 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-shot Domain Adaptation by Causal Mechanism Transfer
Feb 10, 2020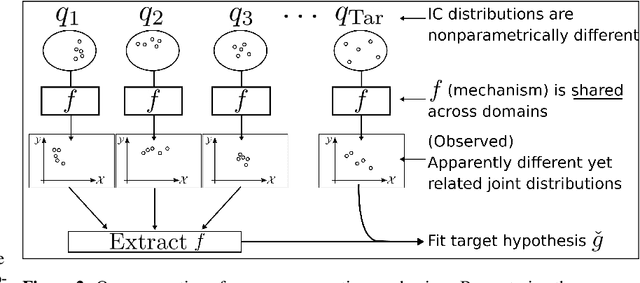
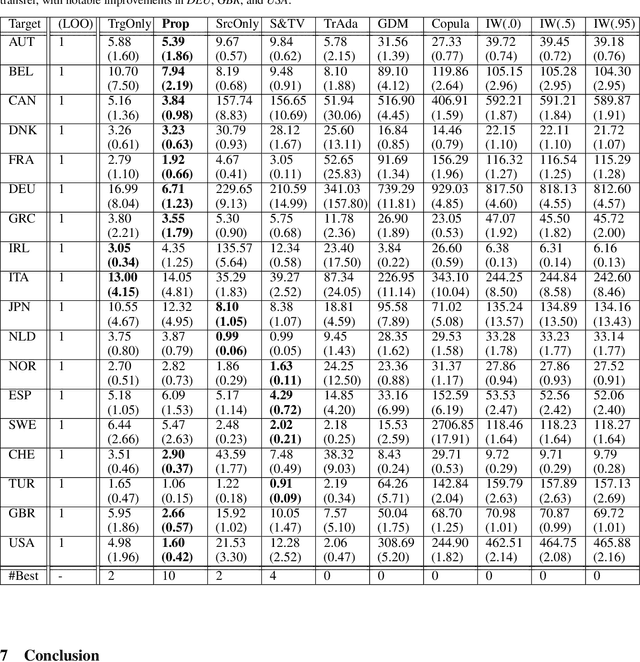

We study few-shot supervised domain adaptation (DA) for regression problems, where only a few labeled target domain data and many labeled source domain data are available. Many of the current DA methods base their transfer assumptions on either parametrized distribution shift or apparent distribution similarities, e.g., identical conditionals or small distributional discrepancies. However, these assumptions may preclude the possibility of adaptation from intricately shifted and apparently very different distributions. To overcome this problem, we propose mechanism transfer, a meta-distributional scenario in which a data generating mechanism is invariant among domains. This transfer assumption can accommodate nonparametric shifts resulting in apparently different distributions while providing a solid statistical basis for DA. We take the structural equations in causal modeling as an example and propose a novel DA method, which is shown to be useful both theoretically and experimentally. Our method can be seen as the first attempt to fully leverage the structural causal models for DA.
Bayesian interpretation of SGD as Ito process
Nov 20, 2019
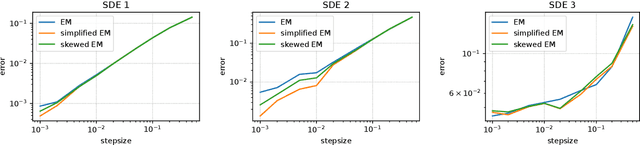

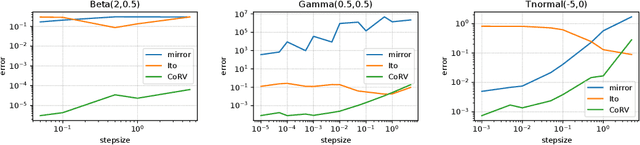
The current interpretation of stochastic gradient descent (SGD) as a stochastic process lacks generality in that its numerical scheme restricts continuous-time dynamics as well as the loss function and the distribution of gradient noise. We introduce a simplified scheme with milder conditions that flexibly interprets SGD as a discrete-time approximation of an Ito process. The scheme also works as a common foundation of SGD and stochastic gradient Langevin dynamics (SGLD), providing insights into their asymptotic properties. We investigate the convergence of SGD with biased gradient in terms of the equilibrium mode and the overestimation problem of the second moment of SGLD.
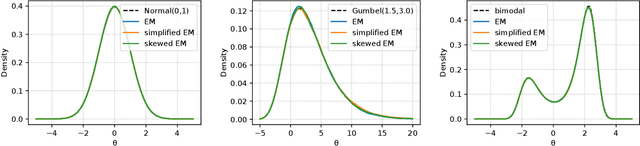
Classification from Triplet Comparison Data
Aug 05, 2019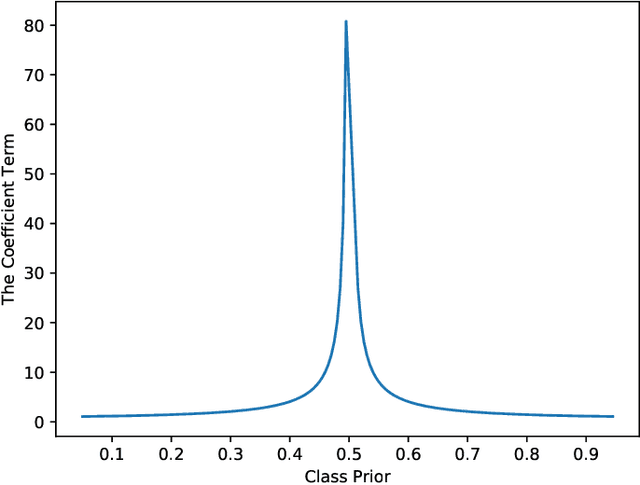
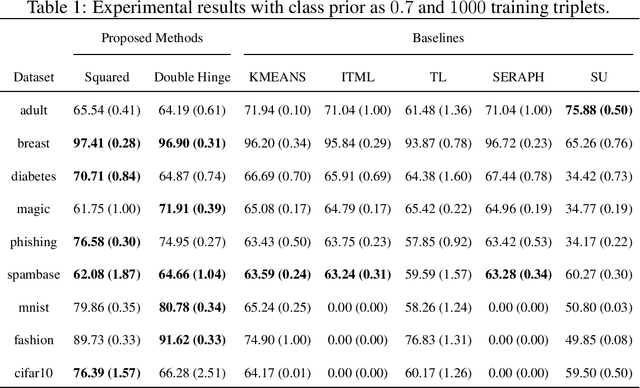
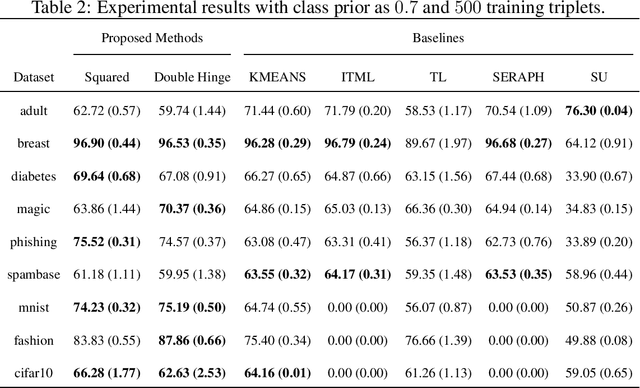

Learning from triplet comparison data has been extensively studied in the context of metric learning, where we want to learn a distance metric between two instances, and ordinal embedding, where we want to learn an embedding in an Euclidean space of the given instances that preserves the comparison order as well as possible. Unlike fully-labeled data, triplet comparison data can be collected in a more accurate and human-friendly way. Although learning from triplet comparison data has been considered in many applications, an important fundamental question of whether we can learn a classifier only from triplet comparison data has remained unanswered. In this paper, we give a positive answer to this important question by proposing an unbiased estimator for the classification risk under the empirical risk minimization framework. Since the proposed method is based on the empirical risk minimization framework, it inherently has the advantage that any surrogate loss function and any model, including neural networks, can be easily applied. Furthermore, we theoretically establish an estimation error bound for the proposed empirical risk minimizer. Finally, we provide experimental results to show that our method empirically works well and outperforms various baseline methods.
Interactive Subspace Exploration on Generative Image Modelling
Jun 27, 2019


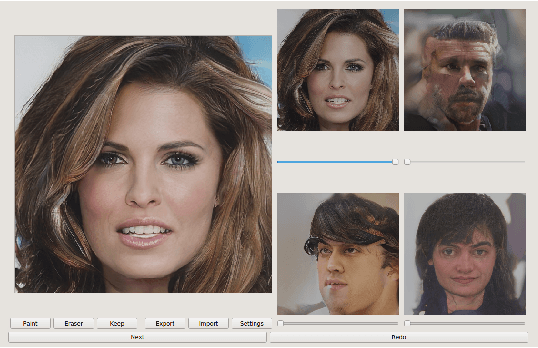
Generative image modeling techniques such as GAN demonstrate highly convincing image generation result. However, user interaction is often necessary to obtain the desired results. Existing attempts add interactivity but require either tailored architectures or extra data. We present a human-in-the-optimization method that allows users to directly explore and search the latent vector space of generative image modeling. Our system provides multiple candidates by sampling the latent vector space, and the user selects the best blending weights within the subspace using multiple sliders. In addition, the user can express their intention through image editing tools. The system samples latent vectors based on inputs and presents new candidates to the user iteratively. An advantage of our formulation is that one can apply our method to arbitrary pre-trained model without developing specialized architecture or data. We demonstrate our method with various generative image modeling applications, and show superior performance in a comparative user study with prior art iGAN \cite{iGAN2016}.
Solving NP-Hard Problems on Graphs by Reinforcement Learning without Domain Knowledge
May 28, 2019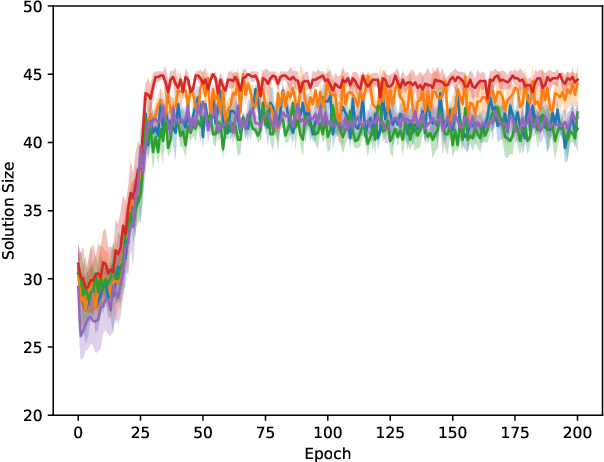
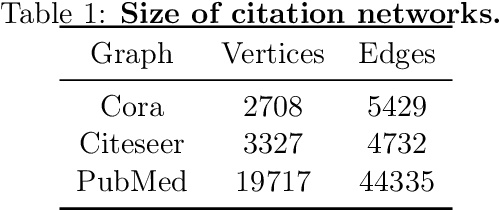

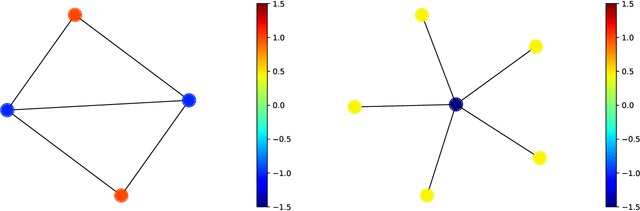
We propose an algorithm based on reinforcement learning for solving NP-hard problems on graphs. We combine Graph Isomorphism Networks and the Monte-Carlo Tree Search, which was originally used for game searches, for solving combinatorial optimization on graphs. Similarly to AlphaGo Zero, our method does not require any problem-specific knowledge or labeled datasets (exact solutions), which are difficult to calculate in principle. We show that our method, which is trained by generated random graphs, successfully finds near-optimal solutions for the Maximum Independent Set problem on citation networks. Experiments illustrate that the performance of our method is comparable to SOTA solvers, but we do not require any problem-specific reduction rules, which is highly desirable in practice since collecting hand-crafted reduction rules is costly and not adaptive for a wide range of problems.
Directing DNNs Attention for Facial Attribution Classification using Gradient-weighted Class Activation Mapping
May 02, 2019
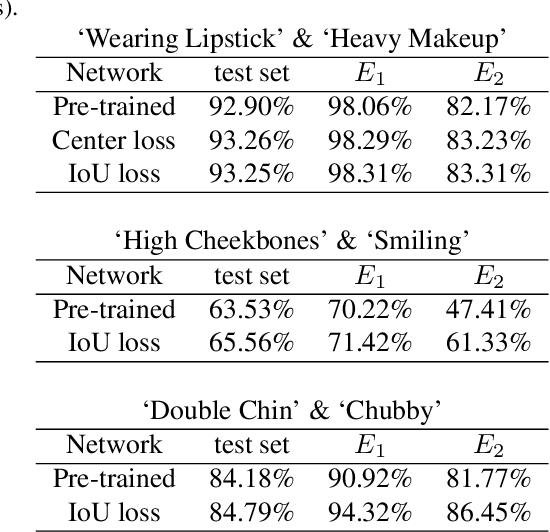
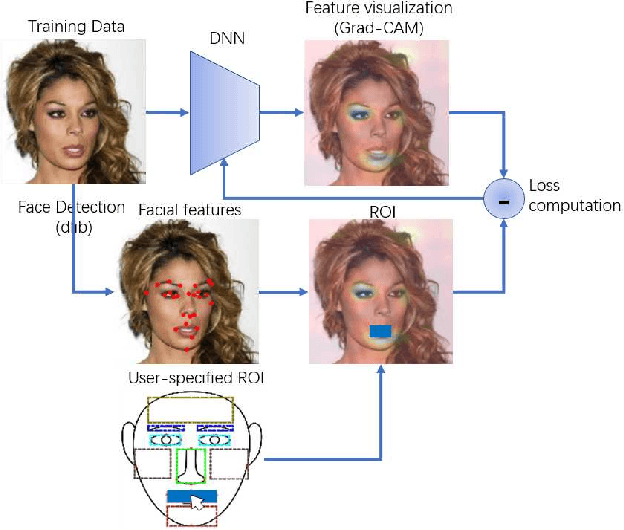
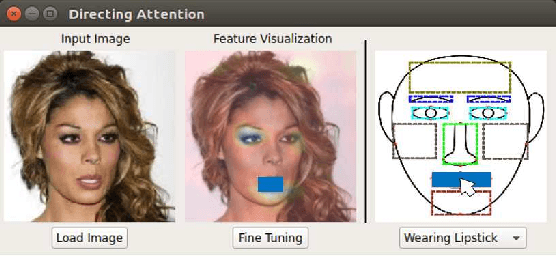
Deep neural networks (DNNs) have a high accuracy on image classification tasks. However, DNNs trained by such dataset with co-occurrence bias may rely on wrong features while making decisions for classification. It will greatly affect the transferability of pre-trained DNNs. In this paper, we propose an interactive method to direct classifiers paying attentions to the regions that are manually specified by the users, in order to mitigate the influence of co-occurrence bias. We test on CelebA dataset, the pre-trained AlexNet is fine-tuned to focus on the specific facial attributes based on the results of Grad-CAM.
Classification from Pairwise Similarities/Dissimilarities and Unlabeled Data via Empirical Risk Minimization
Apr 26, 2019
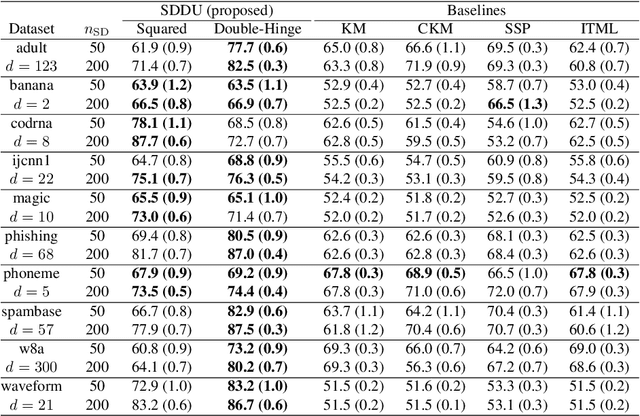
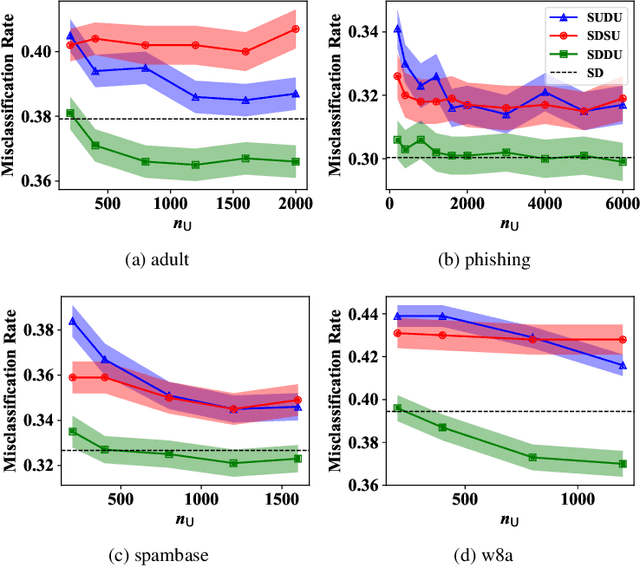
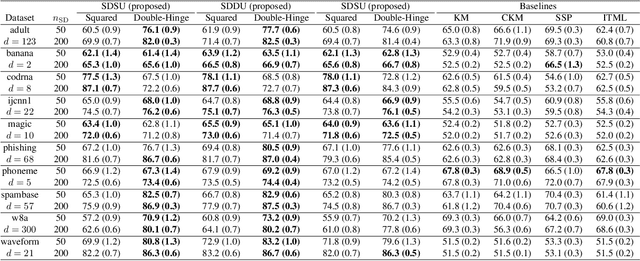
Pairwise similarities and dissimilarities between data points might be easier to obtain than fully labeled data in real-world classification problems, e.g., in privacy-aware situations. To handle such pairwise information, an empirical risk minimization approach has been proposed, giving an unbiased estimator of the classification risk that can be computed only from pairwise similarities and unlabeled data. However, this direction cannot handle pairwise dissimilarities so far. On the other hand, semi-supervised clustering is one of the methods which can use both similarities and dissimilarities. Nevertheless, they typically require strong geometrical assumptions on the data distribution such as the manifold assumption, which may deteriorate the performance. In this paper, we derive an unbiased risk estimator which can handle all of similarities/dissimilarities and unlabeled data. We theoretically establish estimation error bounds and experimentally demonstrate the practical usefulness of our empirical risk minimization method.
Use of Ghost Cytometry to Differentiate Cells with Similar Gross Morphologic Characteristics
Mar 22, 2019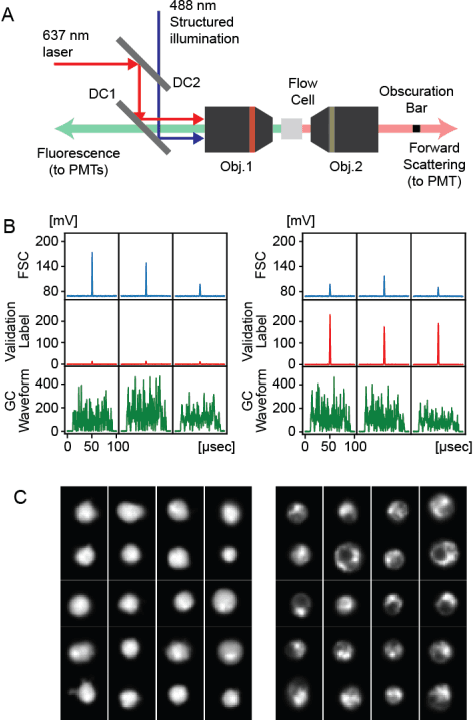
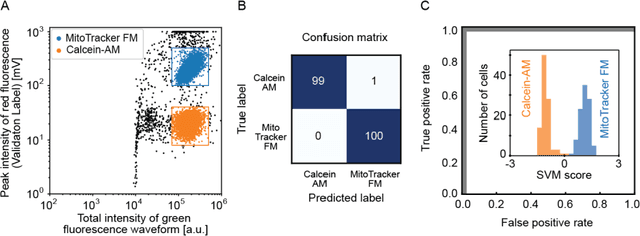
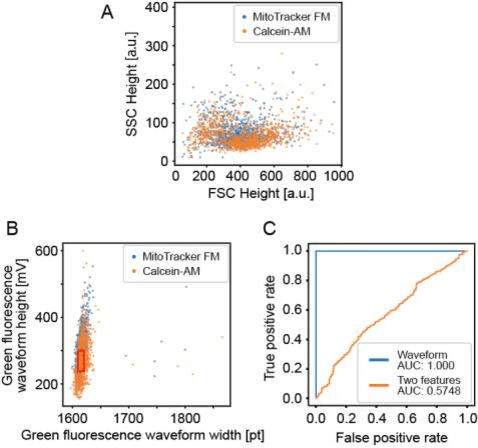
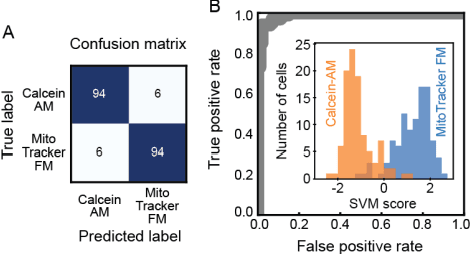
Imaging flow cytometry shows significant potential for increasing our understanding of heterogeneous and complex life systems and is useful for biomedical applications. Ghost cytometry is a recently proposed approach for directly analyzing compressively measured signals, thereby relieving the computational bottleneck observed in high-throughput cytometry based on morphological information. While this image-free approach could distinguish different cell types using the same fluorescence staining method, further strict controls are sometimes required to clearly demonstrate that the classification is based on detailed morphologic analysis. In this study, we show that ghost cytometry can be used to classify cell populations of the same type but with different fluorescence distributions in space, supporting the strength of our image-free approach for morphologic cell analysis.
On Learning from Ghost Imaging without Imaging
Mar 15, 2019Computational ghost imaging is an imaging technique with which an object is imaged from light collected using a single-pixel detector with no spatial resolution. Recently, ghost cytometry has been proposed for an ultrafast cell-classification method that involves ghost imaging and machine learning in flow cytometry. Ghost cytometry skipped the reconstruction of cell images from signals and directly used signals for cell-classification because this reconstruction is the bottleneck in a high-speed analysis. In this paper, we provide a theoretical analysis for learning from ghost imaging without imaging.
On Transformations in Stochastic Gradient MCMC
Mar 07, 2019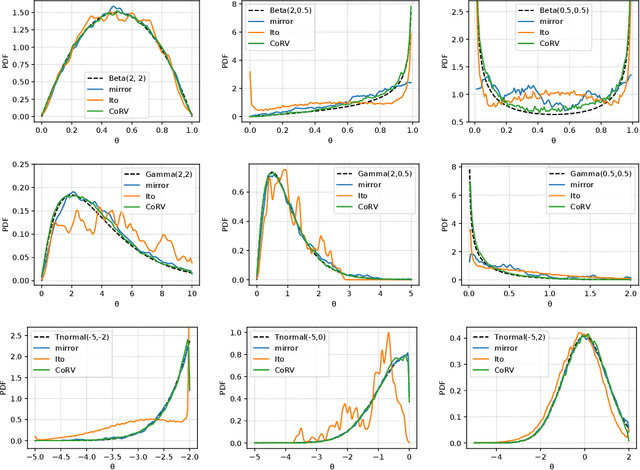

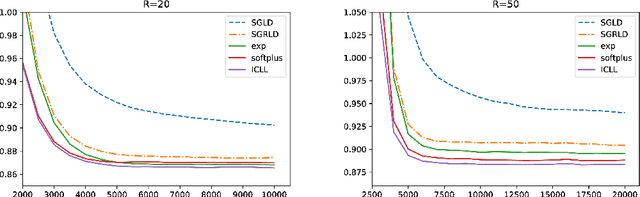
Stochastic gradient Langevin dynamics (SGLD) is a widely used sampler for the posterior inference with a large scale dataset. Although SGLD is designed for unbounded random variables, many practical models incorporate variables with boundaries such as non-negative ones or those in a finite interval. Existing modifications of SGLD for handling bounded random variables resort to heuristics without a formal guarantee of sampling from the true stationary distribution. In this paper, we reformulate the SGLD algorithm incorporating a deterministic transformation with rigorous theories. Our method transforms unbounded samples obtained by SGLD into the domain of interest. We demonstrate transformed SGLD in both artificial problem settings and real-world applications of Bayesian non-negative matrix factorization and binary neural networks.