 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Plane Analysis of Binary Neural Networks
May 05, 2026Information plane (IP) analysis has been suggested to study the training dynamics of deep neural networks through mutual information (MI) between inputs, representations, and targets. However, its statistical validity is often compromised by the difficulty of estimating MI from samples of high-dimensional, deterministic representations. In this work, we perform IP analyses on binary neural networks (BNNs) where activations are discrete and MI is finite. We characterise the finite-sample behaviour of the plug-in entropy estimator and identify regimes for sample size $N$ and representation dimensionality $D$ under which MI estimates are reliable. Outside these regimes, we show that empirical MI estimates saturate to $\log_2 N$, rendering IP trajectories uninformative. Restricting attention to the reliable regime, we train 375 BNNs to investigate the existence of late-stage compression phases and the relationship between compressed representations and generalisation performance. Our results show that while late-stage compression is frequently observed, compressed latent representations do not consistently correlate with improved generalization performance. Instead, the relationship between compression and generalisation is highly dependent on task, architecture, and regularisation.
B-PL-PINN: Stabilizing PINN Training with Bayesian Pseudo Labeling
Jul 02, 2025Training physics-informed neural networks (PINNs) for forward problems often suffers from severe convergence issues, hindering the propagation of information from regions where the desired solution is well-defined. Haitsiukevich and Ilin (2023) proposed an ensemble approach that extends the active training domain of each PINN based on i) ensemble consensus and ii) vicinity to (pseudo-)labeled points, thus ensuring that the information from the initial condition successfully propagates to the interior of the computational domain. In this work, we suggest replacing the ensemble by a Bayesian PINN, and consensus by an evaluation of the PINN's posterior variance. Our experiments show that this mathematically principled approach outperforms the ensemble on a set of benchmark problems and is competitive with PINN ensembles trained with combinations of Adam and LBFGS.
On the Role of Priors in Bayesian Causal Learning
Apr 02, 2025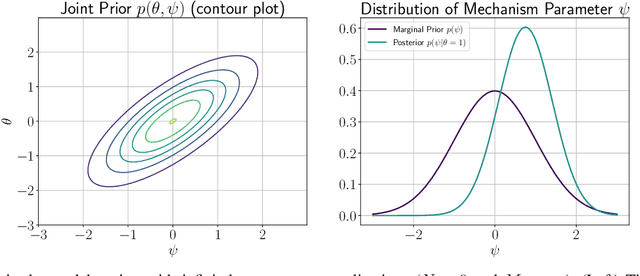
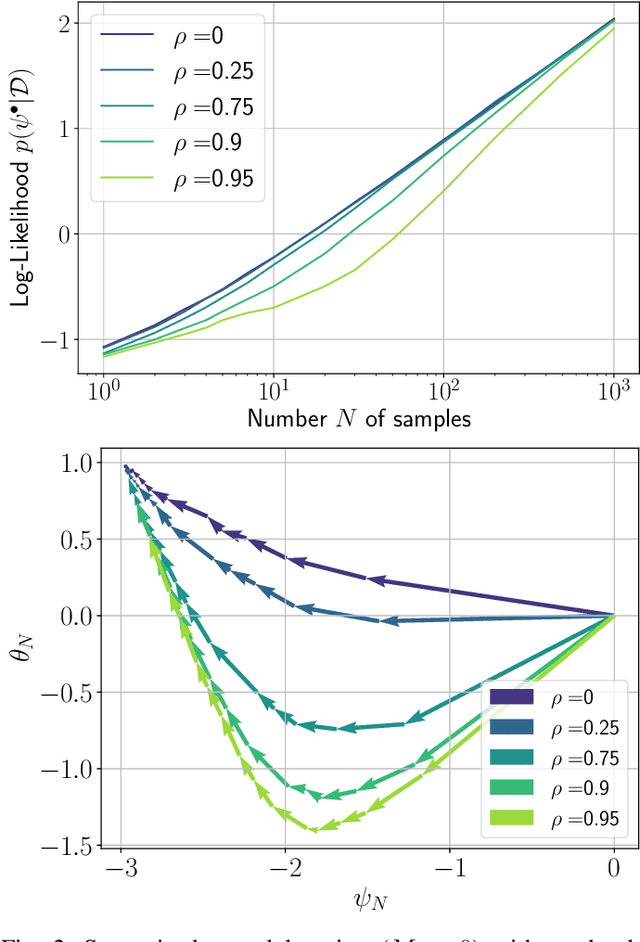
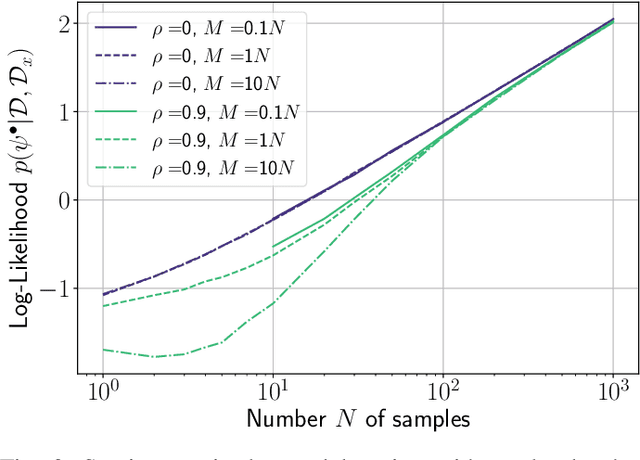
In this work, we investigate causal learning of independent causal mechanisms from a Bayesian perspective. Confirming previous claims from the literature, we show in a didactically accessible manner that unlabeled data (i.e., cause realizations) do not improve the estimation of the parameters defining the mechanism. Furthermore, we observe the importance of choosing an appropriate prior for the cause and mechanism parameters, respectively. Specifically, we show that a factorized prior results in a factorized posterior, which resonates with Janzing and Sch\"olkopf's definition of independent causal mechanisms via the Kolmogorov complexity of the involved distributions and with the concept of parameter independence of Heckerman et al.
Challenges in Implementing a Recommender System for Historical Research in the Humanities
Oct 28, 2024
This extended abstract describes the challenges in implementing recommender systems for digital archives in the humanities, focusing on Monasterium.net, a platform for historical legal documents. We discuss three key aspects: (i) the unique characteristics of so-called charters as items for recommendation, (ii) the complex multi-stakeholder environment, and (iii) the distinct information-seeking behavior of scholars in the humanities. By examining these factors, we aim to contribute to the development of more effective and tailored recommender systems for (digital) humanities research.
Constraining Anomaly Detection with Anomaly-Free Regions
Sep 30, 2024



We propose the novel concept of anomaly-free regions (AFR) to improve anomaly detection. An AFR is a region in the data space for which it is known that there are no anomalies inside it, e.g., via domain knowledge. This region can contain any number of normal data points and can be anywhere in the data space. AFRs have the key advantage that they constrain the estimation of the distribution of non-anomalies: The estimated probability mass inside the AFR must be consistent with the number of normal data points inside the AFR. Based on this insight, we provide a solid theoretical foundation and a reference implementation of anomaly detection using AFRs. Our empirical results confirm that anomaly detection constrained via AFRs improves upon unconstrained anomaly detection. Specifically, we show that, when equipped with an estimated AFR, an efficient algorithm based on random guessing becomes a strong baseline that several widely-used methods struggle to overcome. On a dataset with a ground-truth AFR available, the current state of the art is outperformed.
Value Identification in Multistakeholder Recommender Systems for Humanities and Historical Research: The Case of the Digital Archive Monasterium.net
Sep 26, 2024Recommender systems remain underutilized in humanities and historical research, despite their potential to enhance the discovery of cultural records. This paper offers an initial value identification of the multiple stakeholders that might be impacted by recommendations in Monasterium.net, a digital archive for historical legal documents. Specifically, we discuss the diverse values and objectives of its stakeholders, such as editors, aggregators, platform owners, researchers, publishers, and funding agencies. These in-depth insights into the potentially conflicting values of stakeholder groups allow designing and adapting recommender systems to enhance their usefulness for humanities and historical research. Additionally, our findings will support deeper engagement with additional stakeholders to refine value models and evaluation metrics for recommender systems in the given domains. Our conclusions are embedded in and applicable to other digital archives and a broader cultural heritage context.
Approximating Families of Sharp Solutions to Fisher's Equation with Physics-Informed Neural Networks
Feb 13, 2024



This paper employs physics-informed neural networks (PINNs) to solve Fisher's equation, a fundamental representation of a reaction-diffusion system with both simplicity and significance. The focus lies specifically in investigating Fisher's equation under conditions of large reaction rate coefficients, wherein solutions manifest as traveling waves, posing a challenge for numerical methods due to the occurring steepness of the wave front. To address optimization challenges associated with the standard PINN approach, a residual weighting scheme is introduced. This scheme is designed to enhance the tracking of propagating wave fronts by considering the reaction term in the reaction-diffusion equation. Furthermore, a specific network architecture is studied which is tailored for solutions in the form of traveling waves. Lastly, the capacity of PINNs to approximate an entire family of solutions is assessed by incorporating the reaction rate coefficient as an additional input to the network architecture. This modification enables the approximation of the solution across a broad and continuous range of reaction rate coefficients, thus solving a class of reaction-diffusion systems using a single PINN instance.
Finding the Optimum Design of Large Gas Engines Prechambers Using CFD and Bayesian Optimization
Aug 03, 2023



The turbulent jet ignition concept using prechambers is a promising solution to achieve stable combustion at lean conditions in large gas engines, leading to high efficiency at low emission levels. Due to the wide range of design and operating parameters for large gas engine prechambers, the preferred method for evaluating different designs is computational fluid dynamics (CFD), as testing in test bed measurement campaigns is time-consuming and expensive. However, the significant computational time required for detailed CFD simulations due to the complexity of solving the underlying physics also limits its applicability. In optimization settings similar to the present case, i.e., where the evaluation of the objective function(s) is computationally costly, Bayesian optimization has largely replaced classical design-of-experiment. Thus, the present study deals with the computationally efficient Bayesian optimization of large gas engine prechambers design using CFD simulation. Reynolds-averaged-Navier-Stokes simulations are used to determine the target values as a function of the selected prechamber design parameters. The results indicate that the chosen strategy is effective to find a prechamber design that achieves the desired target values.
Bringing Chemistry to Scale: Loss Weight Adjustment for Multivariate Regression in Deep Learning of Thermochemical Processes
Aug 03, 2023Flamelet models are widely used in computational fluid dynamics to simulate thermochemical processes in turbulent combustion. These models typically employ memory-expensive lookup tables that are predetermined and represent the combustion process to be simulated. Artificial neural networks (ANNs) offer a deep learning approach that can store this tabular data using a small number of network weights, potentially reducing the memory demands of complex simulations by orders of magnitude. However, ANNs with standard training losses often struggle with underrepresented targets in multivariate regression tasks, e.g., when learning minor species mass fractions as part of lookup tables. This paper seeks to improve the accuracy of an ANN when learning multiple species mass fractions of a hydrogen (\ce{H2}) combustion lookup table. We assess a simple, yet effective loss weight adjustment that outperforms the standard mean-squared error optimization and enables accurate learning of all species mass fractions, even of minor species where the standard optimization completely fails. Furthermore, we find that the loss weight adjustment leads to more balanced gradients in the network training, which explains its effectiveness.
Cluster Purging: Efficient Outlier Detection based on Rate-Distortion Theory
Feb 22, 2023



Rate-distortion theory-based outlier detection builds upon the rationale that a good data compression will encode outliers with unique symbols. Based on this rationale, we propose Cluster Purging, which is an extension of clustering-based outlier detection. This extension allows one to assess the representivity of clusterings, and to find data that are best represented by individual unique clusters. We propose two efficient algorithms for performing Cluster Purging, one being parameter-free, while the other algorithm has a parameter that controls representivity estimations, allowing it to be tuned in supervised setups. In an experimental evaluation, we show that Cluster Purging improves upon outliers detected from raw clusterings, and that Cluster Purging competes strongly against state-of-the-art alternatives.