversion methods are insufficient for producing meaningful counterfactuals. We propose DISC (Deep Inversion for Synthesizing Counterfactuals) that improves upon deep inversion by utilizing (a) stronger image priors, (b) incorporating a novel manifold consistency objective and (c) adopting a progressive optimization strategy. We find that, in addition to producing visually meaningful explanations, the counterfactuals from DISC are effective at learning classifier decision boundaries and are robust to unknown test-time corruptions.
Transfer learning suppresses simulation bias in predictive models built from sparse, multi-modal data
Apr 19, 2021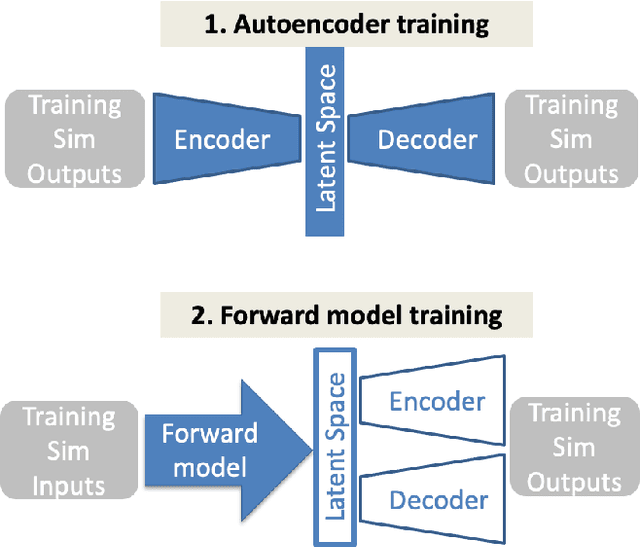
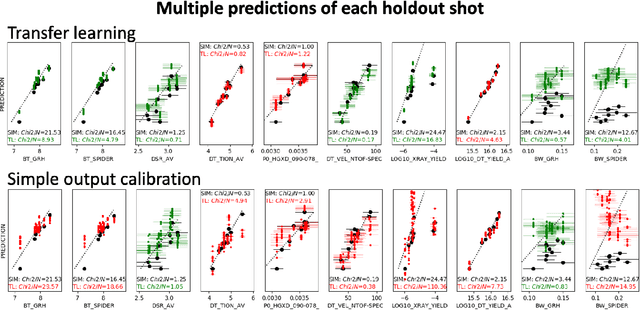
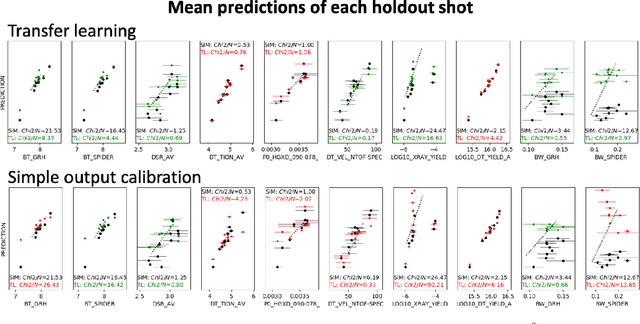
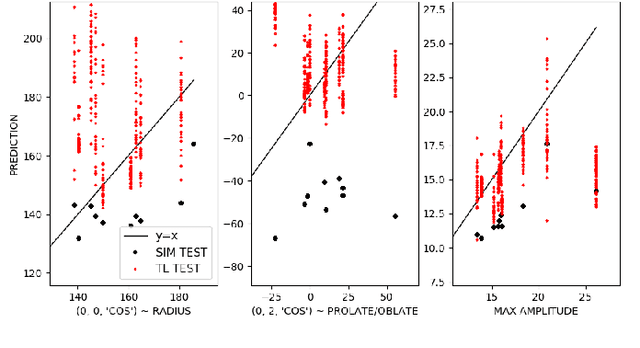
Many problems in science, engineering, and business require making predictions based on very few observations. To build a robust predictive model, these sparse data may need to be augmented with simulated data, especially when the design space is multidimensional. Simulations, however, often suffer from an inherent bias. Estimation of this bias may be poorly constrained not only because of data sparsity, but also because traditional predictive models fit only one type of observations, such as scalars or images, instead of all available data modalities, which might have been acquired and simulated at great cost. We combine recent developments in deep learning to build more robust predictive models from multimodal data with a recent, novel technique to suppress the bias, and extend it to take into account multiple data modalities. First, an initial, simulation-trained, neural network surrogate model learns important correlations between different data modalities and between simulation inputs and outputs. Then, the model is partially retrained, or transfer learned, to fit the observations. Using fewer than 10 inertial confinement fusion experiments for retraining, we demonstrate that this technique systematically improves simulation predictions while a simple output calibration makes predictions worse. We also offer extensive cross-validation with real and synthetic data to support our findings. The transfer learning method can be applied to other problems that require transferring knowledge from simulations to the domain of real observations. This paper opens up the path to model calibration using multiple data types, which have traditionally been ignored in predictive models.
On the Design of Deep Priors for Unsupervised Audio Restoration
Apr 14, 2021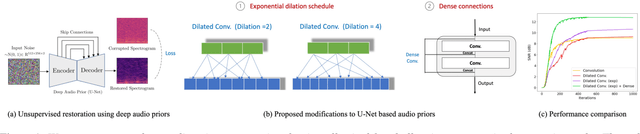
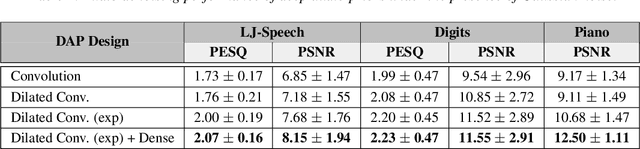
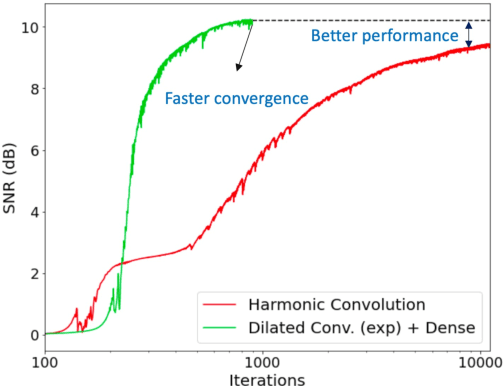
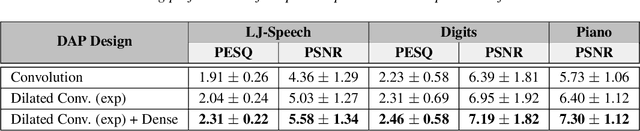
Unsupervised deep learning methods for solving audio restoration problems extensively rely on carefully tailored neural architectures that carry strong inductive biases for defining priors in the time or spectral domain. In this context, lot of recent success has been achieved with sophisticated convolutional network constructions that recover audio signals in the spectral domain. However, in practice, audio priors require careful engineering of the convolutional kernels to be effective at solving ill-posed restoration tasks, while also being easy to train. To this end, in this paper, we propose a new U-Net based prior that does not impact either the network complexity or convergence behavior of existing convolutional architectures, yet leads to significantly improved restoration. In particular, we advocate the use of carefully designed dilation schedules and dense connections in the U-Net architecture to obtain powerful audio priors. Using empirical studies on standard benchmarks and a variety of ill-posed restoration tasks, such as audio denoising, in-painting and source separation, we demonstrate that our proposed approach consistently outperforms widely adopted audio prior architectures.
Loss Estimators Improve Model Generalization
Mar 05, 2021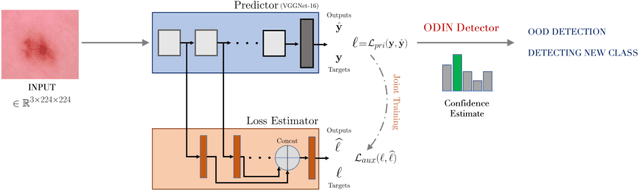
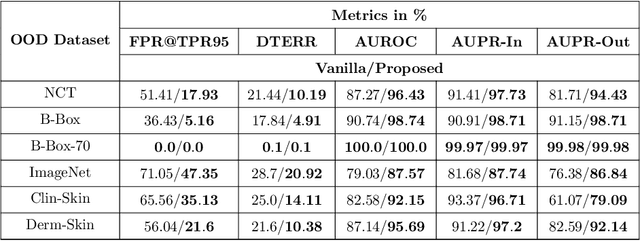
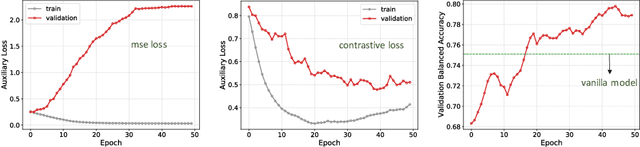
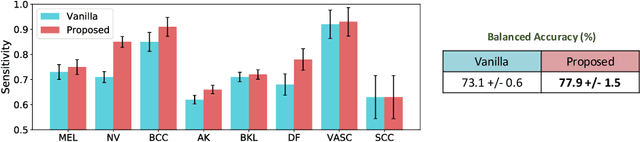
With increased interest in adopting AI methods for clinical diagnosis, a vital step towards safe deployment of such tools is to ensure that the models not only produce accurate predictions but also do not generalize to data regimes where the training data provide no meaningful evidence. Existing approaches for ensuring the distribution of model predictions to be similar to that of the true distribution rely on explicit uncertainty estimators that are inherently hard to calibrate. In this paper, we propose to train a loss estimator alongside the predictive model, using a contrastive training objective, to directly estimate the prediction uncertainties. Interestingly, we find that, in addition to producing well-calibrated uncertainties, this approach improves the generalization behavior of the predictor. Using a dermatology use-case, we show the impact of loss estimators on model generalization, in terms of both its fidelity on in-distribution data and its ability to detect out of distribution samples or new classes unseen during training.
Comparative Code Structure Analysis using Deep Learning for Performance Prediction
Feb 12, 2021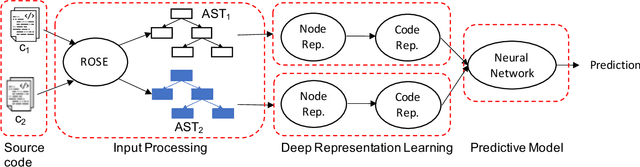
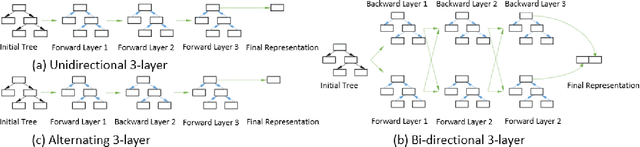
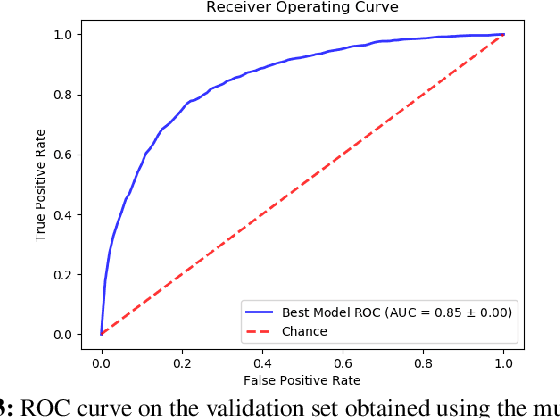
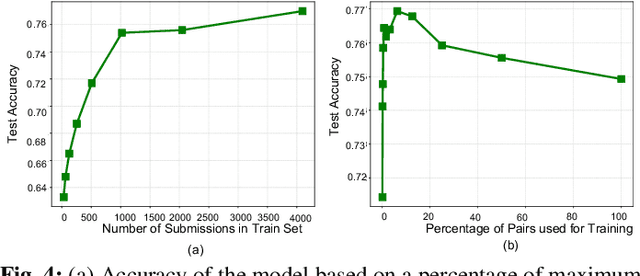
Performance analysis has always been an afterthought during the application development process, focusing on application correctness first. The learning curve of the existing static and dynamic analysis tools are steep, which requires understanding low-level details to interpret the findings for actionable optimizations. Additionally, application performance is a function of an infinite number of unknowns stemming from the application-, runtime-, and interactions between the OS and underlying hardware, making it difficult, if not impossible, to model using any deep learning technique, especially without a large labeled dataset. In this paper, we address both of these problems by presenting a large corpus of a labeled dataset for the community and take a comparative analysis approach to mitigate all unknowns except their source code differences between different correct implementations of the same problem. We put the power of deep learning to the test for automatically extracting information from the hierarchical structure of abstract syntax trees to represent source code. This paper aims to assess the feasibility of using purely static information (e.g., abstract syntax tree or AST) of applications to predict performance change based on the change in code structure. This research will enable performance-aware application development since every version of the application will continue to contribute to the corpora, which will enhance the performance of the model. Our evaluations of several deep embedding learning methods demonstrate that tree-based Long Short-Term Memory (LSTM) models can leverage the hierarchical structure of source-code to discover latent representations and achieve up to 84% (individual problem) and 73% (combined dataset with multiple of problems) accuracy in predicting the change in performance.
Attribute-Guided Adversarial Training for Robustness to Natural Perturbations
Dec 03, 2020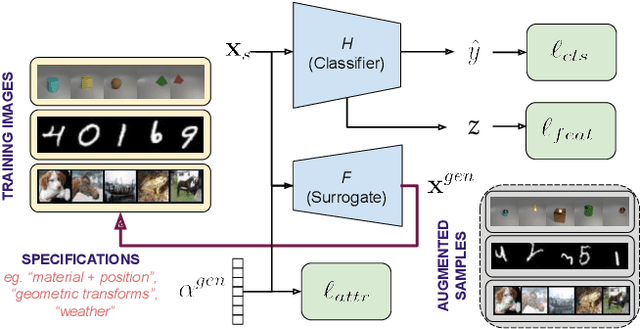
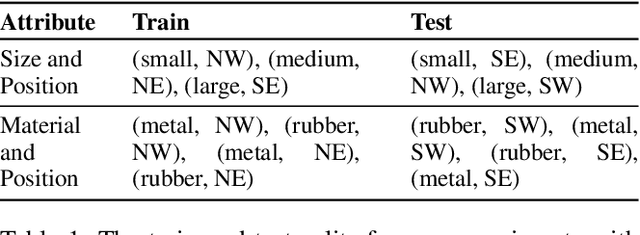

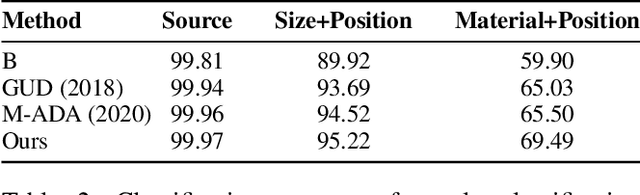
While existing work in robust deep learning has focused on small pixel-level $\ell_p$ norm-based perturbations, this may not account for perturbations encountered in several real world settings. In many such cases although test data might not be available, broad specifications about the types of perturbations (such as an unknown degree of rotation) may be known. We consider a setup where robustness is expected over an unseen test domain that is not i.i.d. but deviates from the training domain. While this deviation may not be exactly known, its broad characterization is specified a priori, in terms of attributes. We propose an adversarial training approach which learns to generate new samples so as to maximize exposure of the classifier to the attributes-space, without having access to the data from the test domain. Our adversarial training solves a min-max optimization problem, with the inner maximization generating adversarial perturbations, and the outer minimization finding model parameters by optimizing the loss on adversarial perturbations generated from the inner maximization. We demonstrate the applicability of our approach on three types of naturally occurring perturbations -- object-related shifts, geometric transformations, and common image corruptions. Our approach enables deep neural networks to be robust against a wide range of naturally occurring perturbations. We demonstrate the usefulness of the proposed approach by showing the robustness gains of deep neural networks trained using our adversarial training on MNIST, CIFAR-10, and a new variant of the CLEVR dataset.
Meaningful uncertainties from deep neural network surrogates of large-scale numerical simulations
Oct 26, 2020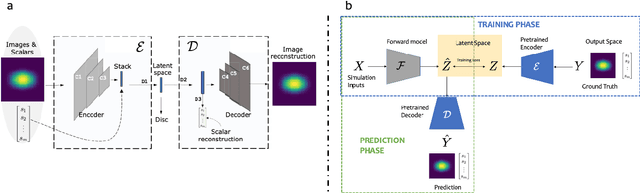
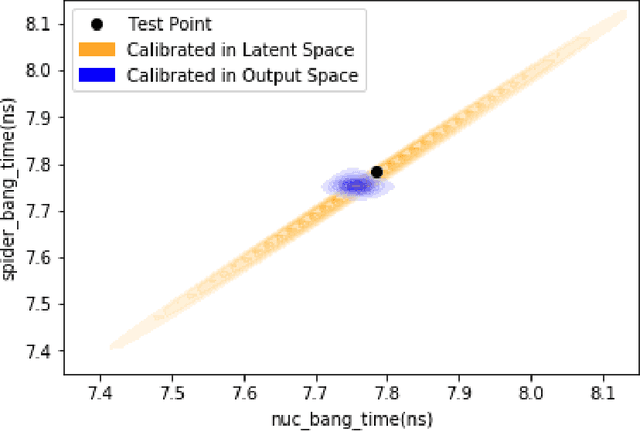
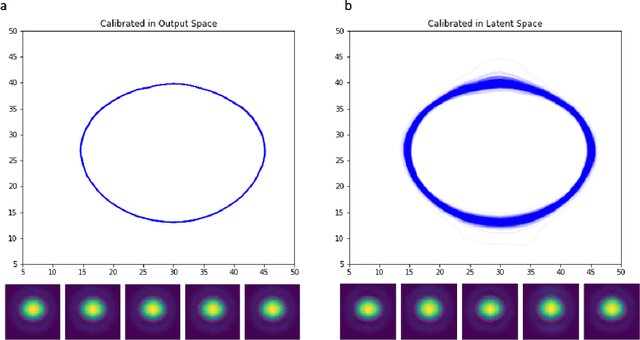
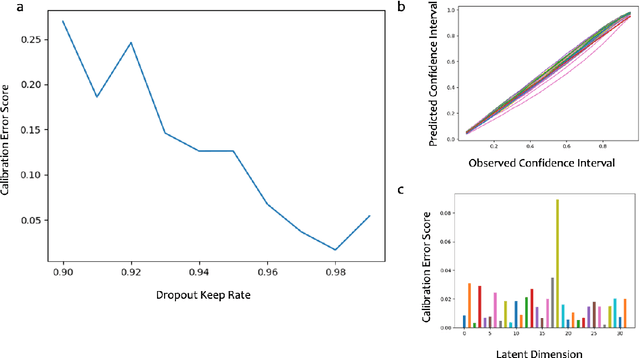
Large-scale numerical simulations are used across many scientific disciplines to facilitate experimental development and provide insights into underlying physical processes, but they come with a significant computational cost. Deep neural networks (DNNs) can serve as highly-accurate surrogate models, with the capacity to handle diverse datatypes, offering tremendous speed-ups for prediction and many other downstream tasks. An important use-case for these surrogates is the comparison between simulations and experiments; prediction uncertainty estimates are crucial for making such comparisons meaningful, yet standard DNNs do not provide them. In this work we define the fundamental requirements for a DNN to be useful for scientific applications, and demonstrate a general variational inference approach to equip predictions of scalar and image data from a DNN surrogate model trained on inertial confinement fusion simulations with calibrated Bayesian uncertainties. Critically, these uncertainties are interpretable, meaningful and preserve physics-correlations in the predicted quantities.
Using Deep Image Priors to Generate Counterfactual Explanations
Oct 22, 2020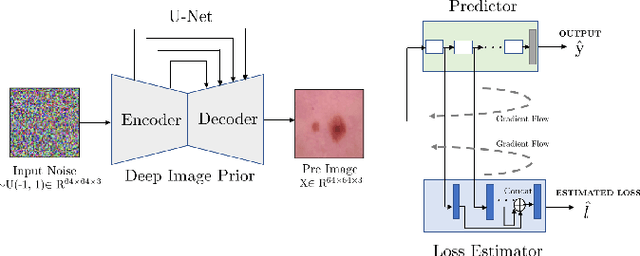

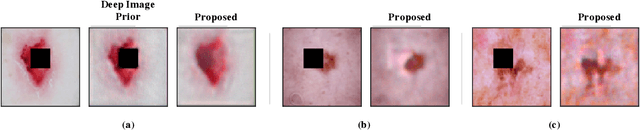
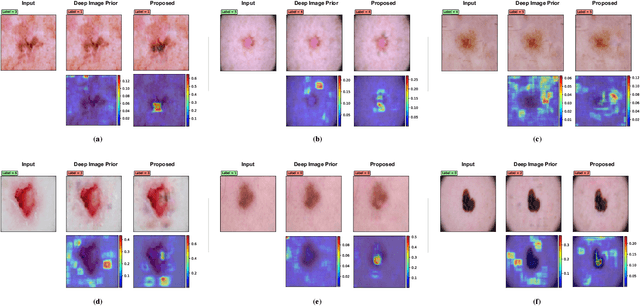
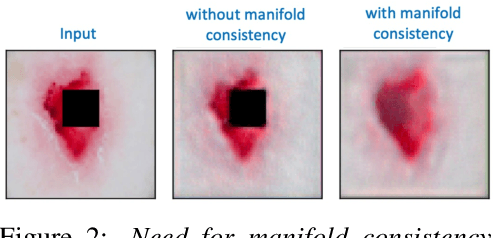
Through the use of carefully tailored convolutional neural network architectures, a deep image prior (DIP) can be used to obtain pre-images from latent representation encodings. Though DIP inversion has been known to be superior to conventional regularized inversion strategies such as total variation, such an over-parameterized generator is able to effectively reconstruct even images that are not in the original data distribution. This limitation makes it challenging to utilize such priors for tasks such as counterfactual reasoning, wherein the goal is to generate small, interpretable changes to an image that systematically leads to changes in the model prediction. To this end, we propose a novel regularization strategy based on an auxiliary loss estimator jointly trained with the predictor, which efficiently guides the prior to recover natural pre-images. Our empirical studies with a real-world ISIC skin lesion detection problem clearly evidence the effectiveness of the proposed approach in synthesizing meaningful counterfactuals. In comparison, we find that the standard DIP inversion often proposes visually imperceptible perturbations to irrelevant parts of the image, thus providing no additional insights into the model behavior.
Machine Learning-Powered Mitigation Policy Optimization in Epidemiological Models
Oct 16, 2020
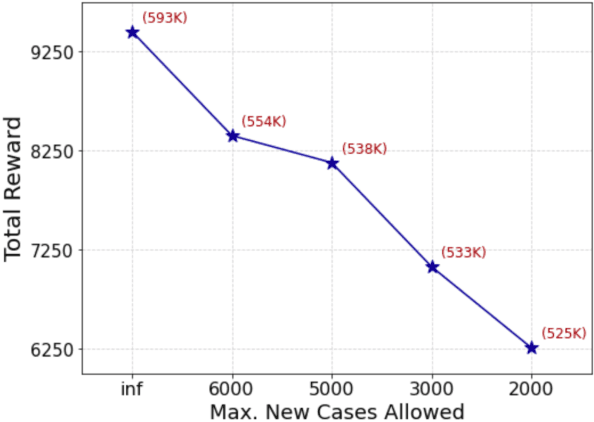

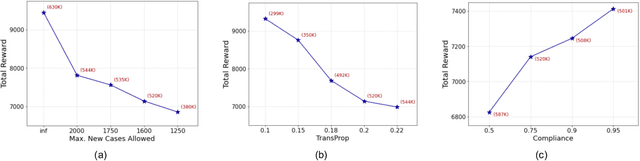
A crucial aspect of managing a public health crisis is to effectively balance prevention and mitigation strategies, while taking their socio-economic impact into account. In particular, determining the influence of different non-pharmaceutical interventions (NPIs) on the effective use of public resources is an important problem, given the uncertainties on when a vaccine will be made available. In this paper, we propose a new approach for obtaining optimal policy recommendations based on epidemiological models, which can characterize the disease progression under different interventions, and a look-ahead reward optimization strategy to choose the suitable NPI at different stages of an epidemic. Given the time delay inherent in any epidemiological model and the exponential nature especially of an unmanaged epidemic, we find that such a look-ahead strategy infers non-trivial policies that adhere well to the constraints specified. Using two different epidemiological models, namely SEIR and EpiCast, we evaluate the proposed algorithm to determine the optimal NPI policy, under a constraint on the number of daily new cases and the primary reward being the absence of restrictions.
Accurate Calibration of Agent-based Epidemiological Models with Neural Network Surrogates
Oct 13, 2020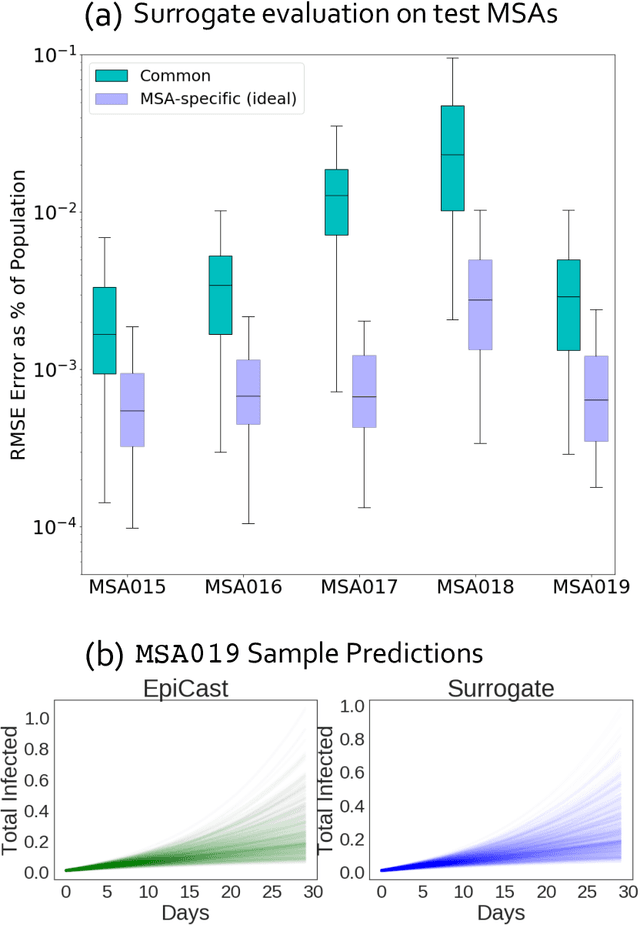

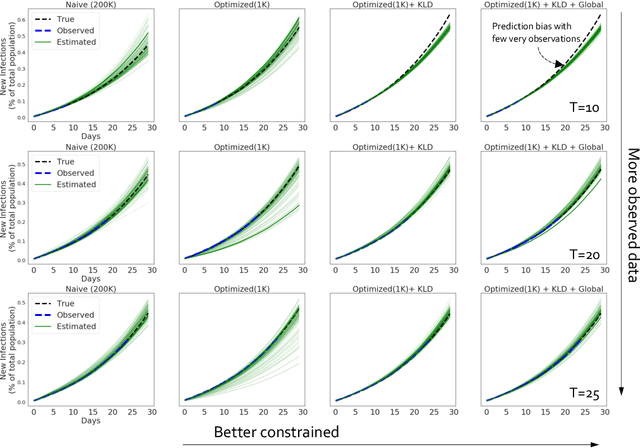

Calibrating complex epidemiological models to observed data is a crucial step to provide both insights into the current disease dynamics, i.e.\ by estimating a reproductive number, as well as to provide reliable forecasts and scenario explorations. Here we present a new approach to calibrate an agent-based model -- EpiCast -- using a large set of simulation ensembles for different major metropolitan areas of the United States. In particular, we propose: a new neural network based surrogate model able to simultaneously emulate all different locations; and a novel posterior estimation that provides not only more accurate posterior estimates of all parameters but enables the joint fitting of global parameters across regions.