 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Neural Variability for Deep Learning: On Overfitting, Noise Memorization, and Catastrophic Forgetting
Nov 24, 2020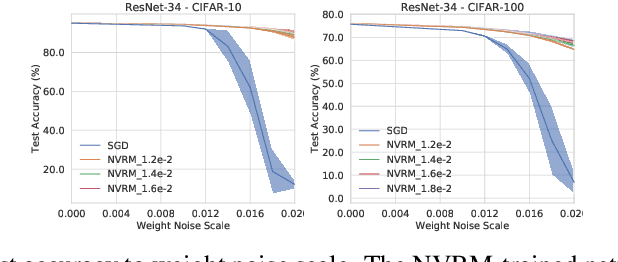
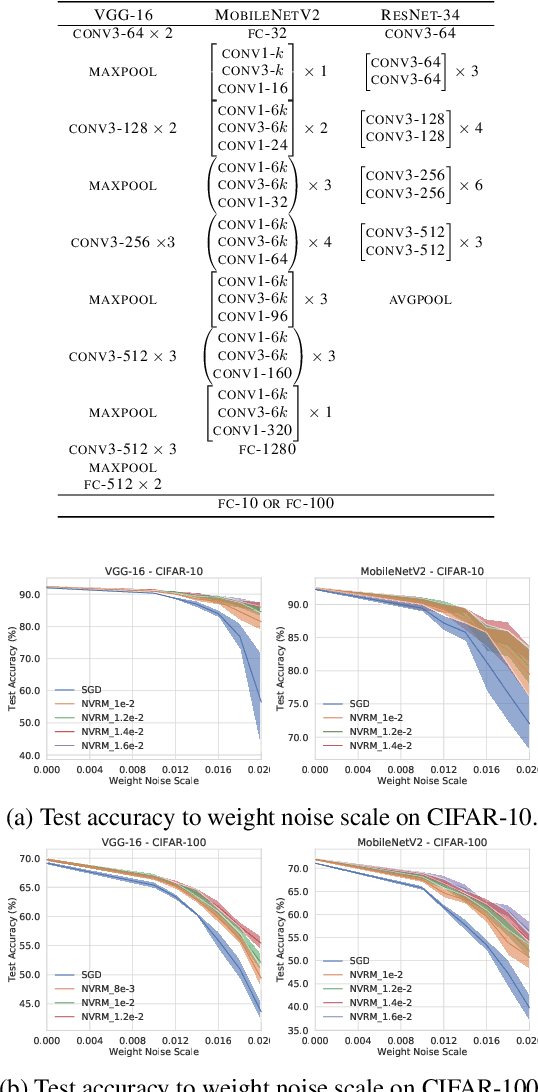
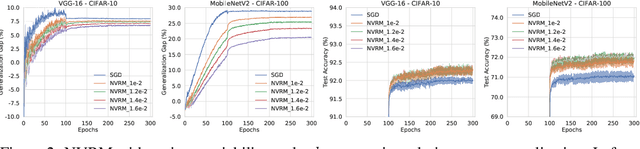
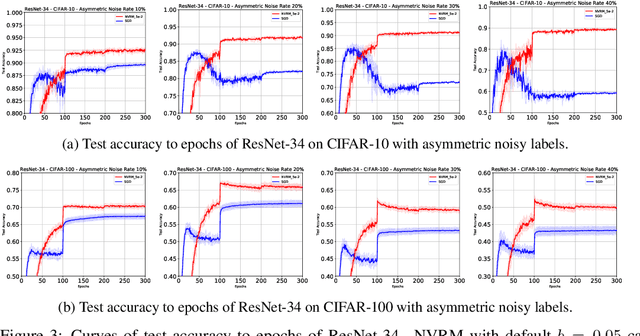
Deep learning is often criticized by two serious issues which rarely exist in natural nervous systems: overfitting and catastrophic forgetting. It can even memorize randomly labelled data, which has little knowledge behind the instance-label pairs. When a deep network continually learns over time by accommodating new tasks, it usually quickly overwrites the knowledge learned from previous tasks. Referred to as the neural variability, it is well-known in neuroscience that human brain reactions exhibit substantial variability even in response to the same stimulus. This mechanism balances accuracy and plasticity/flexibility in the motor learning of natural nervous systems. Thus it motivates us to design a similar mechanism named artificial neural variability (ANV), which helps artificial neural networks learn some advantages from "natural" neural networks. We rigorously prove that ANV plays as an implicit regularizer of the mutual information between the training data and the learned model. This result theoretically guarantees ANV a strictly improved generalizability, robustness to label noise, and robustness to catastrophic forgetting. We then devise a neural variable risk minimization (NVRM) framework and neural variable optimizers to achieve ANV for conventional network architectures in practice. The empirical studies demonstrate that NVRM can effectively relieve overfitting, label noise memorization, and catastrophic forgetting at negligible costs.
Classification from Ambiguity Comparisons
Aug 03, 2020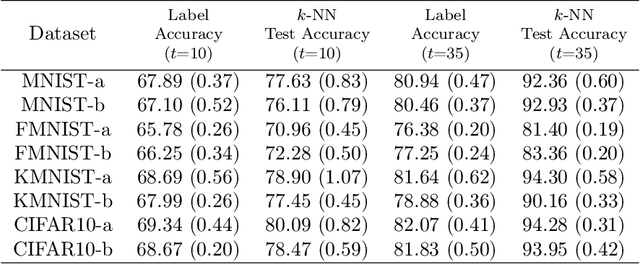
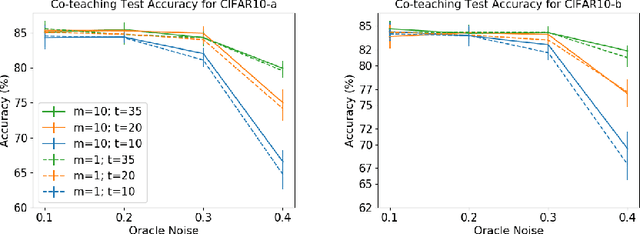
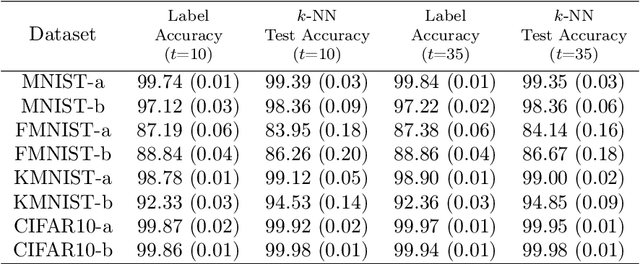
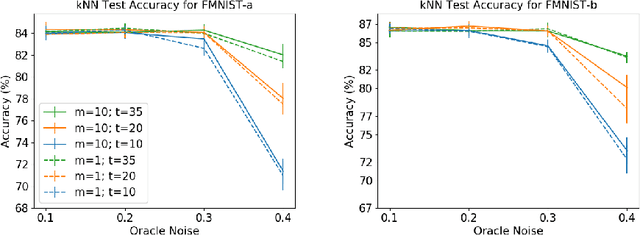
Labeling data is an unavoidable pre-processing procedure for most machine learning tasks. However, it takes a considerable amount of time, money, and labor to collect accurate \textit{explicit class labels} for a large dataset. A positivity comparison oracle has been adapted to relieve this burden, where two data points are received as input and the oracle answers which one is more likely to be positive. However, when information about the classification threshold is lacking, this oracle alone can at most rank all data points on the basis of their relative positivity; thus, it still needs to access explicit class labels. In order to harness pairwise comparisons in a more effective way, we propose an \textit{ambiguity comparison oracle}. This oracle also receives two data points as input, and it answers which one is more ambiguous, or more difficult to assign a label to. We then propose an efficient adaptive labeling algorithm that can actively query \textit{only pairwise comparison oracles} without accessing the explicit labeling oracle. We also address the situation where the labeling budget is insufficient compared to the dataset size, which can be dealt with by plugging the proposed algorithm into an active learning algorithm. Furthermore, we confirm the feasibility of the proposed oracle and the performance of the proposed labeling algorithms theoretically and empirically.
Adai: Separating the Effects of Adaptive Learning Rate and Momentum Inertia
Jul 17, 2020
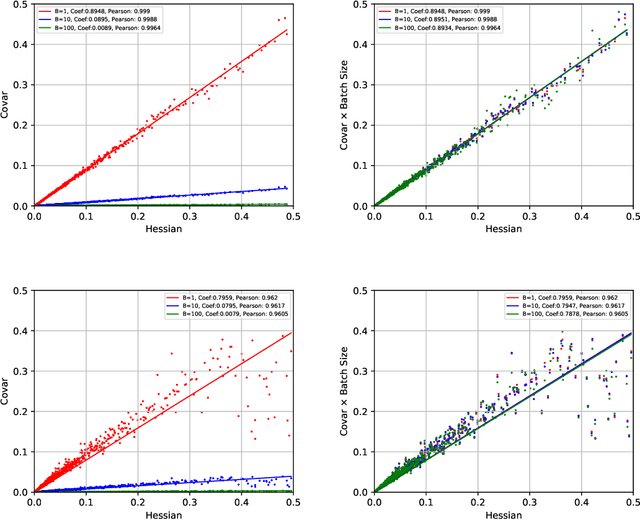
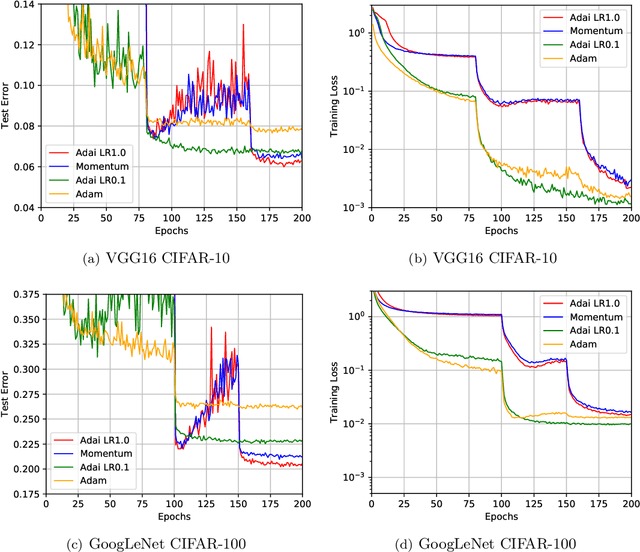
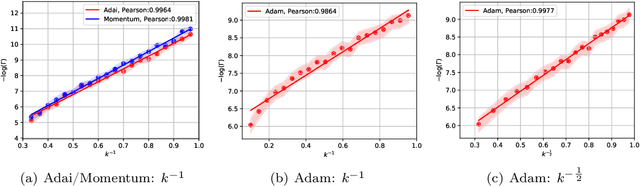
Adaptive Momentum Estimation (Adam), which combines Adaptive Learning Rate and Momentum, is the most popular stochastic optimizer for accelerating training of deep neural networks. But Adam often generalizes significantly worse than Stochastic Gradient Descent (SGD). It is still mathematically unclear how Adaptive Learning Rate and Momentum affect saddle-point escaping and minima selection. Based on the diffusion theoretical framework, we separate the effects of Adaptive Learning Rate and Momentum on saddle-point escaping and minima selection. We find that SGD escapes saddle points very slowly along the directions of small-magnitude eigenvalues of the Hessian. We prove that Adaptive Learning Rate can make learning dynamics near saddle points approximately Hessian-independent, but cannot select flat minima as SGD does. In contrast, Momentum provides a momentum drift effect to help passing through saddle points, and almost does not affect flat minima selection. This mathematically explains why SGD (with Momentum) generalizes better, while Adam generalizes worse but converges faster. Motivated by the diffusion theoretical analysis, we design a novel adaptive optimizer named Adaptive Inertia Estimation (Adai), which uses parameter-wise adaptive inertia to accelerate training and provably favors flat minima as much as SGD. Our real-world experiments demonstrate that Adai can converge similarly fast to Adam, but generalize significantly better. Adai even generalizes better than SGD, when converging fast to Adam is not required. The source is available to the public: \url{https://github.com/zeke-xie/adaptive-inertia-adai}.
Diagnostic Uncertainty Calibration: Towards Reliable Machine Predictions in Medical Domain
Jul 07, 2020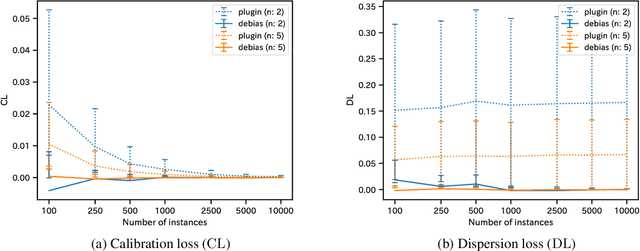

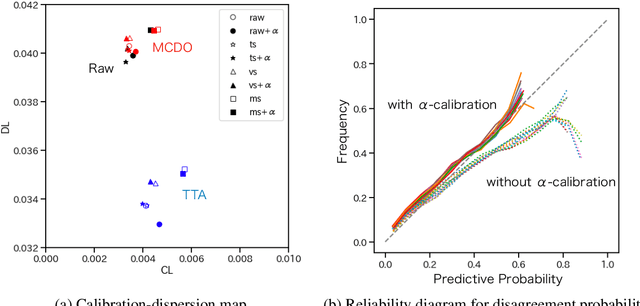
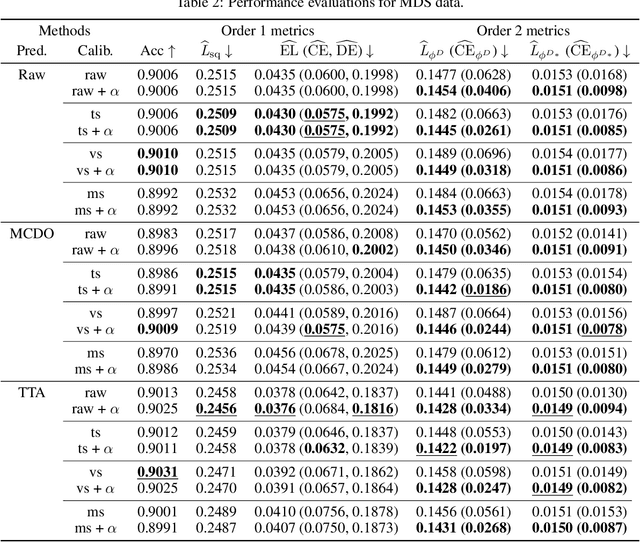
Label disagreement between human experts is a common issue in the medical domain and poses unique challenges in the evaluation and learning of classification models. In this work, we extend metrics for probability prediction, including calibration, i.e., the reliability of predictive probability, to adapt to such a situation. We further formalize the metrics for higher-order statistics, including inter-rater disagreement, in a unified way, which enables us to assess the quality of distributional uncertainty. In addition, we propose a novel post-hoc calibration method that equips trained neural networks with calibrated distributions over class probability estimates. With a large-scale medical imaging application, we show that our approach significantly improves the quality of uncertainty estimates in multiple metrics.
LFD-ProtoNet: Prototypical Network Based on Local Fisher Discriminant Analysis for Few-shot Learning
Jun 15, 2020
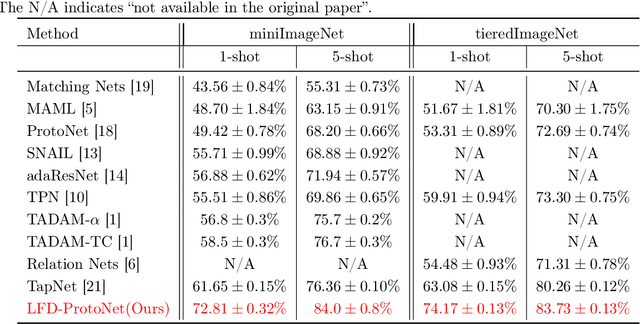
The prototypical network (ProtoNet) is a few-shot learning framework that performs metric learning and classification using the distance to prototype representations of each class. It has attracted a great deal of attention recently since it is simple to implement, highly extensible, and performs well in experiments. However, it only takes into account the mean of the support vectors as prototypes and thus it performs poorly when the support set has high variance. In this paper, we propose to combine ProtoNet with local Fisher discriminant analysis to reduce the local within-class covariance and increase the local between-class covariance of the support set. We show the usefulness of the proposed method by theoretically providing an expected risk bound and empirically demonstrating its superior classification accuracy on miniImageNet and tieredImageNet.
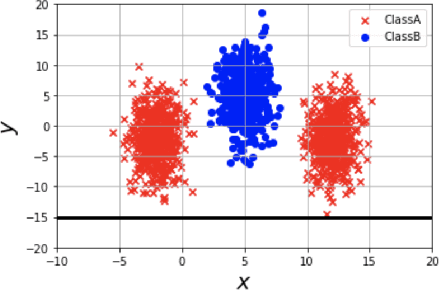
$γ$-ABC: Outlier-Robust Approximate Bayesian Computation based on Robust Divergence Estimator
Jun 13, 2020
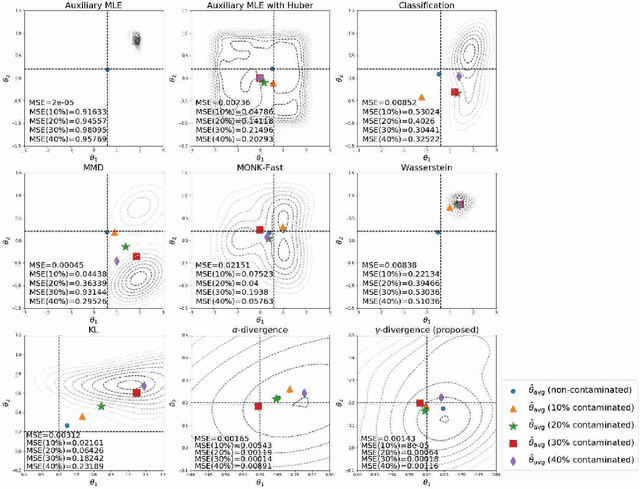
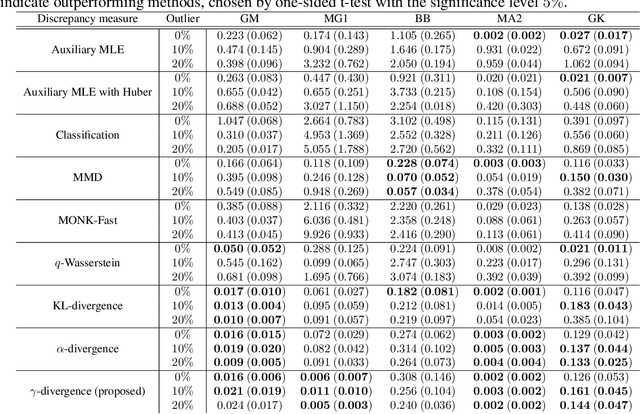
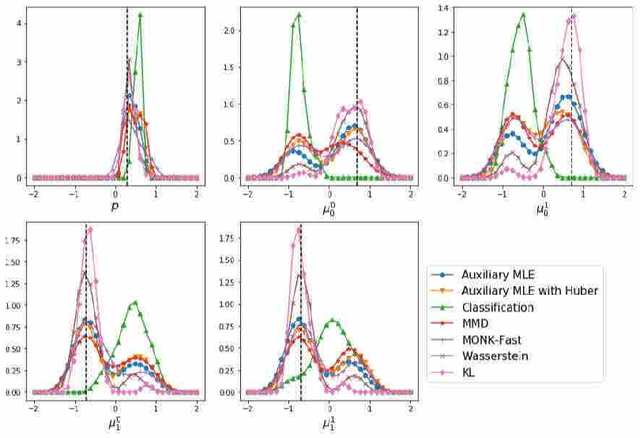
Making a reliable inference in complex models is an essential issue in statistical modeling. However, approximate Bayesian computation (ABC) proposed for highly complex models that have uncomputable likelihood is greatly affected by the sensitivity of the data discrepancy to outliers. Even using a data discrepancy with robust functions such as the Huber function does not entirely bypass its negative effects. In this paper, we propose a novel divergence estimator based on robust divergence and to use it as a data discrepancy in the ABC framework. Furthermore, we show that our estimator has an effective robustness property, known as the redescending property. Our estimator also enjoys ideal properties such as asymptotic unbiasedness, almost sure convergence, and linear time complexity. In ABC experiments on several models, we confirm that our method obtains a value closer to the true parameters than that of other discrepancy measures.
Similarity-based Classification: Connecting Similarity Learning to Binary Classification
Jun 11, 2020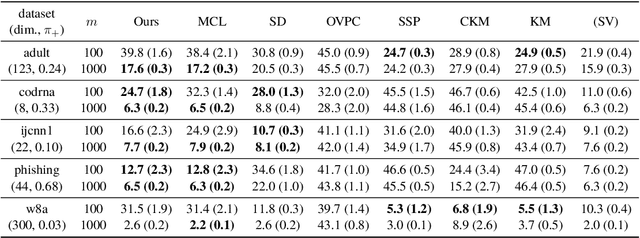
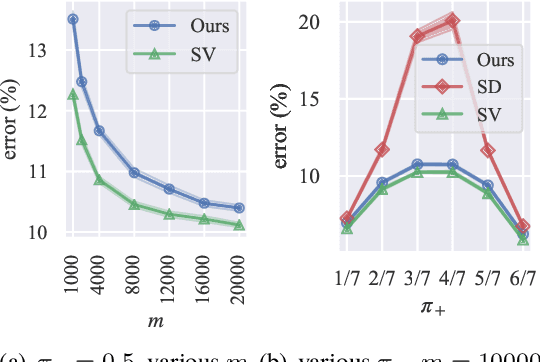
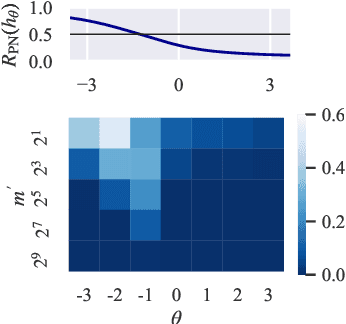
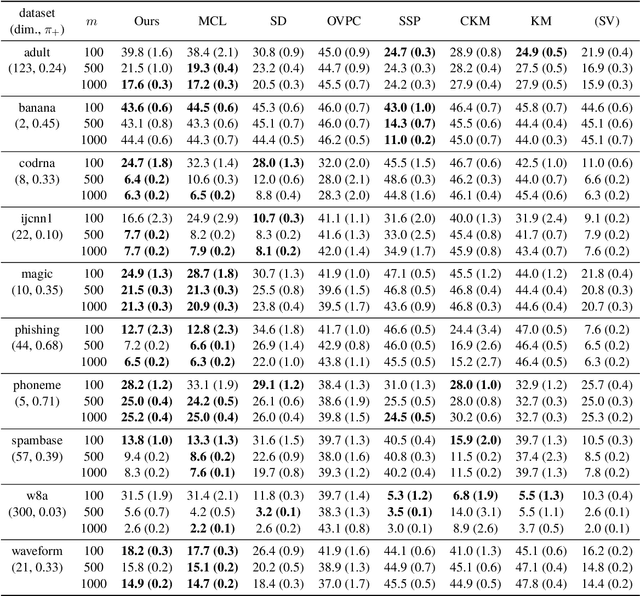
In real-world classification problems, pairwise supervision (i.e., a pair of patterns with a binary label indicating whether they belong to the same class or not) can often be obtained at a lower cost than ordinary class labels. Similarity learning is a general framework to utilize such pairwise supervision to elicit useful representations by inferring the relationship between two data points, which encompasses various important preprocessing tasks such as metric learning, kernel learning, graph embedding, and contrastive representation learning. Although elicited representations are expected to perform well in downstream tasks such as classification, little theoretical insight has been given in the literature so far. In this paper, we reveal that a specific formulation of similarity learning is strongly related to the objective of binary classification, which spurs us to learn a binary classifier without ordinary class labels---by fitting the product of real-valued prediction functions of pairwise patterns to their similarity. Our formulation of similarity learning does not only generalize many existing ones, but also admits an excess risk bound showing an explicit connection to classification. Finally, we empirically demonstrate the practical usefulness of the proposed method on benchmark datasets.
Sequential Gallery for Interactive Visual Design Optimization
May 08, 2020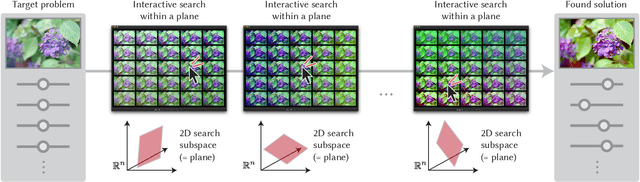
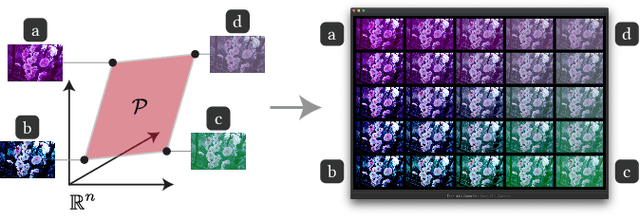


Visual design tasks often involve tuning many design parameters. For example, color grading of a photograph involves many parameters, some of which non-expert users might be unfamiliar with. We propose a novel user-in-the-loop optimization method that allows users to efficiently find an appropriate parameter set by exploring such a high-dimensional design space through much easier two-dimensional search subtasks. This method, called sequential plane search, is based on Bayesian optimization to keep necessary queries to users as few as possible. To help users respond to plane-search queries, we also propose using a gallery-based interface that provides options in the two-dimensional subspace arranged in an adaptive grid view. We call this interactive framework Sequential Gallery since users sequentially select the best option from the options provided by the interface. Our experiment with synthetic functions shows that our sequential plane search can find satisfactory solutions in fewer iterations than baselines. We also conducted a preliminary user study, results of which suggest that novices can effectively complete search tasks with Sequential Gallery in a photo-enhancement scenario.
* To be published at ACM Trans. Graph. (Proc. SIGGRAPH 2020); Project page available at https://koyama.xyz/project/sequential_gallery/
Time-varying Gaussian Process Bandit Optimization with Non-constant Evaluation Time
Mar 11, 2020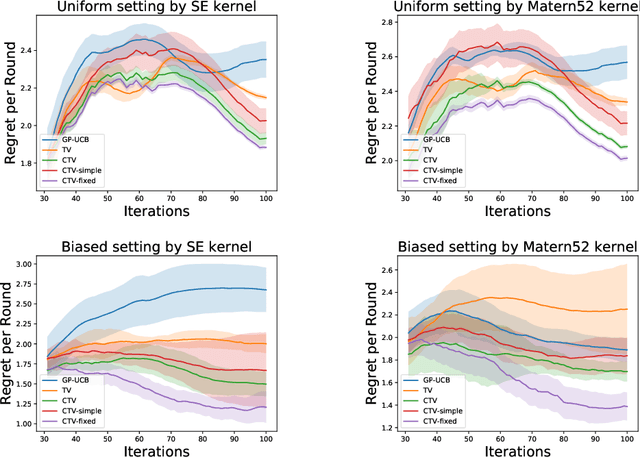
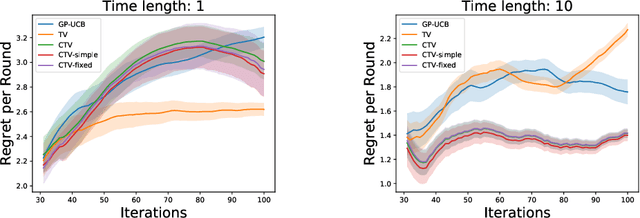
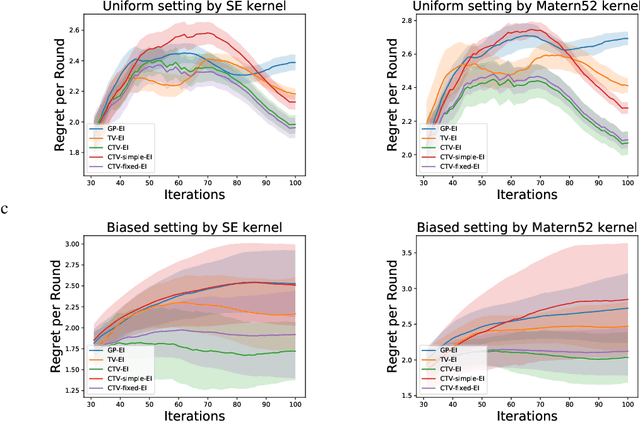
The Gaussian process bandit is a problem in which we want to find a maximizer of a black-box function with the minimum number of function evaluations. If the black-box function varies with time, then time-varying Bayesian optimization is a promising framework. However, a drawback with current methods is in the assumption that the evaluation time for every observation is constant, which can be unrealistic for many practical applications, e.g., recommender systems and environmental monitoring. As a result, the performance of current methods can be degraded when this assumption is violated. To cope with this problem, we propose a novel time-varying Bayesian optimization algorithm that can effectively handle the non-constant evaluation time. Furthermore, we theoretically establish a regret bound of our algorithm. Our bound elucidates that a pattern of the evaluation time sequence can hugely affect the difficulty of the problem. We also provide experimental results to validate the practical effectiveness of the proposed method.
A Diffusion Theory for Deep Learning Dynamics: Stochastic Gradient Descent Escapes From Sharp Minima Exponentially Fast
Mar 05, 2020
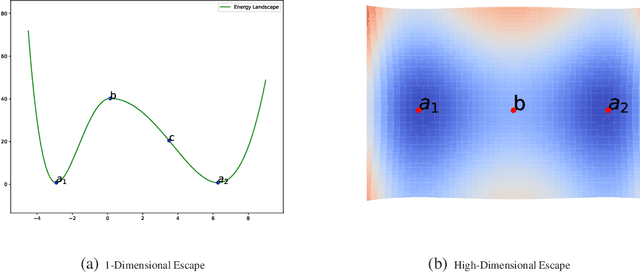
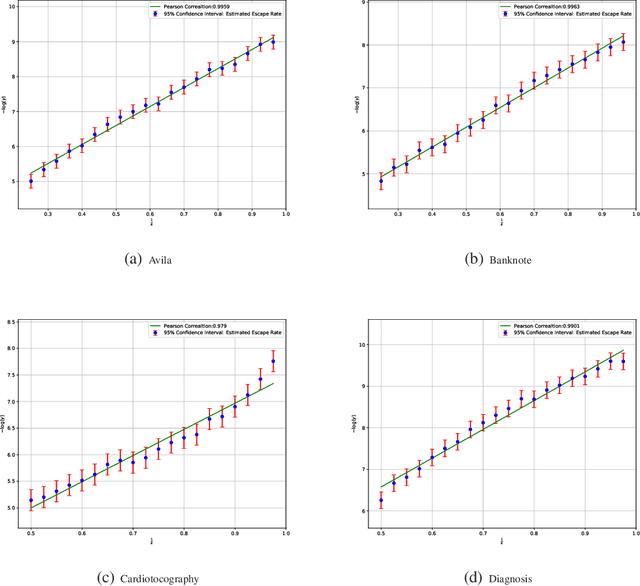
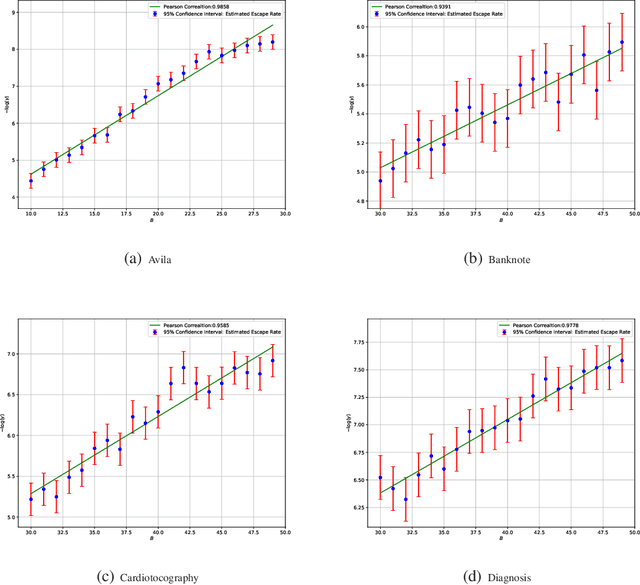
Stochastic optimization algorithms, such as Stochastic Gradient Descent (SGD) and its variants, are mainstream methods for training deep networks in practice. However, the theoretical mechanism behind gradient noise still remains to be further investigated. Deep learning is known to find flat minima with a large neighboring region in parameter space from which each weight vector has similar small error. In this paper, we focus on a fundamental problem in deep learning, "How can deep learning usually find flat minima among so many minima?" To answer the question, we develop a density diffusion theory (DDT) for revealing the fundamental dynamical mechanism of SGD and deep learning. More specifically, we study how escape time from loss valleys to the outside of valleys depends on minima sharpness, gradient noise and hyperparameters. One of the most interesting findings is that stochastic gradient noise from SGD can help escape from sharp minima exponentially faster than flat minima, while white noise can only help escape from sharp minima polynomially faster than flat minima. We also find large-batch training requires exponentially many iterations to pass through sharp minima and find flat minima. We present direct empirical evidence supporting the proposed theoretical results.