 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShapeClipper: Scalable 3D Shape Learning from Single-View Images via Geometric and CLIP-based Consistency
Apr 13, 2023



We present ShapeClipper, a novel method that reconstructs 3D object shapes from real-world single-view RGB images. Instead of relying on laborious 3D, multi-view or camera pose annotation, ShapeClipper learns shape reconstruction from a set of single-view segmented images. The key idea is to facilitate shape learning via CLIP-based shape consistency, where we encourage objects with similar CLIP encodings to share similar shapes. We also leverage off-the-shelf normals as an additional geometric constraint so the model can learn better bottom-up reasoning of detailed surface geometry. These two novel consistency constraints, when used to regularize our model, improve its ability to learn both global shape structure and local geometric details. We evaluate our method over three challenging real-world datasets, Pix3D, Pascal3D+, and OpenImages, where we achieve superior performance over state-of-the-art methods.
Egocentric Auditory Attention Localization in Conversations
Mar 28, 2023



In a noisy conversation environment such as a dinner party, people often exhibit selective auditory attention, or the ability to focus on a particular speaker while tuning out others. Recognizing who somebody is listening to in a conversation is essential for developing technologies that can understand social behavior and devices that can augment human hearing by amplifying particular sound sources. The computer vision and audio research communities have made great strides towards recognizing sound sources and speakers in scenes. In this work, we take a step further by focusing on the problem of localizing auditory attention targets in egocentric video, or detecting who in a camera wearer's field of view they are listening to. To tackle the new and challenging Selective Auditory Attention Localization problem, we propose an end-to-end deep learning approach that uses egocentric video and multichannel audio to predict the heatmap of the camera wearer's auditory attention. Our approach leverages spatiotemporal audiovisual features and holistic reasoning about the scene to make predictions, and outperforms a set of baselines on a challenging multi-speaker conversation dataset. Project page: https://fkryan.github.io/saal
Werewolf Among Us: A Multimodal Dataset for Modeling Persuasion Behaviors in Social Deduction Games
Dec 16, 2022



Persuasion modeling is a key building block for conversational agents. Existing works in this direction are limited to analyzing textual dialogue corpus. We argue that visual signals also play an important role in understanding human persuasive behaviors. In this paper, we introduce the first multimodal dataset for modeling persuasion behaviors. Our dataset includes 199 dialogue transcriptions and videos captured in a multi-player social deduction game setting, 26,647 utterance level annotations of persuasion strategy, and game level annotations of deduction game outcomes. We provide extensive experiments to show how dialogue context and visual signals benefit persuasion strategy prediction. We also explore the generalization ability of language models for persuasion modeling and the role of persuasion strategies in predicting social deduction game outcomes. Our dataset, code, and models can be found at https://persuasion-deductiongame.socialai-data.org.
PulseImpute: A Novel Benchmark Task for Pulsative Physiological Signal Imputation
Dec 14, 2022The promise of Mobile Health (mHealth) is the ability to use wearable sensors to monitor participant physiology at high frequencies during daily life to enable temporally-precise health interventions. However, a major challenge is frequent missing data. Despite a rich imputation literature, existing techniques are ineffective for the pulsative signals which comprise many mHealth applications, and a lack of available datasets has stymied progress. We address this gap with PulseImpute, the first large-scale pulsative signal imputation challenge which includes realistic mHealth missingness models, an extensive set of baselines, and clinically-relevant downstream tasks. Our baseline models include a novel transformer-based architecture designed to exploit the structure of pulsative signals. We hope that PulseImpute will enable the ML community to tackle this significant and challenging task.
Learning Dense Object Descriptors from Multiple Views for Low-shot Category Generalization
Nov 28, 2022A hallmark of the deep learning era for computer vision is the successful use of large-scale labeled datasets to train feature representations for tasks ranging from object recognition and semantic segmentation to optical flow estimation and novel view synthesis of 3D scenes. In this work, we aim to learn dense discriminative object representations for low-shot category recognition without requiring any category labels. To this end, we propose Deep Object Patch Encodings (DOPE), which can be trained from multiple views of object instances without any category or semantic object part labels. To train DOPE, we assume access to sparse depths, foreground masks and known cameras, to obtain pixel-level correspondences between views of an object, and use this to formulate a self-supervised learning task to learn discriminative object patches. We find that DOPE can directly be used for low-shot classification of novel categories using local-part matching, and is competitive with and outperforms supervised and self-supervised learning baselines. Code and data available at https://github.com/rehg-lab/dope_selfsup.
Transformer-based Localization from Embodied Dialog with Large-scale Pre-training
Oct 10, 2022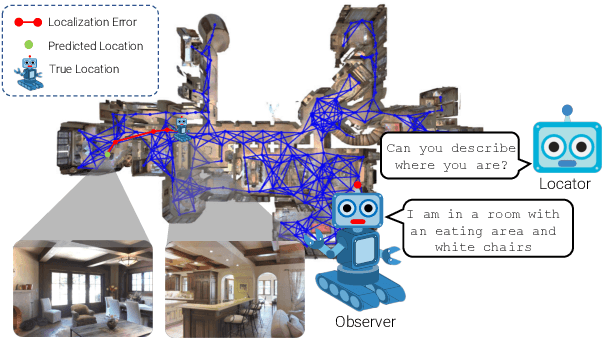
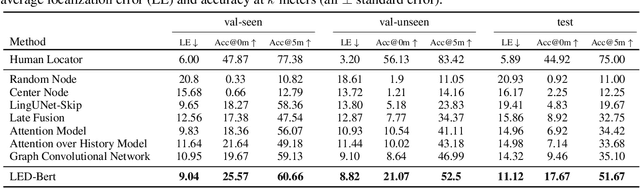
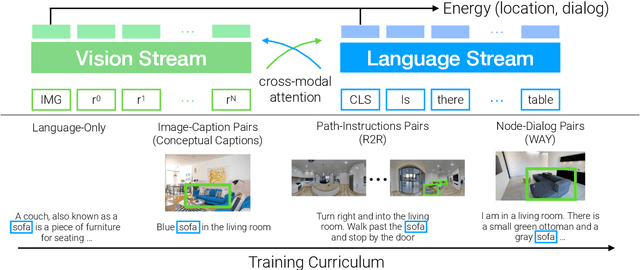
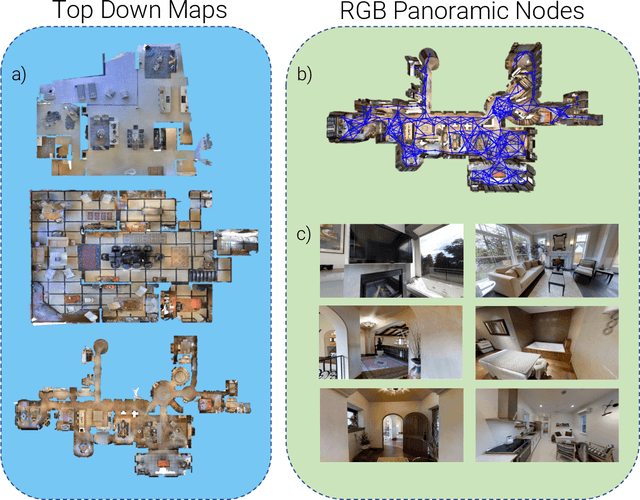
We address the challenging task of Localization via Embodied Dialog (LED). Given a dialog from two agents, an Observer navigating through an unknown environment and a Locator who is attempting to identify the Observer's location, the goal is to predict the Observer's final location in a map. We develop a novel LED-Bert architecture and present an effective pretraining strategy. We show that a graph-based scene representation is more effective than the top-down 2D maps used in prior works. Our approach outperforms previous baselines.
In the Eye of Transformer: Global-Local Correlation for Egocentric Gaze Estimation
Aug 10, 2022
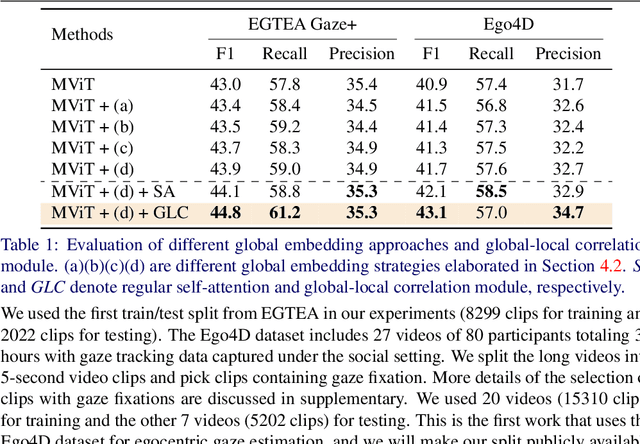
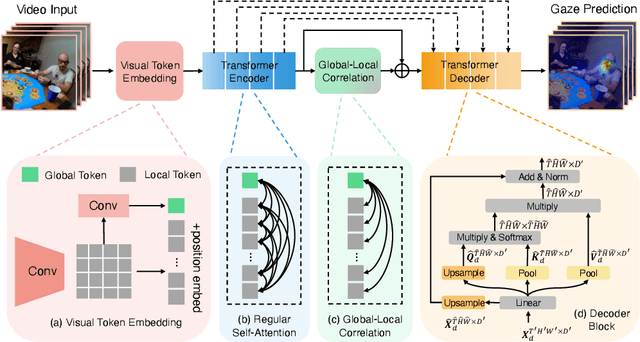
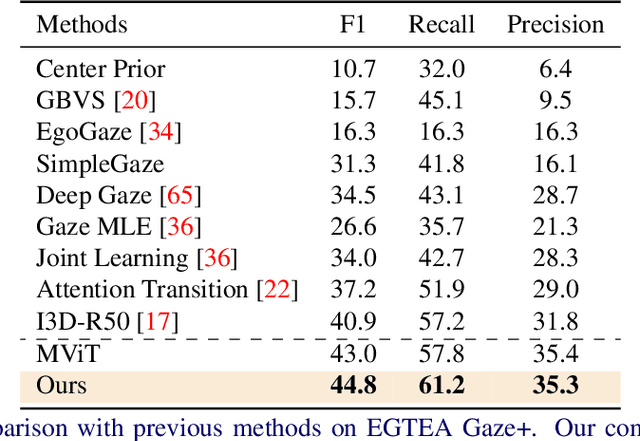
In this paper, we present the first transformer-based model to address the challenging problem of egocentric gaze estimation. We observe that the connection between the global scene context and local visual information is vital for localizing the gaze fixation from egocentric video frames. To this end, we design the transformer encoder to embed the global context as one additional visual token and further propose a novel Global-Local Correlation (GLC) module to explicitly model the correlation of the global token and each local token. We validate our model on two egocentric video datasets - EGTEA Gaze+ and Ego4D. Our detailed ablation studies demonstrate the benefits of our method. In addition, our approach exceeds previous state-of-the-arts by a large margin. We also provide additional visualizations to support our claim that global-local correlation serves a key representation for predicting gaze fixation from egocentric videos. More details can be found in our website (https://bolinlai.github.io/GLC-EgoGazeEst).
Planes vs. Chairs: Category-guided 3D shape learning without any 3D cues
Apr 21, 2022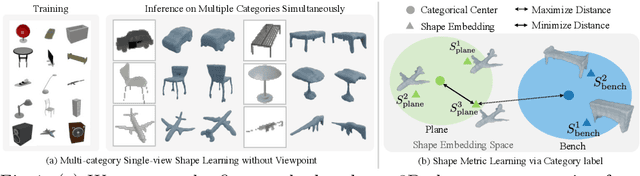

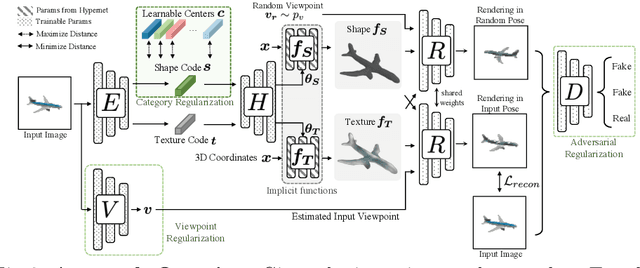
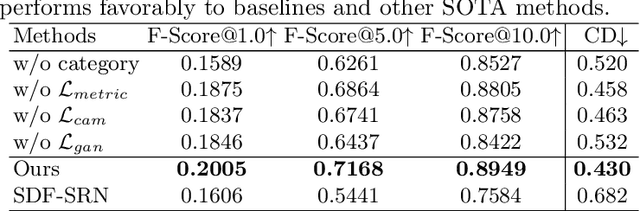
We present a novel 3D shape reconstruction method which learns to predict an implicit 3D shape representation from a single RGB image. Our approach uses a set of single-view images of multiple object categories without viewpoint annotation, forcing the model to learn across multiple object categories without 3D supervision. To facilitate learning with such minimal supervision, we use category labels to guide shape learning with a novel categorical metric learning approach. We also utilize adversarial and viewpoint regularization techniques to further disentangle the effects of viewpoint and shape. We obtain the first results for large-scale (more than 50 categories) single-viewpoint shape prediction using a single model without any 3D cues. We are also the first to examine and quantify the benefit of class information in single-view supervised 3D shape reconstruction. Our method achieves superior performance over state-of-the-art methods on ShapeNet-13, ShapeNet-55 and Pascal3D+.
Generative Adversarial Network for Future Hand Segmentation from Egocentric Video
Mar 21, 2022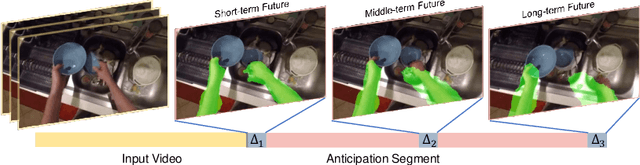
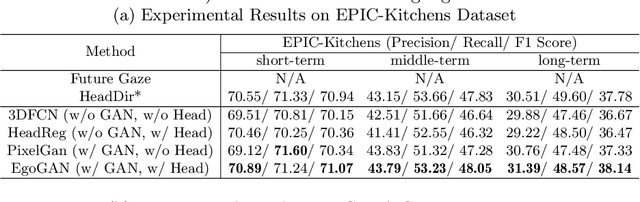
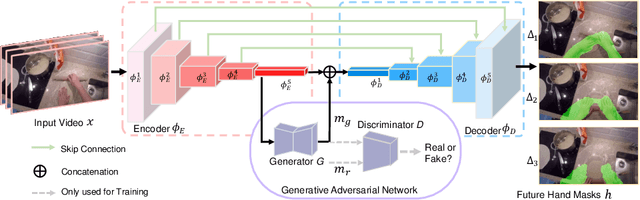
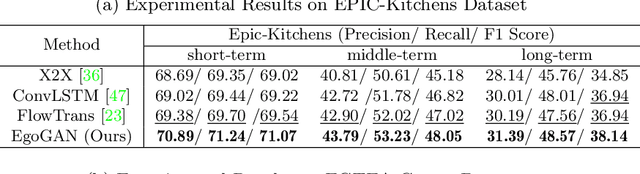
We introduce the novel problem of anticipating a time series of future hand masks from egocentric video. A key challenge is to model the stochasticity of future head motions, which globally impact the head-worn camera video analysis. To this end, we propose a novel deep generative model -- EgoGAN, which uses a 3D Fully Convolutional Network to learn a spatio-temporal video representation for pixel-wise visual anticipation, generates future head motion using Generative Adversarial Network (GAN), and then predicts the future hand masks based on the video representation and the generated future head motion. We evaluate our method on both the EPIC-Kitchens and the EGTEA Gaze+ datasets. We conduct detailed ablation studies to validate the design choices of our approach. Furthermore, we compare our method with previous state-of-the-art methods on future image segmentation and show that our method can more accurately predict future hand masks.
Kernel Deformed Exponential Families for Sparse Continuous Attention
Nov 12, 2021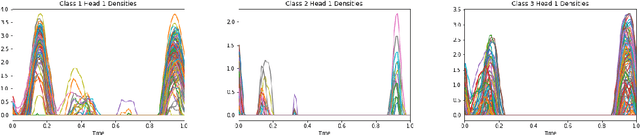
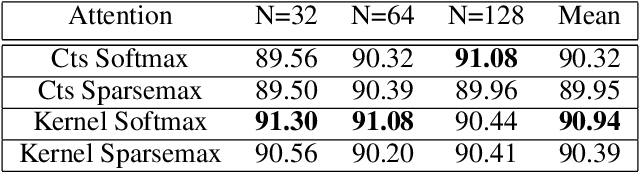
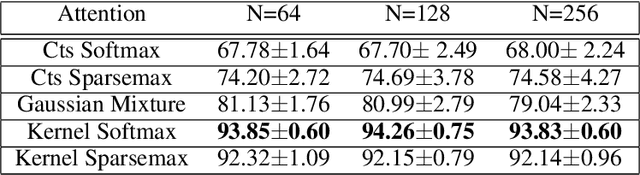
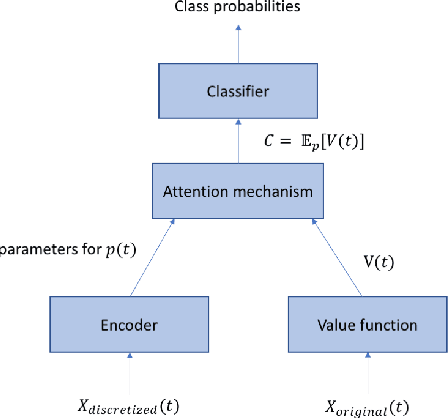
Attention mechanisms take an expectation of a data representation with respect to probability weights. This creates summary statistics that focus on important features. Recently, (Martins et al. 2020, 2021) proposed continuous attention mechanisms, focusing on unimodal attention densities from the exponential and deformed exponential families: the latter has sparse support. (Farinhas et al. 2021) extended this to use Gaussian mixture attention densities, which are a flexible class with dense support. In this paper, we extend this to two general flexible classes: kernel exponential families and our new sparse counterpart kernel deformed exponential families. Theoretically, we show new existence results for both kernel exponential and deformed exponential families, and that the deformed case has similar approximation capabilities to kernel exponential families. Experiments show that kernel deformed exponential families can attend to multiple compact regions of the data domain.