 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Divergence Minimization for Biterm Topic Model
May 01, 2017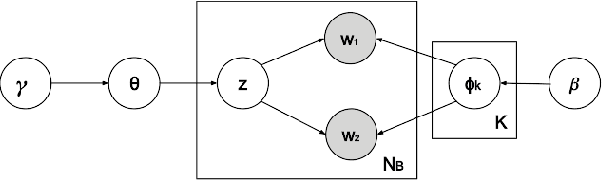
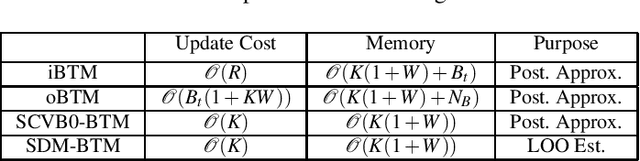
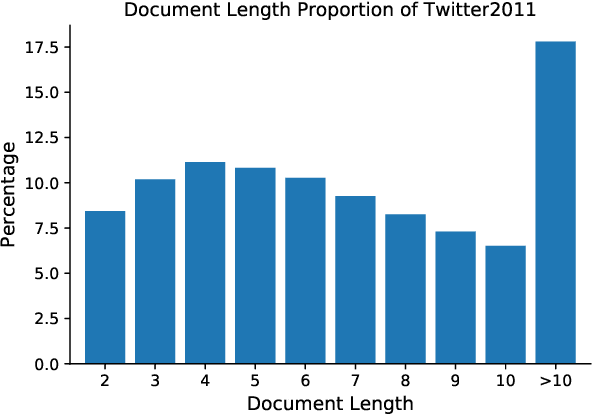
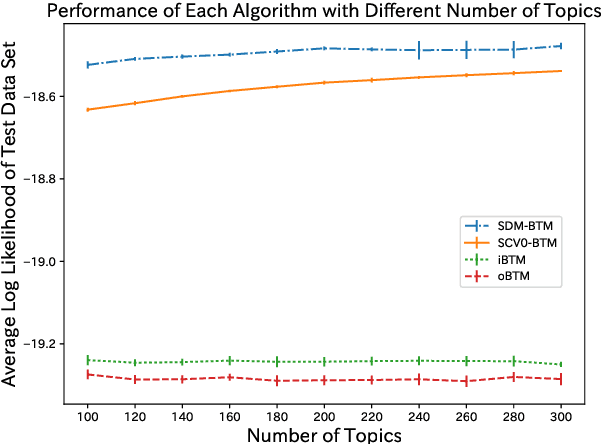
As the emergence and the thriving development of social networks, a huge number of short texts are accumulated and need to be processed. Inferring latent topics of collected short texts is useful for understanding its hidden structure and predicting new contents. Unlike conventional topic models such as latent Dirichlet allocation (LDA), a biterm topic model (BTM) was recently proposed for short texts to overcome the sparseness of document-level word co-occurrences by directly modeling the generation process of word pairs. Stochastic inference algorithms based on collapsed Gibbs sampling (CGS) and collapsed variational inference have been proposed for BTM. However, they either require large computational complexity, or rely on very crude estimation. In this work, we develop a stochastic divergence minimization inference algorithm for BTM to estimate latent topics more accurately in a scalable way. Experiments demonstrate the superiority of our proposed algorithm compared with existing inference algorithms.
Generative Adversarial Nets from a Density Ratio Estimation Perspective
Nov 09, 2016
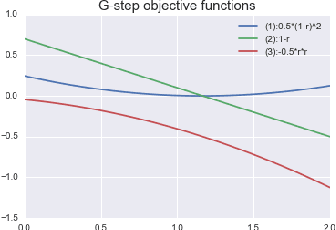

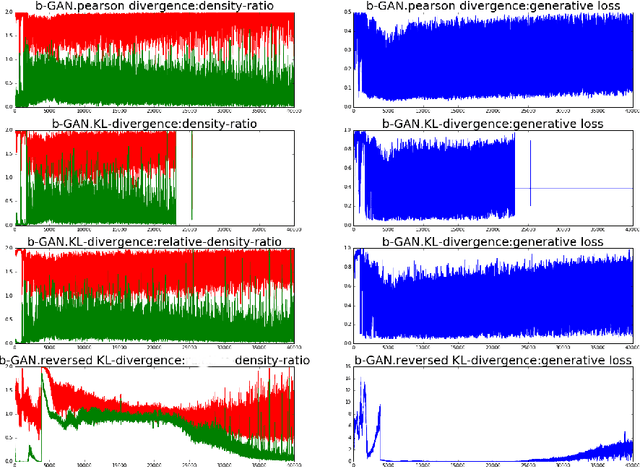
Generative adversarial networks (GANs) are successful deep generative models. GANs are based on a two-player minimax game. However, the objective function derived in the original motivation is changed to obtain stronger gradients when learning the generator. We propose a novel algorithm that repeats the density ratio estimation and f-divergence minimization. Our algorithm offers a new perspective toward the understanding of GANs and is able to make use of multiple viewpoints obtained in the research of density ratio estimation, e.g. what divergence is stable and relative density ratio is useful.
Collapsed Variational Bayes Inference of Infinite Relational Model
Sep 16, 2014
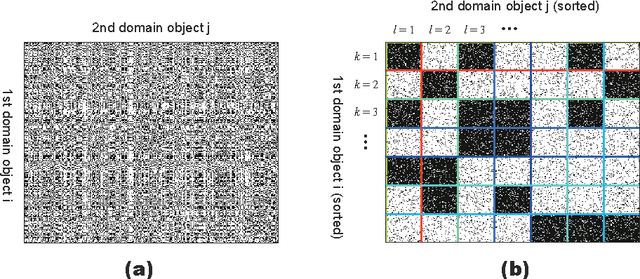
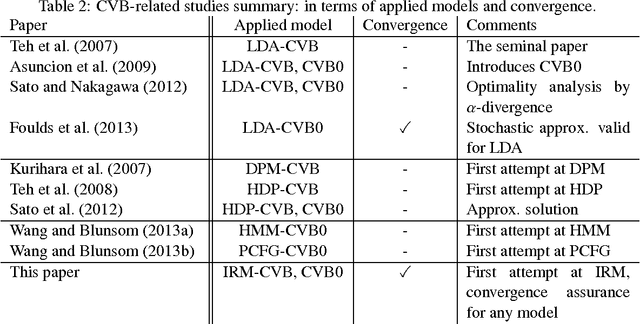

The Infinite Relational Model (IRM) is a probabilistic model for relational data clustering that partitions objects into clusters based on observed relationships. This paper presents Averaged CVB (ACVB) solutions for IRM, convergence-guaranteed and practically useful fast Collapsed Variational Bayes (CVB) inferences. We first derive ordinary CVB and CVB0 for IRM based on the lower bound maximization. CVB solutions yield deterministic iterative procedures for inferring IRM given the truncated number of clusters. Our proposal includes CVB0 updates of hyperparameters including the concentration parameter of the Dirichlet Process, which has not been studied in the literature. To make the CVB more practically useful, we further study the CVB inference in two aspects. First, we study the convergence issues and develop a convergence-guaranteed algorithm for any CVB-based inferences called ACVB, which enables automatic convergence detection and frees non-expert practitioners from difficult and costly manual monitoring of inference processes. Second, we present a few techniques for speeding up IRM inferences. In particular, we describe the linear time inference of CVB0, allowing the IRM for larger relational data uses. The ACVB solutions of IRM showed comparable or better performance compared to existing inference methods in experiments, and provide deterministic, faster, and easier convergence detection.
Quantum Annealing for Variational Bayes Inference
Aug 09, 2014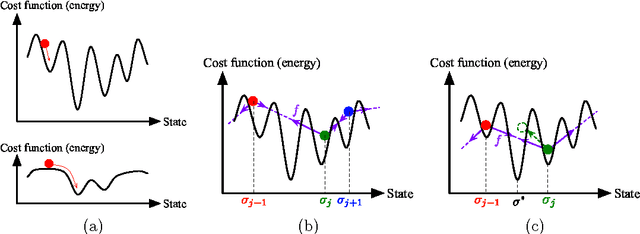
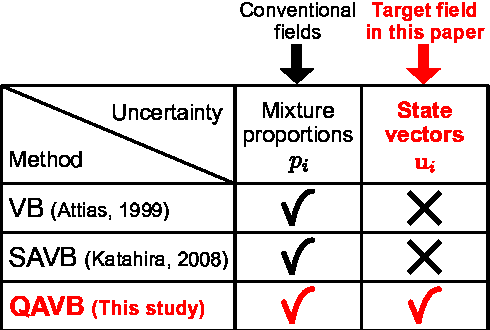
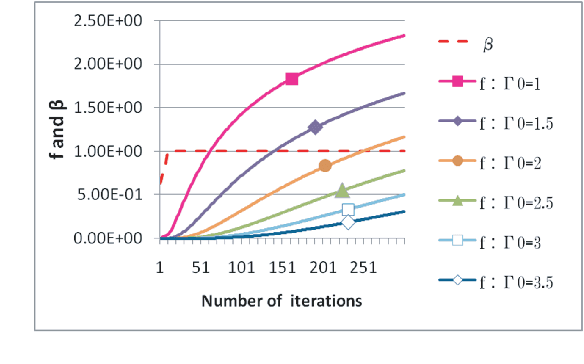
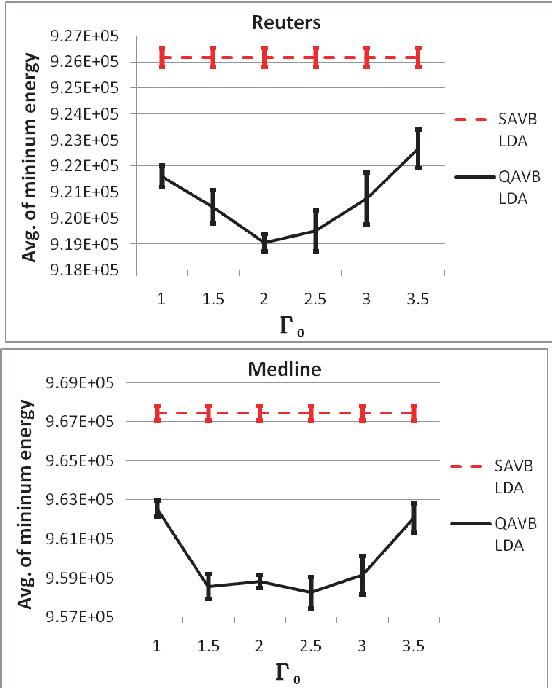
This paper presents studies on a deterministic annealing algorithm based on quantum annealing for variational Bayes (QAVB) inference, which can be seen as an extension of the simulated annealing for variational Bayes (SAVB) inference. QAVB is as easy as SAVB to implement. Experiments revealed QAVB finds a better local optimum than SAVB in terms of the variational free energy in latent Dirichlet allocation (LDA).
Quantum Annealing for Dirichlet Process Mixture Models with Applications to Network Clustering
May 19, 2013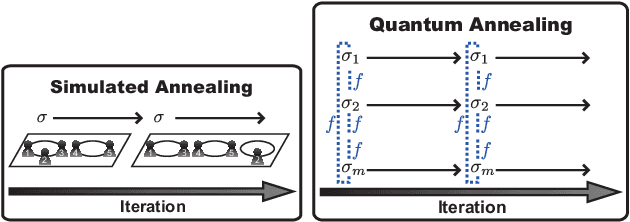
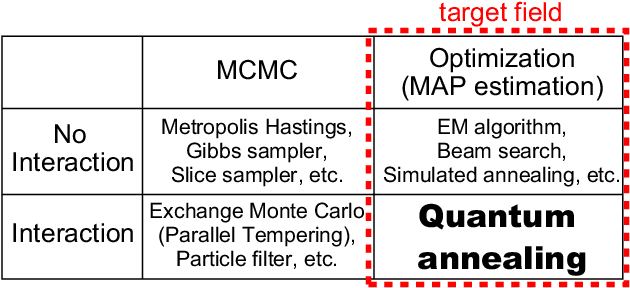

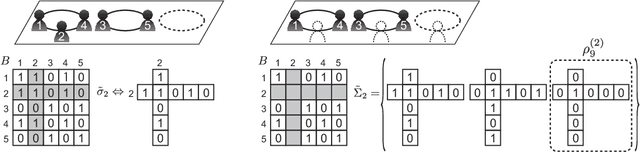
We developed a new quantum annealing (QA) algorithm for Dirichlet process mixture (DPM) models based on the Chinese restaurant process (CRP). QA is a parallelized extension of simulated annealing (SA), i.e., it is a parallel stochastic optimization technique. Existing approaches [Kurihara et al. UAI2009, Sato et al. UAI2009] and cannot be applied to the CRP because their QA framework is formulated using a fixed number of mixture components. The proposed QA algorithm can handle an unfixed number of classes in mixture models. We applied QA to a DPM model for clustering vertices in a network where a CRP seating arrangement indicates a network partition. A multi core processor was used for running QA in experiments, the results of which show that QA is better than SA, Markov chain Monte Carlo inference, and beam search at finding a maximum a posteriori estimation of a seating arrangement in the CRP. Since our QA algorithm is as easy as to implement the SA algorithm, it is suitable for a wide range of applications.
* 12 pages, 6 figures, accepted in Neurocomputing
Rethinking Collapsed Variational Bayes Inference for LDA
Jun 27, 2012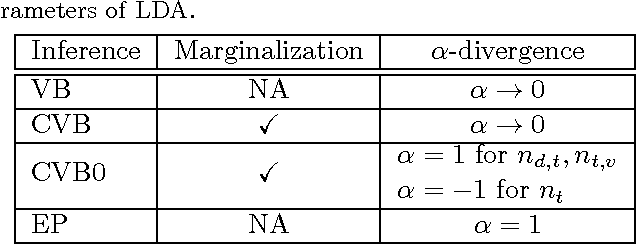
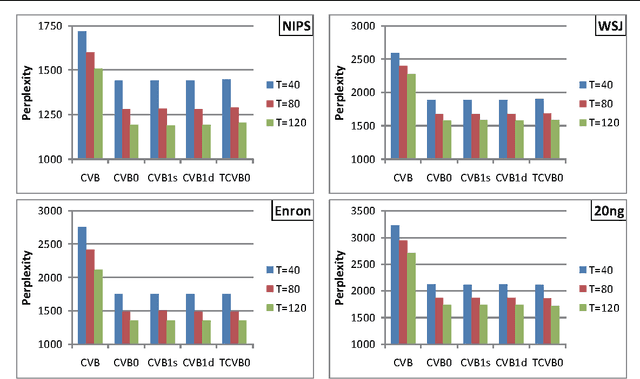
We propose a novel interpretation of the collapsed variational Bayes inference with a zero-order Taylor expansion approximation, called CVB0 inference, for latent Dirichlet allocation (LDA). We clarify the properties of the CVB0 inference by using the alpha-divergence. We show that the CVB0 inference is composed of two different divergence projections: alpha=1 and -1. This interpretation will help shed light on CVB0 works.
Restricted Collapsed Draw: Accurate Sampling for Hierarchical Chinese Restaurant Process Hidden Markov Models
Jun 02, 2011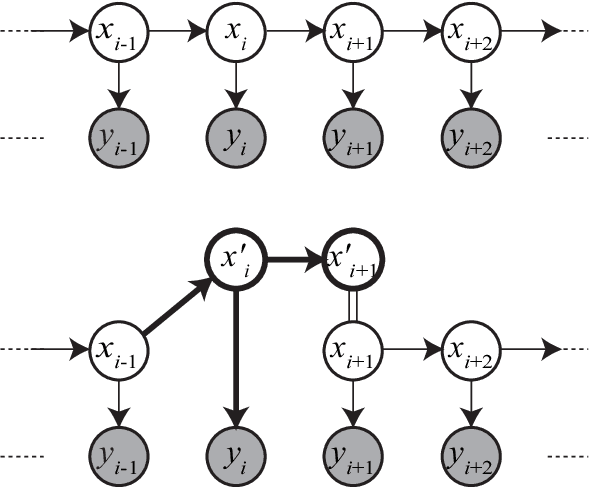
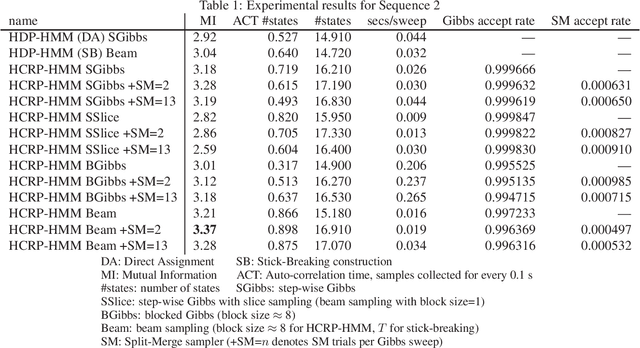
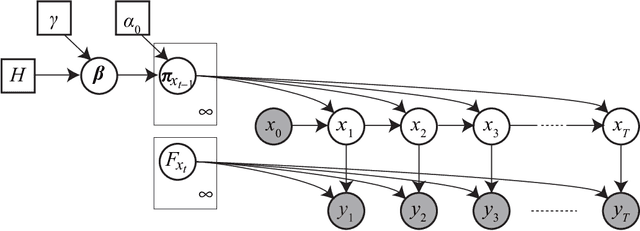
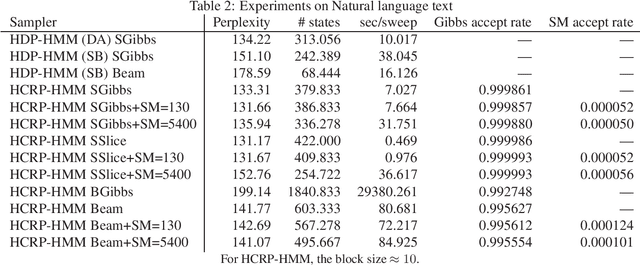
We propose a restricted collapsed draw (RCD) sampler, a general Markov chain Monte Carlo sampler of simultaneous draws from a hierarchical Chinese restaurant process (HCRP) with restriction. Models that require simultaneous draws from a hierarchical Dirichlet process with restriction, such as infinite Hidden markov models (iHMM), were difficult to enjoy benefits of \markerg{the} HCRP due to combinatorial explosion in calculating distributions of coupled draws. By constructing a proposal of seating arrangements (partitioning) and stochastically accepts the proposal by the Metropolis-Hastings algorithm, the RCD sampler makes accurate sampling for complex combination of draws while retaining efficiency of HCRP representation. Based on the RCD sampler, we developed a series of sophisticated sampling algorithms for iHMMs, including blocked Gibbs sampling, beam sampling, and split-merge sampling, that outperformed conventional iHMM samplers in experiments