 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study of MAP and LMMSE Estimators for Blind Inverse Problems
Feb 12, 2026Maximum-a-posteriori (MAP) approaches are an effective framework for inverse problems with known forward operators, particularly when combined with expressive priors and careful parameter selection. In blind settings, however, their use becomes significantly less stable due to the inherent non-convexity of the problem and the potential non-identifiability of the solutions. (Linear) minimum mean square error (MMSE) estimators provide a compelling alternative that can circumvent these limitations. In this work, we study synthetic two-dimensional blind deconvolution problems under fully controlled conditions, with complete prior knowledge of both the signal and kernel distributions. We compare tailored MAP algorithms with simple LMMSE estimators whose functional form is closely related to that of an optimal Tikhonov estimator. Our results show that, even in these highly controlled settings, MAP methods remain unstable and require extensive parameter tuning, whereas the LMMSE estimator yields a robust and reliable baseline. Moreover, we demonstrate empirically that the LMMSE solution can serve as an effective initialization for MAP approaches, improving their performance and reducing sensitivity to regularization parameters, thereby opening the door to future theoretical and practical developments.
On the Sample Complexity of Learning for Blind Inverse Problems
Dec 29, 2025Blind inverse problems arise in many experimental settings where the forward operator is partially or entirely unknown. In this context, methods developed for the non-blind case cannot be adapted in a straightforward manner. Recently, data-driven approaches have been proposed to address blind inverse problems, demonstrating strong empirical performance and adaptability. However, these methods often lack interpretability and are not supported by rigorous theoretical guarantees, limiting their reliability in applied domains such as imaging inverse problems. In this work, we shed light on learning in blind inverse problems within the simplified yet insightful framework of Linear Minimum Mean Square Estimators (LMMSEs). We provide an in-depth theoretical analysis, deriving closed-form expressions for optimal estimators and extending classical results. In particular, we establish equivalences with suitably chosen Tikhonov-regularized formulations, where the regularization depends explicitly on the distributions of the unknown signal, the noise, and the random forward operators. We also prove convergence results under appropriate source condition assumptions. Furthermore, we derive rigorous finite-sample error bounds that characterize the performance of learned estimators as a function of the noise level, problem conditioning, and number of available samples. These bounds explicitly quantify the impact of operator randomness and reveal the associated convergence rates as this randomness vanishes. Finally, we validate our theoretical findings through illustrative numerical experiments that confirm the predicted convergence behavior.
Recovery Guarantees of Unsupervised Neural Networks for Inverse Problems trained with Gradient Descent
Mar 08, 2024



Advanced machine learning methods, and more prominently neural networks, have become standard to solve inverse problems over the last years. However, the theoretical recovery guarantees of such methods are still scarce and difficult to achieve. Only recently did unsupervised methods such as Deep Image Prior (DIP) get equipped with convergence and recovery guarantees for generic loss functions when trained through gradient flow with an appropriate initialization. In this paper, we extend these results by proving that these guarantees hold true when using gradient descent with an appropriately chosen step-size/learning rate. We also show that the discretization only affects the overparametrization bound for a two-layer DIP network by a constant and thus that the different guarantees found for the gradient flow will hold for gradient descent.
Convergence and Recovery Guarantees of Unsupervised Neural Networks for Inverse Problems
Sep 21, 2023


Neural networks have become a prominent approach to solve inverse problems in recent years. While a plethora of such methods was developed to solve inverse problems empirically, we are still lacking clear theoretical guarantees for these methods. On the other hand, many works proved convergence to optimal solutions of neural networks in a more general setting using overparametrization as a way to control the Neural Tangent Kernel. In this work we investigate how to bridge these two worlds and we provide deterministic convergence and recovery guarantees for the class of unsupervised feedforward multilayer neural networks trained to solve inverse problems. We also derive overparametrization bounds under which a two-layers Deep Inverse Prior network with smooth activation function will benefit from our guarantees.
Convergence Guarantees of Overparametrized Wide Deep Inverse Prior
Mar 20, 2023

Neural networks have become a prominent approach to solve inverse problems in recent years. Amongst the different existing methods, the Deep Image/Inverse Priors (DIPs) technique is an unsupervised approach that optimizes a highly overparametrized neural network to transform a random input into an object whose image under the forward model matches the observation. However, the level of overparametrization necessary for such methods remains an open problem. In this work, we aim to investigate this question for a two-layers neural network with a smooth activation function. We provide overparametrization bounds under which such network trained via continuous-time gradient descent will converge exponentially fast with high probability which allows to derive recovery prediction bounds. This work is thus a first step towards a theoretical understanding of overparametrized DIP networks, and more broadly it participates to the theoretical understanding of neural networks in inverse problem settings.
Maximizing Drift is Not Optimal for Solving OneMax
Apr 16, 2019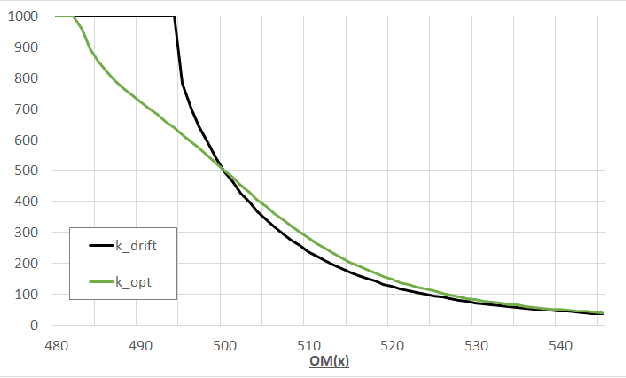
It seems very intuitive that for the maximization of the OneMax problem $f(x):=\sum_{i=1}^n{x_i}$ the best that an elitist unary unbiased search algorithm can do is to store a best so far solution, and to modify it with the operator that yields the best possible expected progress in function value. This assumption has been implicitly used in several empirical works. In [Doerr, Doerr, Yang: GECCO 2016] it was formally proven that this approach is indeed almost optimal. In this work we prove that drift maximization is \emph{not} optimal. More precisely, we show that for most fitness levels $n/2<\ell/2 < 2n/3$ the optimal mutation strengths are larger than the drift-maximizing ones. This implies that the optimal RLS is more risk-affine than the variant maximizing the step-wise expected progress. We show similar results for the mutation rates of the classic (1+1) Evolutionary Algorithm (EA) and its resampling variant, the (1+1) EA$_{>0}$. As a result of independent interest we show that the optimal mutation strengths, unlike the drift-maximizing ones, can be even.