 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadiometrically Consistent Gaussian Surfels for Inverse Rendering
Mar 02, 2026Inverse rendering with Gaussian Splatting has advanced rapidly, but accurately disentangling material properties from complex global illumination effects, particularly indirect illumination, remains a major challenge. Existing methods often query indirect radiance from Gaussian primitives pre-trained for novel-view synthesis. However, these pre-trained Gaussian primitives are supervised only towards limited training viewpoints, thus lack supervision for modeling indirect radiances from unobserved views. To address this issue, we introduce radiometric consistency, a novel physically-based constraint that provides supervision towards unobserved views by minimizing the residual between each Gaussian primitive's learned radiance and its physically-based rendered counterpart. Minimizing the residual for unobserved views establishes a self-correcting feedback loop that provides supervision from both physically-based rendering and novel-view synthesis, enabling accurate modeling of inter-reflection. We then propose Radiometrically Consistent Gaussian Surfels (RadioGS), an inverse rendering framework built upon our principle by efficiently integrating radiometric consistency by utilizing Gaussian surfels and 2D Gaussian ray tracing. We further propose a finetuning-based relighting strategy that adapts Gaussian surfel radiances to new illuminations within minutes, achieving low rendering cost (<10ms). Extensive experiments on existing inverse rendering benchmarks show that RadioGS outperforms existing Gaussian-based methods in inverse rendering, while retaining the computational efficiency.
Towards Test-time Efficient Visual Place Recognition via Asymmetric Query Processing
Dec 15, 2025Visual Place Recognition (VPR) has advanced significantly with high-capacity foundation models like DINOv2, achieving remarkable performance. Nonetheless, their substantial computational cost makes deployment on resource-constrained devices impractical. In this paper, we introduce an efficient asymmetric VPR framework that incorporates a high-capacity gallery model for offline feature extraction with a lightweight query network for online processing. A key challenge in this setting is ensuring compatibility between these heterogeneous networks, which conventional approaches address through computationally expensive k-NN-based compatible training. To overcome this, we propose a geographical memory bank that structures gallery features using geolocation metadata inherent in VPR databases, eliminating the need for exhaustive k-NN computations. Additionally, we introduce an implicit embedding augmentation technique that enhances the query network to model feature variations despite its limited capacity. Extensive experiments demonstrate that our method not only significantly reduces computational costs but also outperforms existing asymmetric retrieval techniques, establishing a new aspect for VPR in resource-limited environments. The code is available at https://github.com/jaeyoon1603/AsymVPR
KoBALT: Korean Benchmark For Advanced Linguistic Tasks
May 22, 2025



We introduce KoBALT (Korean Benchmark for Advanced Linguistic Tasks), a comprehensive linguistically-motivated benchmark comprising 700 multiple-choice questions spanning 24 phenomena across five linguistic domains: syntax, semantics, pragmatics, phonetics/phonology, and morphology. KoBALT is designed to advance the evaluation of large language models (LLMs) in Korean, a morphologically rich language, by addressing the limitations of conventional benchmarks that often lack linguistic depth and typological grounding. It introduces a suite of expert-curated, linguistically motivated questions with minimal n-gram overlap with standard Korean corpora, substantially mitigating the risk of data contamination and allowing a more robust assessment of true language understanding. Our evaluation of 20 contemporary LLMs reveals significant performance disparities, with the highest-performing model achieving 61\% general accuracy but showing substantial variation across linguistic domains - from stronger performance in semantics (66\%) to considerable weaknesses in phonology (31\%) and morphology (36\%). Through human preference evaluation with 95 annotators, we demonstrate a strong correlation between KoBALT scores and human judgments, validating our benchmark's effectiveness as a discriminative measure of Korean language understanding. KoBALT addresses critical gaps in linguistic evaluation for typologically diverse languages and provides a robust framework for assessing genuine linguistic competence in Korean language models.
MoFE: Mixture of Frozen Experts Architecture
Mar 09, 2025



We propose the Mixture of Frozen Experts (MoFE) architecture, which integrates Parameter-efficient Fine-tuning (PEFT) and the Mixture of Experts (MoE) architecture to enhance both training efficiency and model scalability. By freezing the Feed Forward Network (FFN) layers within the MoE framework, MoFE significantly reduces the number of trainable parameters, improving training efficiency while still allowing for effective knowledge transfer from the expert models. This facilitates the creation of models proficient in multiple domains. We conduct experiments to evaluate the trade-offs between performance and efficiency, compare MoFE with other PEFT methodologies, assess the impact of domain expertise in the constituent models, and determine the optimal training strategy. The results show that, although there may be some trade-offs in performance, the efficiency gains are substantial, making MoFE a reasonable solution for real-world, resource-constrained environments.
How does a Language-Specific Tokenizer affect LLMs?
Feb 18, 2025



The necessity of language-specific tokenizers intuitively appears crucial for effective natural language processing, yet empirical analyses on their significance and underlying reasons are lacking. This study explores how language-specific tokenizers influence the behavior of Large Language Models predominantly trained with English text data, through the case study of Korean. The research unfolds in two main stages: (1) the development of a Korean-specific extended tokenizer and (2) experiments to compare models with the basic tokenizer and the extended tokenizer through various Next Token Prediction tasks. Our in-depth analysis reveals that the extended tokenizer decreases confidence in incorrect predictions during generation and reduces cross-entropy in complex tasks, indicating a tendency to produce less nonsensical outputs. Consequently, the extended tokenizer provides stability during generation, potentially leading to higher performance in downstream tasks.
Denoising Nearest Neighbor Graph via Continuous CRF for Visual Re-ranking without Fine-tuning
Dec 18, 2024



Visual re-ranking using Nearest Neighbor graph~(NN graph) has been adapted to yield high retrieval accuracy, since it is beneficial to exploring an high-dimensional manifold and applicable without additional fine-tuning. The quality of visual re-ranking using NN graph, however, is limited to that of connectivity, i.e., edges of the NN graph. Some edges can be misconnected with negative images. This is known as a noisy edge problem, resulting in a degradation of the retrieval quality. To address this, we propose a complementary denoising method based on Continuous Conditional Random Field (C-CRF) that uses a statistical distance of our similarity-based distribution. This method employs the concept of cliques to make the process computationally feasible. We demonstrate the complementarity of our method through its application to three visual re-ranking methods, observing quality boosts in landmark retrieval and person re-identification (re-ID).
DaG LLM ver 1.0: Pioneering Instruction-Tuned Language Modeling for Korean NLP
Nov 23, 2023This paper presents the DaG LLM (David and Goliath Large Language Model), a language model specialized for Korean and fine-tuned through Instruction Tuning across 41 tasks within 13 distinct categories.
Virtual Piano using Computer Vision
Oct 28, 2019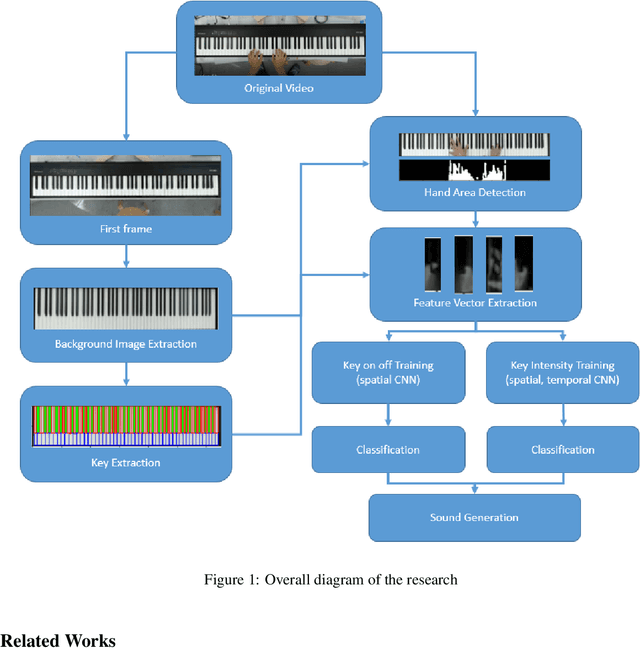



In this research, Piano performances have been analyzed only based on visual information. Computer vision algorithms, e.g., Hough transform and binary thresholding, have been applied to find where the keyboard and specific keys are located. At the same time, Convolutional Neural Networks(CNNs) has been also utilized to find whether specific keys are pressed or not, and how much intensity the keys are pressed only based on visual information. Especially for detecting intensity, a new method of utilizing spatial, temporal CNNs model is devised. Early fusion technique is especially applied in temporal CNNs architecture to analyze hand movement. We also make a new dataset for training each model. Especially when finding an intensity of a pressed key, both of video frames and their optical flow images are used to train models to find effectiveness.
Fast 2-D Complex Gabor Filter with Kernel Decomposition
Apr 18, 2017
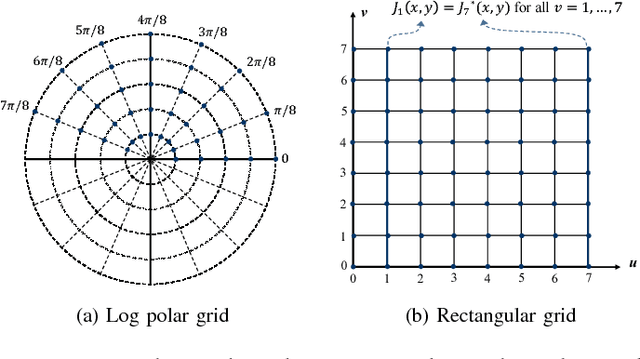

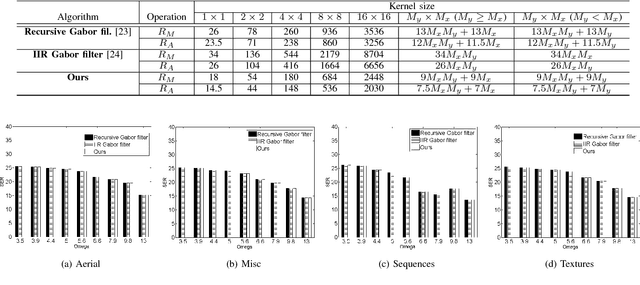
2-D complex Gabor filtering has found numerous applications in the fields of computer vision and image processing. Especially, in some applications, it is often needed to compute 2-D complex Gabor filter bank consisting of the 2-D complex Gabor filtering outputs at multiple orientations and frequencies. Although several approaches for fast 2-D complex Gabor filtering have been proposed, they primarily focus on reducing the runtime of performing the 2-D complex Gabor filtering once at specific orientation and frequency. To obtain the 2-D complex Gabor filter bank output, existing methods are repeatedly applied with respect to multiple orientations and frequencies. In this paper, we propose a novel approach that efficiently computes the 2-D complex Gabor filter bank by reducing the computational redundancy that arises when performing the Gabor filtering at multiple orientations and frequencies. The proposed method first decomposes the Gabor basis kernels to allow a fast convolution with the Gaussian kernel in a separable manner. This enables reducing the runtime of the 2-D complex Gabor filter bank by reusing intermediate results of the 2-D complex Gabor filtering computed at a specific orientation. Furthermore, we extend this idea into 2-D localized sliding discrete Fourier transform (SDFT) using the Gaussian kernel in the DFT computation, which lends a spatial localization ability as in the 2-D complex Gabor filter. Experimental results demonstrate that our method runs faster than state-of-the-arts methods for fast 2-D complex Gabor filtering, while maintaining similar filtering quality.