 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacter-level Japanese Text Generation with Attention Mechanism for Chest Radiography Diagnosis
Apr 06, 2020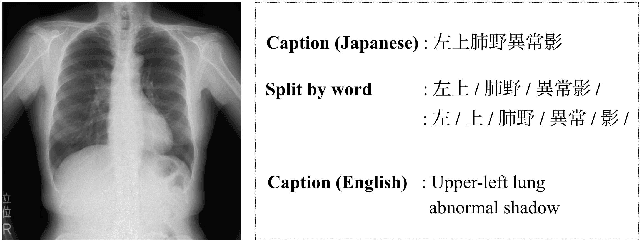

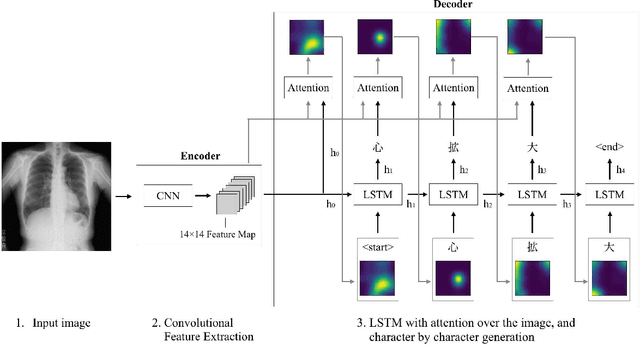
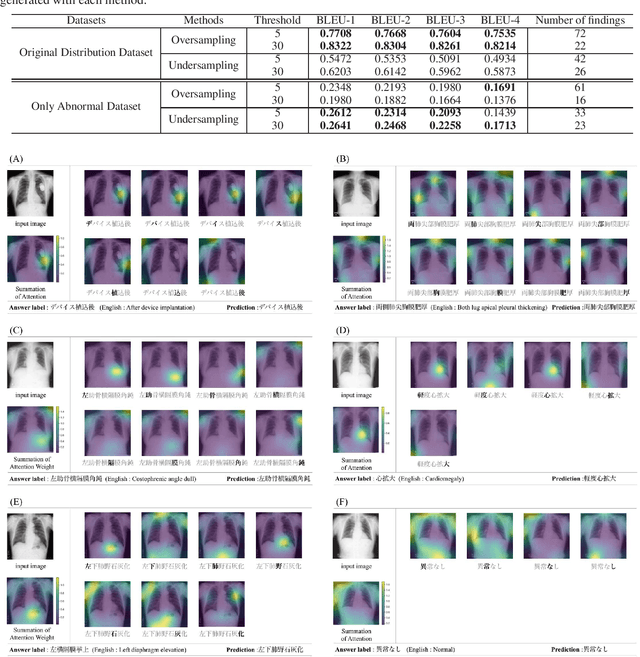
Chest radiography is a general method for diagnosing a patient's condition and identifying important information; therefore, radiography is used extensively in routine medical practice in various situations, such as emergency medical care and medical checkup. However, a high level of expertise is required to interpret chest radiographs. Thus, medical specialists spend considerable time in diagnosing such huge numbers of radiographs. In order to solve these problems, methods for generating findings have been proposed. However, the study of generating chest radiograph findings has primarily focused on the English language, and to the best of our knowledge, no studies have studied Japanese data on this subject. There are two challenges involved in generating findings in the Japanese language. The first challenge is that word splitting is difficult because the boundaries of Japanese word are not clear. The second challenge is that there are numerous orthographic variants. For deal with these two challenges, we proposed an end-to-end model that generates Japanese findings at the character-level from chest radiographs. In addition, we introduced the attention mechanism to improve not only the accuracy, but also the interpretation ability of the results. We evaluated the proposed method using a public dataset with Japanese findings. The effectiveness of the proposed method was confirmed using the Bilingual Evaluation Understudy score. And, we were confirmed from the generated findings that the proposed method was able to consider the orthographic variants. Furthermore, we confirmed via visual inspection that the attention mechanism captures the features and positional information of radiographs.
Improving Bi-directional Generation between Different Modalities with Variational Autoencoders
Jan 26, 2018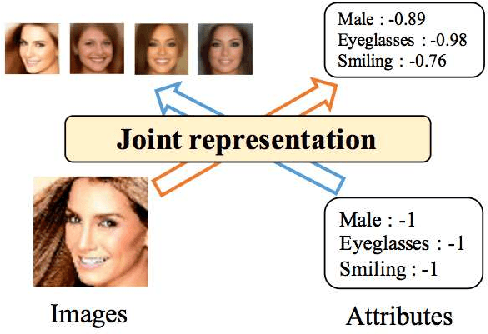
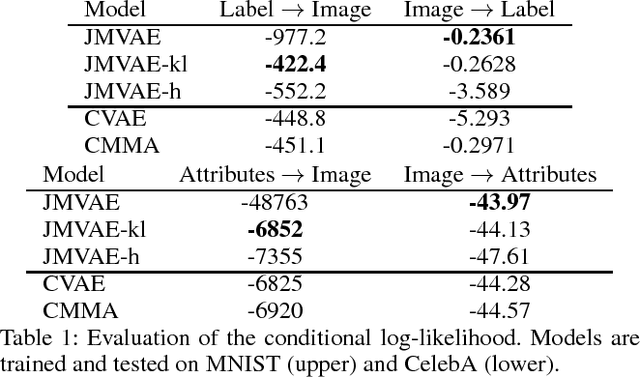
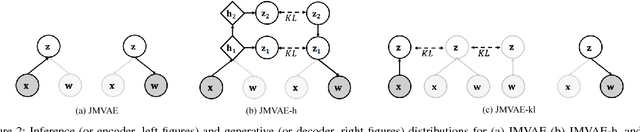

We investigate deep generative models that can exchange multiple modalities bi-directionally, e.g., generating images from corresponding texts and vice versa. A major approach to achieve this objective is to train a model that integrates all the information of different modalities into a joint representation and then to generate one modality from the corresponding other modality via this joint representation. We simply applied this approach to variational autoencoders (VAEs), which we call a joint multimodal variational autoencoder (JMVAE). However, we found that when this model attempts to generate a large dimensional modality missing at the input, the joint representation collapses and this modality cannot be generated successfully. Furthermore, we confirmed that this difficulty cannot be resolved even using a known solution. Therefore, in this study, we propose two models to prevent this difficulty: JMVAE-kl and JMVAE-h. Results of our experiments demonstrate that these methods can prevent the difficulty above and that they generate modalities bi-directionally with equal or higher likelihood than conventional VAE methods, which generate in only one direction. Moreover, we confirm that these methods can obtain the joint representation appropriately, so that they can generate various variations of modality by moving over the joint representation or changing the value of another modality.
Okutama-Action: An Aerial View Video Dataset for Concurrent Human Action Detection
Jun 15, 2017
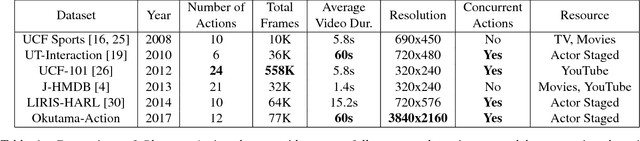
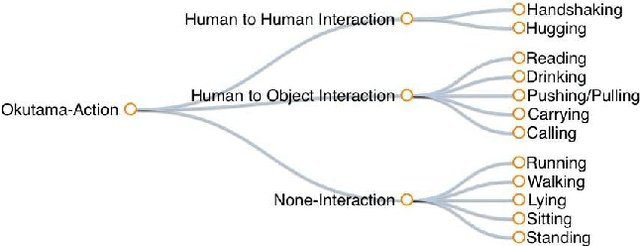
Despite significant progress in the development of human action detection datasets and algorithms, no current dataset is representative of real-world aerial view scenarios. We present Okutama-Action, a new video dataset for aerial view concurrent human action detection. It consists of 43 minute-long fully-annotated sequences with 12 action classes. Okutama-Action features many challenges missing in current datasets, including dynamic transition of actions, significant changes in scale and aspect ratio, abrupt camera movement, as well as multi-labeled actors. As a result, our dataset is more challenging than existing ones, and will help push the field forward to enable real-world applications.
Neural Machine Translation with Latent Semantic of Image and Text
Nov 25, 2016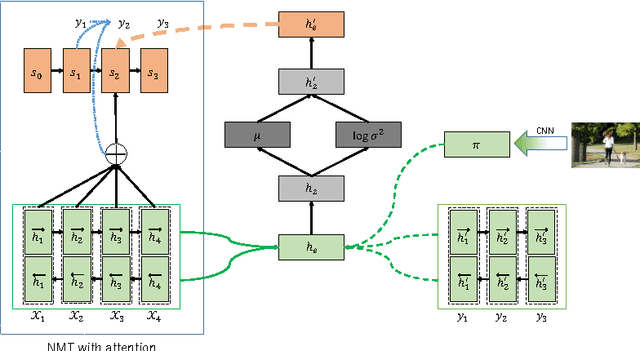
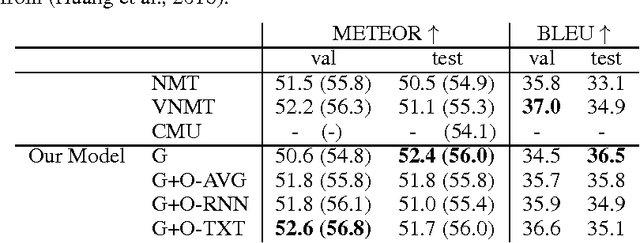
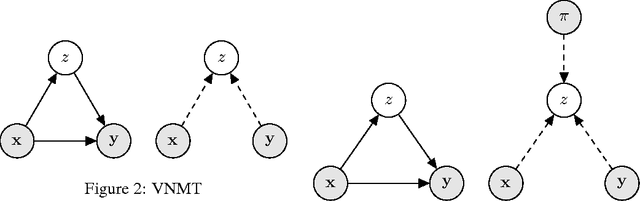
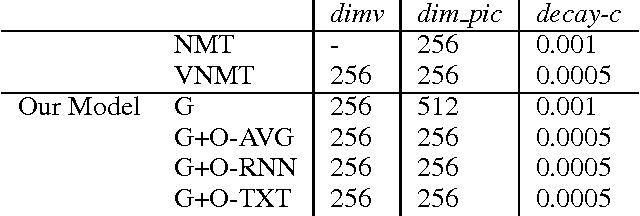
Although attention-based Neural Machine Translation have achieved great success, attention-mechanism cannot capture the entire meaning of the source sentence because the attention mechanism generates a target word depending heavily on the relevant parts of the source sentence. The report of earlier studies has introduced a latent variable to capture the entire meaning of sentence and achieved improvement on attention-based Neural Machine Translation. We follow this approach and we believe that the capturing meaning of sentence benefits from image information because human beings understand the meaning of language not only from textual information but also from perceptual information such as that gained from vision. As described herein, we propose a neural machine translation model that introduces a continuous latent variable containing an underlying semantic extracted from texts and images. Our model, which can be trained end-to-end, requires image information only when training. Experiments conducted with an English--German translation task show that our model outperforms over the baseline.
Generative Adversarial Nets from a Density Ratio Estimation Perspective
Nov 09, 2016

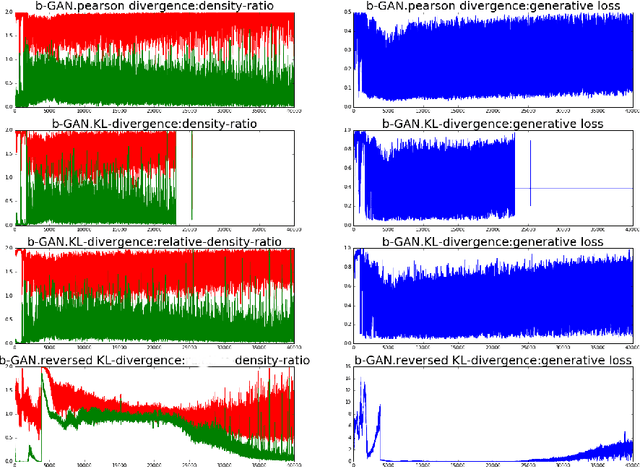
Generative adversarial networks (GANs) are successful deep generative models. GANs are based on a two-player minimax game. However, the objective function derived in the original motivation is changed to obtain stronger gradients when learning the generator. We propose a novel algorithm that repeats the density ratio estimation and f-divergence minimization. Our algorithm offers a new perspective toward the understanding of GANs and is able to make use of multiple viewpoints obtained in the research of density ratio estimation, e.g. what divergence is stable and relative density ratio is useful.
Joint Multimodal Learning with Deep Generative Models
Nov 07, 2016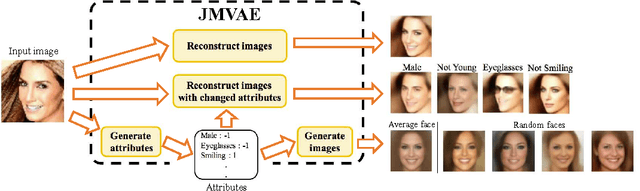

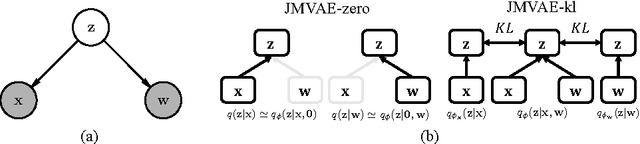

We investigate deep generative models that can exchange multiple modalities bi-directionally, e.g., generating images from corresponding texts and vice versa. Recently, some studies handle multiple modalities on deep generative models, such as variational autoencoders (VAEs). However, these models typically assume that modalities are forced to have a conditioned relation, i.e., we can only generate modalities in one direction. To achieve our objective, we should extract a joint representation that captures high-level concepts among all modalities and through which we can exchange them bi-directionally. As described herein, we propose a joint multimodal variational autoencoder (JMVAE), in which all modalities are independently conditioned on joint representation. In other words, it models a joint distribution of modalities. Furthermore, to be able to generate missing modalities from the remaining modalities properly, we develop an additional method, JMVAE-kl, that is trained by reducing the divergence between JMVAE's encoder and prepared networks of respective modalities. Our experiments show that our proposed method can obtain appropriate joint representation from multiple modalities and that it can generate and reconstruct them more properly than conventional VAEs. We further demonstrate that JMVAE can generate multiple modalities bi-directionally.