 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Gaussian Gaussian Processes for Few-Shot Regression
Oct 26, 2021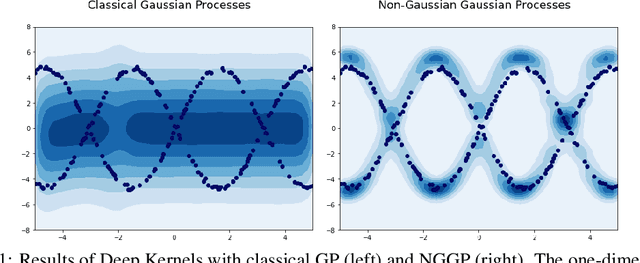
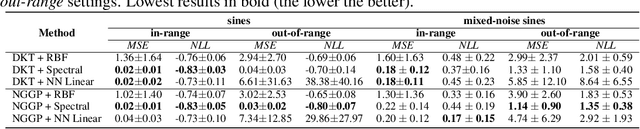
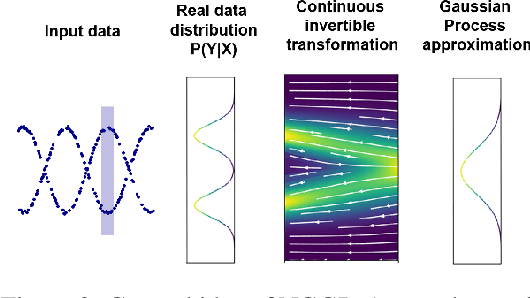
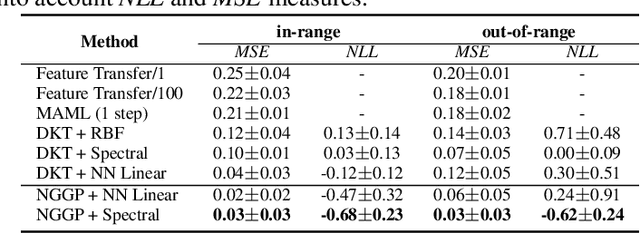
Gaussian Processes (GPs) have been widely used in machine learning to model distributions over functions, with applications including multi-modal regression, time-series prediction, and few-shot learning. GPs are particularly useful in the last application since they rely on Normal distributions and enable closed-form computation of the posterior probability function. Unfortunately, because the resulting posterior is not flexible enough to capture complex distributions, GPs assume high similarity between subsequent tasks - a requirement rarely met in real-world conditions. In this work, we address this limitation by leveraging the flexibility of Normalizing Flows to modulate the posterior predictive distribution of the GP. This makes the GP posterior locally non-Gaussian, therefore we name our method Non-Gaussian Gaussian Processes (NGGPs). More precisely, we propose an invertible ODE-based mapping that operates on each component of the random variable vectors and shares the parameters across all of them. We empirically tested the flexibility of NGGPs on various few-shot learning regression datasets, showing that the mapping can incorporate context embedding information to model different noise levels for periodic functions. As a result, our method shares the structure of the problem between subsequent tasks, but the contextualization allows for adaptation to dissimilarities. NGGPs outperform the competing state-of-the-art approaches on a diversified set of benchmarks and applications.
Relative Molecule Self-Attention Transformer
Oct 12, 2021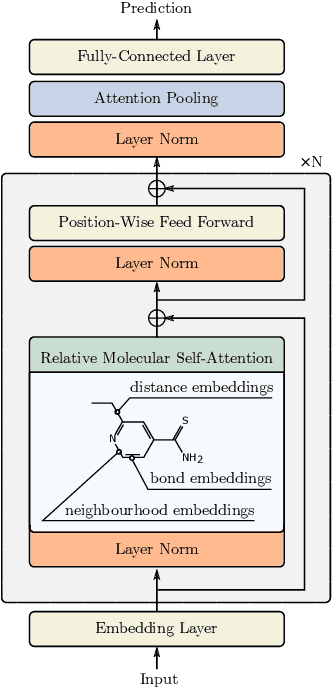
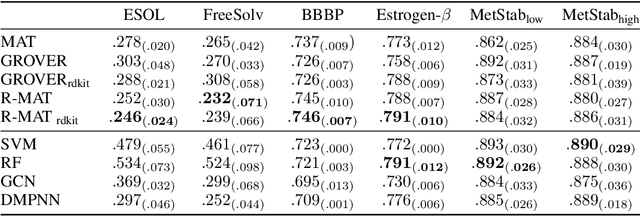
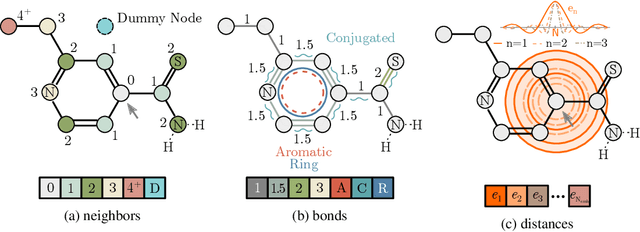
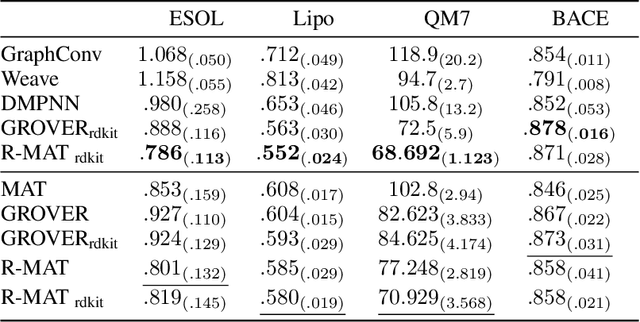
Self-supervised learning holds promise to revolutionize molecule property prediction - a central task to drug discovery and many more industries - by enabling data efficient learning from scarce experimental data. Despite significant progress, non-pretrained methods can be still competitive in certain settings. We reason that architecture might be a key bottleneck. In particular, enriching the backbone architecture with domain-specific inductive biases has been key for the success of self-supervised learning in other domains. In this spirit, we methodologically explore the design space of the self-attention mechanism tailored to molecular data. We identify a novel variant of self-attention adapted to processing molecules, inspired by the relative self-attention layer, which involves fusing embedded graph and distance relationships between atoms. Our main contribution is Relative Molecule Attention Transformer (R-MAT): a novel Transformer-based model based on the developed self-attention layer that achieves state-of-the-art or very competitive results across a~wide range of molecule property prediction tasks.
Flow-based SVDD for anomaly detection
Aug 10, 2021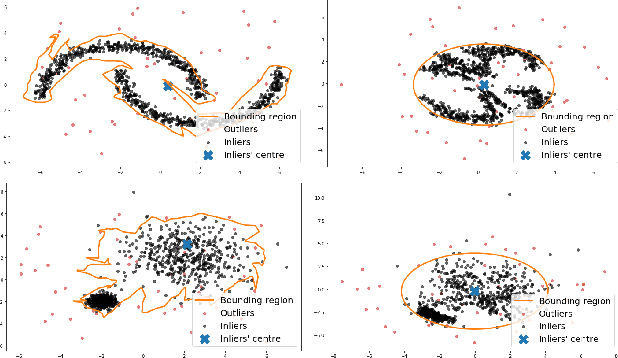
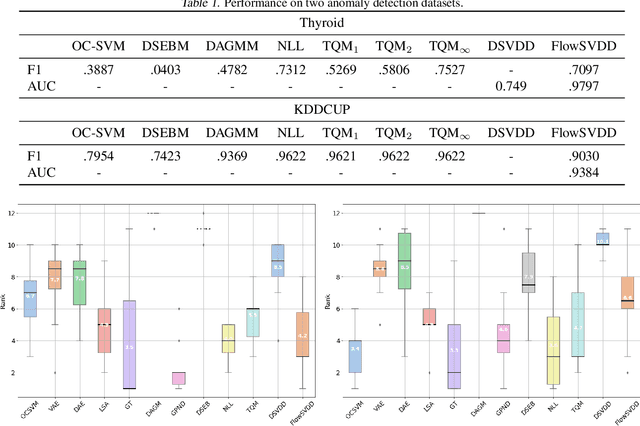

We propose FlowSVDD -- a flow-based one-class classifier for anomaly/outliers detection that realizes a well-known SVDD principle using deep learning tools. Contrary to other approaches to deep SVDD, the proposed model is instantiated using flow-based models, which naturally prevents from collapsing of bounding hypersphere into a single point. Experiments show that FlowSVDD achieves comparable results to the current state-of-the-art methods and significantly outperforms related deep SVDD methods on benchmark datasets.
SONG: Self-Organizing Neural Graphs
Jul 28, 2021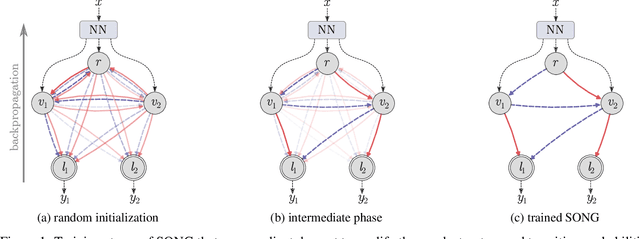
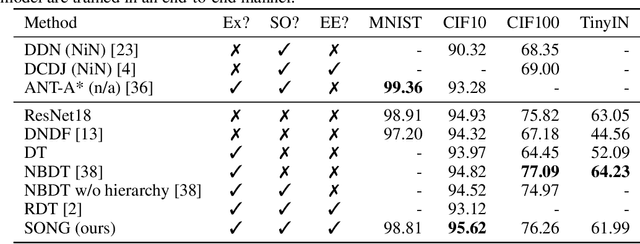
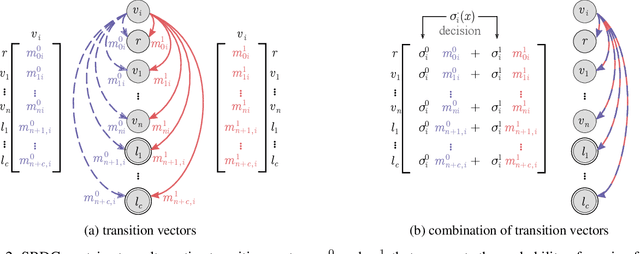
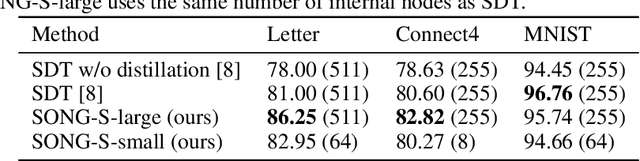
Recent years have seen a surge in research on deep interpretable neural networks with decision trees as one of the most commonly incorporated tools. There are at least three advantages of using decision trees over logistic regression classification models: they are easy to interpret since they are based on binary decisions, they can make decisions faster, and they provide a hierarchy of classes. However, one of the well-known drawbacks of decision trees, as compared to decision graphs, is that decision trees cannot reuse the decision nodes. Nevertheless, decision graphs were not commonly used in deep learning due to the lack of efficient gradient-based training techniques. In this paper, we fill this gap and provide a general paradigm based on Markov processes, which allows for efficient training of the special type of decision graphs, which we call Self-Organizing Neural Graphs (SONG). We provide an extensive theoretical study of SONG, complemented by experiments conducted on Letter, Connect4, MNIST, CIFAR, and TinyImageNet datasets, showing that our method performs on par or better than existing decision models.
Direction is what you need: Improving Word Embedding Compression in Large Language Models
Jun 15, 2021

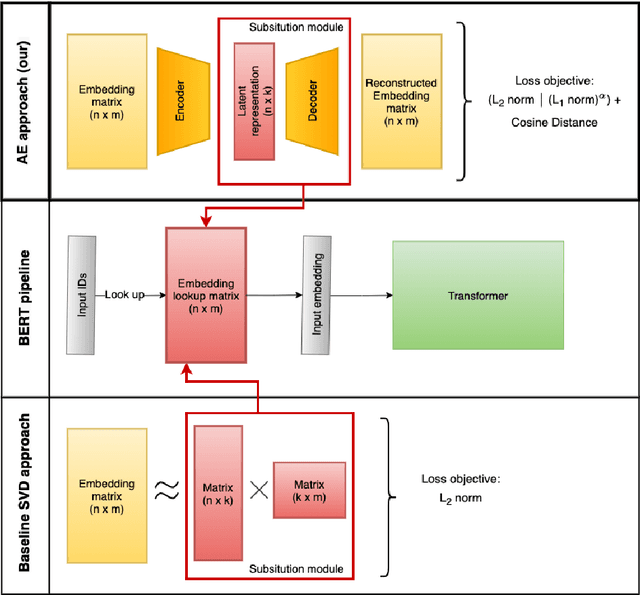
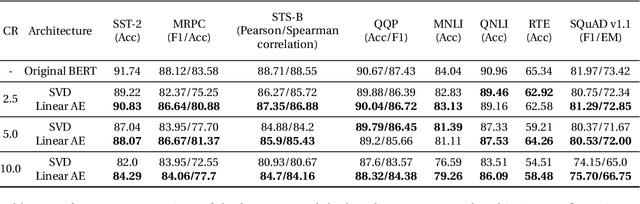
The adoption of Transformer-based models in natural language processing (NLP) has led to great success using a massive number of parameters. However, due to deployment constraints in edge devices, there has been a rising interest in the compression of these models to improve their inference time and memory footprint. This paper presents a novel loss objective to compress token embeddings in the Transformer-based models by leveraging an AutoEncoder architecture. More specifically, we emphasize the importance of the direction of compressed embeddings with respect to original uncompressed embeddings. The proposed method is task-agnostic and does not require further language modeling pre-training. Our method significantly outperforms the commonly used SVD-based matrix-factorization approach in terms of initial language model Perplexity. Moreover, we evaluate our proposed approach over SQuAD v1.1 dataset and several downstream tasks from the GLUE benchmark, where we also outperform the baseline in most scenarios. Our code is public.
Zero Time Waste: Recycling Predictions in Early Exit Neural Networks
Jun 09, 2021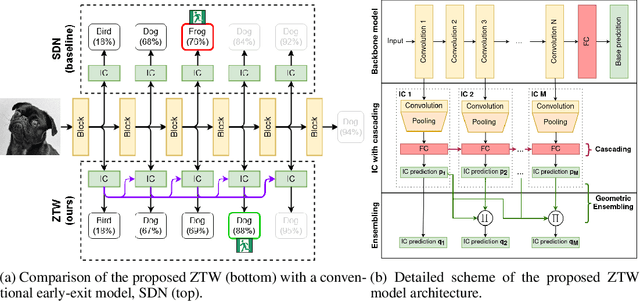
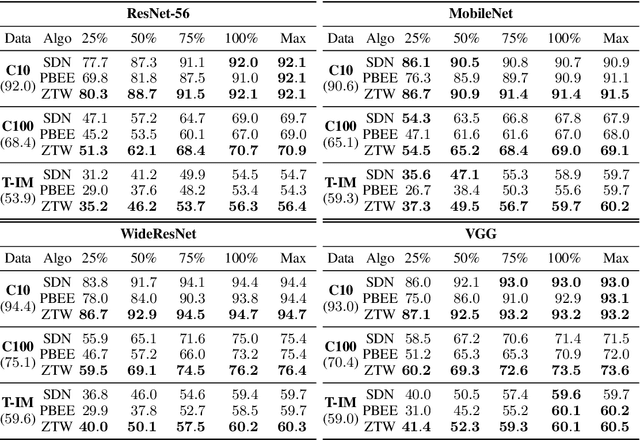
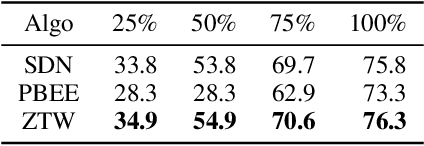
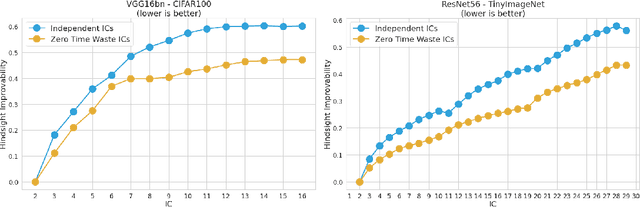
The problem of reducing processing time of large deep learning models is a fundamental challenge in many real-world applications. Early exit methods strive towards this goal by attaching additional Internal Classifiers (ICs) to intermediate layers of a neural network. ICs can quickly return predictions for easy examples and, as a result, reduce the average inference time of the whole model. However, if a particular IC does not decide to return an answer early, its predictions are discarded, with its computations effectively being wasted. To solve this issue, we introduce Zero Time Waste (ZTW), a novel approach in which each IC reuses predictions returned by its predecessors by (1) adding direct connections between ICs and (2) combining previous outputs in an ensemble-like manner. We conduct extensive experiments across various datasets and architectures to demonstrate that ZTW achieves a significantly better accuracy vs. inference time trade-off than other recently proposed early exit methods.
HyperPocket: Generative Point Cloud Completion
Feb 11, 2021
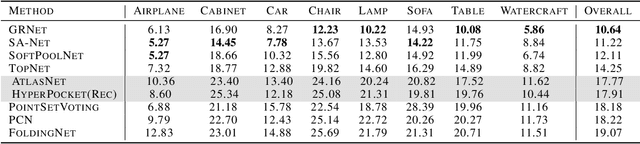
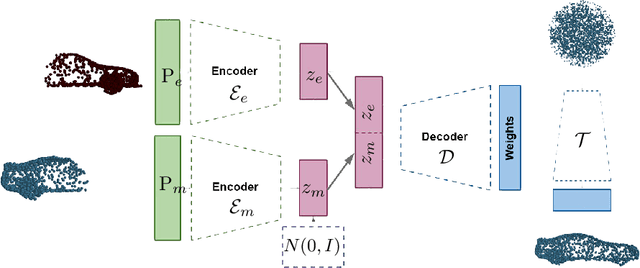
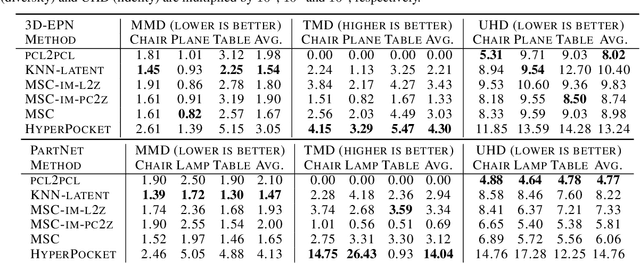
Scanning real-life scenes with modern registration devices typically give incomplete point cloud representations, mostly due to the limitations of the scanning process and 3D occlusions. Therefore, completing such partial representations remains a fundamental challenge of many computer vision applications. Most of the existing approaches aim to solve this problem by learning to reconstruct individual 3D objects in a synthetic setup of an uncluttered environment, which is far from a real-life scenario. In this work, we reformulate the problem of point cloud completion into an object hallucination task. Thus, we introduce a novel autoencoder-based architecture called HyperPocket that disentangles latent representations and, as a result, enables the generation of multiple variants of the completed 3D point clouds. We split point cloud processing into two disjoint data streams and leverage a hypernetwork paradigm to fill the spaces, dubbed pockets, that are left by the missing object parts. As a result, the generated point clouds are not only smooth but also plausible and geometrically consistent with the scene. Our method offers competitive performances to the other state-of-the-art models, and it enables a~plethora of novel applications.
RegFlow: Probabilistic Flow-based Regression for Future Prediction
Nov 30, 2020
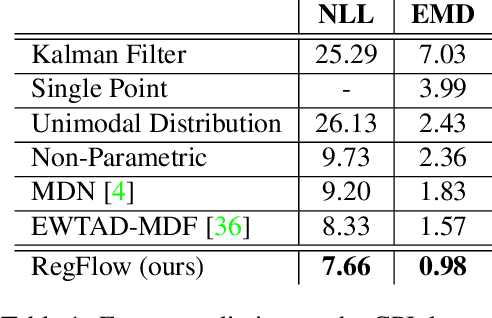
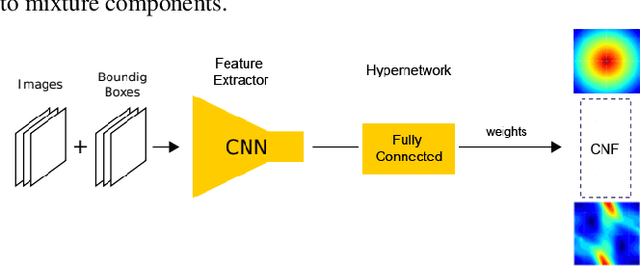
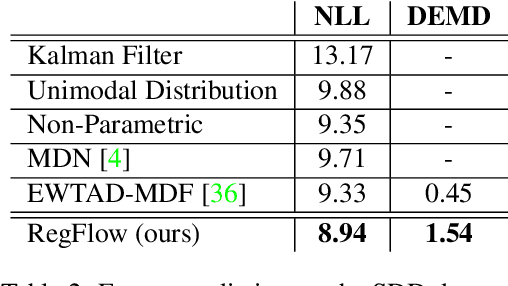
Predicting future states or actions of a given system remains a fundamental, yet unsolved challenge of intelligence, especially in the scope of complex and non-deterministic scenarios, such as modeling behavior of humans. Existing approaches provide results under strong assumptions concerning unimodality of future states, or, at best, assuming specific probability distributions that often poorly fit to real-life conditions. In this work we introduce a robust and flexible probabilistic framework that allows to model future predictions with virtually no constrains regarding the modality or underlying probability distribution. To achieve this goal, we leverage a hypernetwork architecture and train a continuous normalizing flow model. The resulting method dubbed RegFlow achieves state-of-the-art results on several benchmark datasets, outperforming competing approaches by a significant margin.
ProtoPShare: Prototype Sharing for Interpretable Image Classification and Similarity Discovery
Nov 29, 2020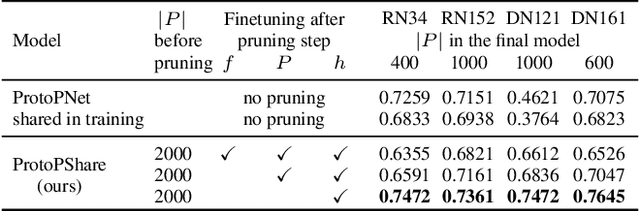

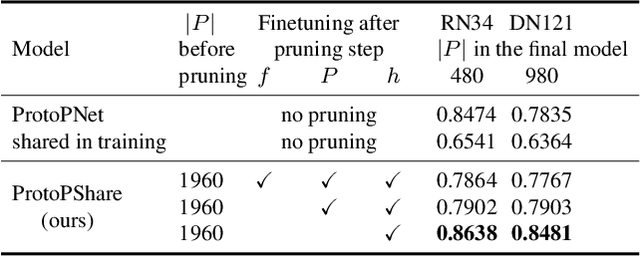

In this paper, we introduce ProtoPShare, a self-explained method that incorporates the paradigm of prototypical parts to explain its predictions. The main novelty of the ProtoPShare is its ability to efficiently share prototypical parts between the classes thanks to our data-dependent merge-pruning. Moreover, the prototypes are more consistent and the model is more robust to image perturbations than the state of the art method ProtoPNet. We verify our findings on two datasets, the CUB-200-2011 and the Stanford Cars.
Flow-based anomaly detection
Oct 06, 2020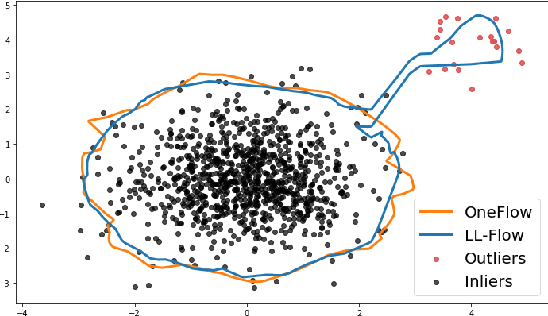
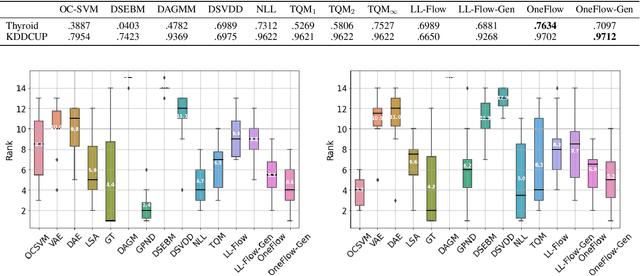
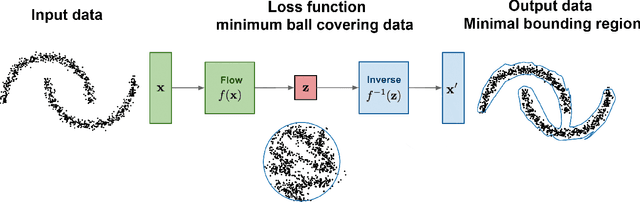
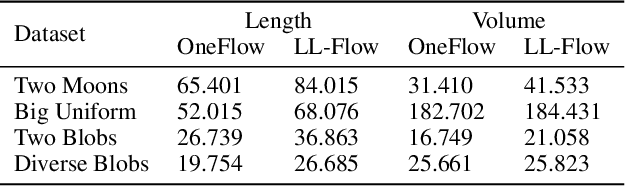
We propose OneFlow - a flow-based one-class classifier for anomaly (outliers) detection that finds a minimal volume bounding region. Contrary to density-based methods, OneFlow is constructed in such a way that its result typically does not depend on the structure of outliers. This is caused by the fact that during training the gradient of the cost function is propagated only over the points located near to the decision boundary (behavior similar to the support vectors in SVM). The combination of flow models and Bernstein quantile estimator allows OneFlow to find a parametric form of bounding region, which can be useful in various applications including describing shapes from 3D point clouds. Experiments show that the proposed model outperforms related methods on real-world anomaly detection problems.