 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA plug-and-play approach with fast uncertainty quantification for weak lensing mass mapping
Mar 23, 2026Upcoming stage-IV surveys such as Euclid and Rubin will deliver vast amounts of high-precision data, opening new opportunities to constrain cosmological models with unprecedented accuracy. A key step in this process is the reconstruction of the dark matter distribution from noisy weak lensing shear measurements. Current deep learning-based mass mapping methods achieve high reconstruction accuracy, but either require retraining a model for each new observed sky region (limiting practicality) or rely on slow MCMC sampling. Efficient exploitation of future survey data therefore calls for a new method that is accurate, flexible, and fast at inference. In addition, uncertainty quantification with coverage guarantees is essential for reliable cosmological parameter estimation. We introduce PnPMass, a plug-and-play approach for weak lensing mass mapping. The algorithm produces point estimates by alternating between a gradient descent step with a carefully chosen data fidelity term, and a denoising step implemented with a single deep learning model trained on simulated data corrupted by Gaussian white noise. We also propose a fast, sampling-free uncertainty quantification scheme based on moment networks, with calibrated error bars obtained through conformal prediction to ensure coverage guarantees. Finally, we benchmark PnPMass against both model-driven and data-driven mass mapping techniques. PnPMass achieves performance close to that of state-of-the-art deep-learning methods while offering fast inference (converging in just a few iterations) and requiring only a single training phase, independently of the noise covariance of the observations. It therefore combines flexibility, efficiency, and reconstruction accuracy, while delivering tighter error bars than existing approaches, making it well suited for upcoming weak lensing surveys.
Neutrino Oscillation Parameter Estimation Using Structured Hierarchical Transformers
Mar 21, 2026Neutrino oscillations encode fundamental information about neutrino masses and mixing parameters, offering a unique window into physics beyond the Standard Model. Estimating these parameters from oscillation probability maps is, however, computationally challenging due to the maps' high dimensionality and nonlinear dependence on the underlying physics. Traditional inference methods, such as likelihood-based or Monte Carlo sampling approaches, require extensive simulations to explore the parameter space, creating major bottlenecks for large-scale analyses. In this work, we introduce a data-driven framework that reformulates atmospheric neutrino oscillation parameter inference as a supervised regression task over structured oscillation maps. We propose a hierarchical transformer architecture that explicitly models the two-dimensional structure of these maps, capturing angular dependencies at fixed energies and global correlations across the energy spectrum. To improve physical consistency, the model is trained using a surrogate simulation constraint that enforces agreement between the predicted parameters and the reconstructed oscillation patterns. Furthermore, we introduce a neural network-based uncertainty quantification mechanism that produces distribution-free prediction intervals with formal coverage guarantees. Experiments on simulated oscillation maps under Earth-matter conditions demonstrate that the proposed method is comparable to a Markov Chain Monte Carlo baseline in estimation accuracy, with substantial improvements in computational cost (around 240$\times$ fewer FLOPs and 33$\times$ faster in average processing time). Moreover, the conformally calibrated prediction intervals remain narrow while achieving the target nominal coverage of 90%, confirming both the reliability and efficiency of our approach.
Towards Uncertainty Quantification in Generative Model Learning
Nov 13, 2025While generative models have become increasingly prevalent across various domains, fundamental concerns regarding their reliability persist. A crucial yet understudied aspect of these models is the uncertainty quantification surrounding their distribution approximation capabilities. Current evaluation methodologies focus predominantly on measuring the closeness between the learned and the target distributions, neglecting the inherent uncertainty in these measurements. In this position paper, we formalize the problem of uncertainty quantification in generative model learning. We discuss potential research directions, including the use of ensemble-based precision-recall curves. Our preliminary experiments on synthetic datasets demonstrate the effectiveness of aggregated precision-recall curves in capturing model approximation uncertainty, enabling systematic comparison among different model architectures based on their uncertainty characteristics.
Low Complexity Regularized Phase Retrieval
Jul 23, 2024



In this paper, we study the phase retrieval problem in the situation where the vector to be recovered has an a priori structure that can encoded into a regularization term. This regularizer is intended to promote solutions conforming to some notion of simplicity or low complexity. We investigate both noiseless recovery and stability to noise and provide a very general and unified analysis framework that goes far beyond the sparse phase retrieval mostly considered in the literature. In the noiseless case we provide sufficient conditions under which exact recovery, up to global sign change, is possible. For Gaussian measurement maps, we also provide a sample complexity bound for exact recovery. This bound depends on the Gaussian width of the descent cone at the soughtafter vector which is a geometric measure of the complexity of the latter. In the noisy case, we consider both the constrained (Mozorov) and penalized (Tikhonov) formulations. We provide sufficient conditions for stable recovery and prove linear convergence for sufficiently small noise. For Gaussian measurements, we again give a sample complexity bound for linear convergence to hold with high probability. This bound scales linearly in the intrinsic dimension of the sought-after vector but only logarithmically in the ambient dimension.
Stable Phase Retrieval with Mirror Descent
May 17, 2024In this paper, we aim to reconstruct an n-dimensional real vector from m phaseless measurements corrupted by an additive noise. We extend the noiseless framework developed in [15], based on mirror descent (or Bregman gradient descent), to deal with noisy measurements and prove that the procedure is stable to (small enough) additive noise. In the deterministic case, we show that mirror descent converges to a critical point of the phase retrieval problem, and if the algorithm is well initialized and the noise is small enough, the critical point is near the true vector up to a global sign change. When the measurements are i.i.d Gaussian and the signal-to-noise ratio is large enough, we provide global convergence guarantees that ensure that with high probability, mirror descent converges to a global minimizer near the true vector (up to a global sign change), as soon as the number of measurements m is large enough. The sample complexity bound can be improved if a spectral method is used to provide a good initial guess. We complement our theoretical study with several numerical results showing that mirror descent is both a computationally and statistically efficient scheme to solve the phase retrieval problem.
Learning-to-Optimize with PAC-Bayesian Guarantees: Theoretical Considerations and Practical Implementation
Apr 04, 2024



We use the PAC-Bayesian theory for the setting of learning-to-optimize. To the best of our knowledge, we present the first framework to learn optimization algorithms with provable generalization guarantees (PAC-Bayesian bounds) and explicit trade-off between convergence guarantees and convergence speed, which contrasts with the typical worst-case analysis. Our learned optimization algorithms provably outperform related ones derived from a (deterministic) worst-case analysis. The results rely on PAC-Bayesian bounds for general, possibly unbounded loss-functions based on exponential families. Then, we reformulate the learning procedure into a one-dimensional minimization problem and study the possibility to find a global minimum. Furthermore, we provide a concrete algorithmic realization of the framework and new methodologies for learning-to-optimize, and we conduct four practically relevant experiments to support our theory. With this, we showcase that the provided learning framework yields optimization algorithms that provably outperform the state-of-the-art by orders of magnitude.
Recovery Guarantees of Unsupervised Neural Networks for Inverse Problems trained with Gradient Descent
Mar 08, 2024



Advanced machine learning methods, and more prominently neural networks, have become standard to solve inverse problems over the last years. However, the theoretical recovery guarantees of such methods are still scarce and difficult to achieve. Only recently did unsupervised methods such as Deep Image Prior (DIP) get equipped with convergence and recovery guarantees for generic loss functions when trained through gradient flow with an appropriate initialization. In this paper, we extend these results by proving that these guarantees hold true when using gradient descent with an appropriately chosen step-size/learning rate. We also show that the discretization only affects the overparametrization bound for a two-layer DIP network by a constant and thus that the different guarantees found for the gradient flow will hold for gradient descent.
Convergence and Recovery Guarantees of Unsupervised Neural Networks for Inverse Problems
Sep 21, 2023


Neural networks have become a prominent approach to solve inverse problems in recent years. While a plethora of such methods was developed to solve inverse problems empirically, we are still lacking clear theoretical guarantees for these methods. On the other hand, many works proved convergence to optimal solutions of neural networks in a more general setting using overparametrization as a way to control the Neural Tangent Kernel. In this work we investigate how to bridge these two worlds and we provide deterministic convergence and recovery guarantees for the class of unsupervised feedforward multilayer neural networks trained to solve inverse problems. We also derive overparametrization bounds under which a two-layers Deep Inverse Prior network with smooth activation function will benefit from our guarantees.
Convergence Guarantees of Overparametrized Wide Deep Inverse Prior
Mar 20, 2023

Neural networks have become a prominent approach to solve inverse problems in recent years. Amongst the different existing methods, the Deep Image/Inverse Priors (DIPs) technique is an unsupervised approach that optimizes a highly overparametrized neural network to transform a random input into an object whose image under the forward model matches the observation. However, the level of overparametrization necessary for such methods remains an open problem. In this work, we aim to investigate this question for a two-layers neural network with a smooth activation function. We provide overparametrization bounds under which such network trained via continuous-time gradient descent will converge exponentially fast with high probability which allows to derive recovery prediction bounds. This work is thus a first step towards a theoretical understanding of overparametrized DIP networks, and more broadly it participates to the theoretical understanding of neural networks in inverse problem settings.
Provable Phase Retrieval with Mirror Descent
Oct 17, 2022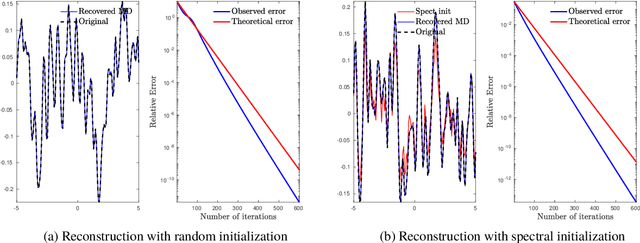
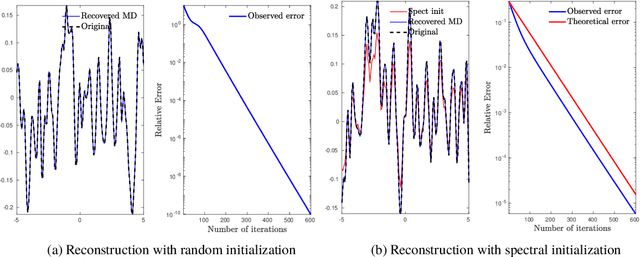
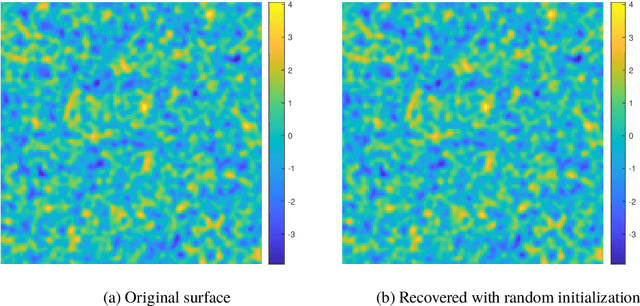
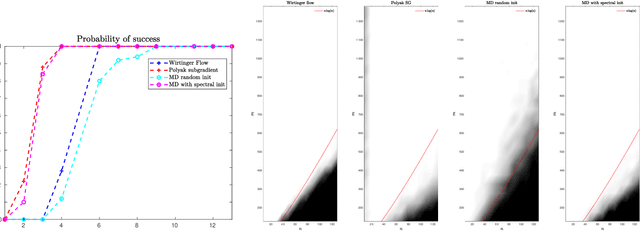
In this paper, we consider the problem of phase retrieval, which consists of recovering an $n$-dimensional real vector from the magnitude of its $m$ linear measurements. We propose a mirror descent (or Bregman gradient descent) algorithm based on a wisely chosen Bregman divergence, hence allowing to remove the classical global Lipschitz continuity requirement on the gradient of the non-convex phase retrieval objective to be minimized. We apply the mirror descent for two random measurements: the \iid standard Gaussian and those obtained by multiple structured illuminations through Coded Diffraction Patterns (CDP). For the Gaussian case, we show that when the number of measurements $m$ is large enough, then with high probability, for almost all initializers, the algorithm recovers the original vector up to a global sign change. For both measurements, the mirror descent exhibits a local linear convergence behaviour with a dimension-independent convergence rate. Our theoretical results are finally illustrated with various numerical experiments, including an application to the reconstruction of images in precision optics.