 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeF5-TTS-RO: Extending F5-TTS to Romanian TTS via Lightweight Input Adaptation
Dec 13, 2025This work introduces a lightweight input-level adapter for the F5-TTS model that enables Romanian Language support. To preserve the existing capabilities of the model (voice cloning, English and Chinese support), we keep the original weights frozen, append a sub-network to the model and train it as an extension for the textual embedding matrix of the text encoder. For simplicity, we rely on ConvNeXt module implemented in F5-TTS to also model the co-dependencies between the new character-level embeddings. The module serves as a ``soft`` letter-to-sound layer, converting Romanian text into a continuous representation that the F5-TTS model uses to produce naturally sounding Romanian utterances. We evaluate the model with a pool of 20 human listeners across three tasks: (a) audio similarity between reference and generated speech, (b) pronunciation and naturalness and (c) Romanian-English code-switching. The results indicate that our approach maintains voice cloning capabilities and enables, to a certain extent, code-switching within the same utterance; however, residual English accent characteristics remain. We open-source our code and provide example audio samples at https://github.com/racai-ro/Ro-F5TTS.
Generative Adversarial Training for Text-to-Speech Synthesis Based on Raw Phonetic Input and Explicit Prosody Modelling
Oct 14, 2023



We describe an end-to-end speech synthesis system that uses generative adversarial training. We train our Vocoder for raw phoneme-to-audio conversion, using explicit phonetic, pitch and duration modeling. We experiment with several pre-trained models for contextualized and decontextualized word embeddings and we introduce a new method for highly expressive character voice matching, based on discreet style tokens.
Tools and resources for Romanian text-to-speech and speech-to-text applications
Feb 15, 2018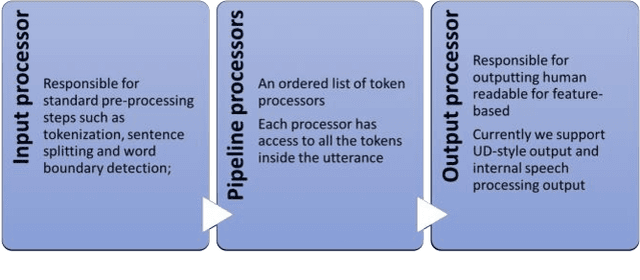
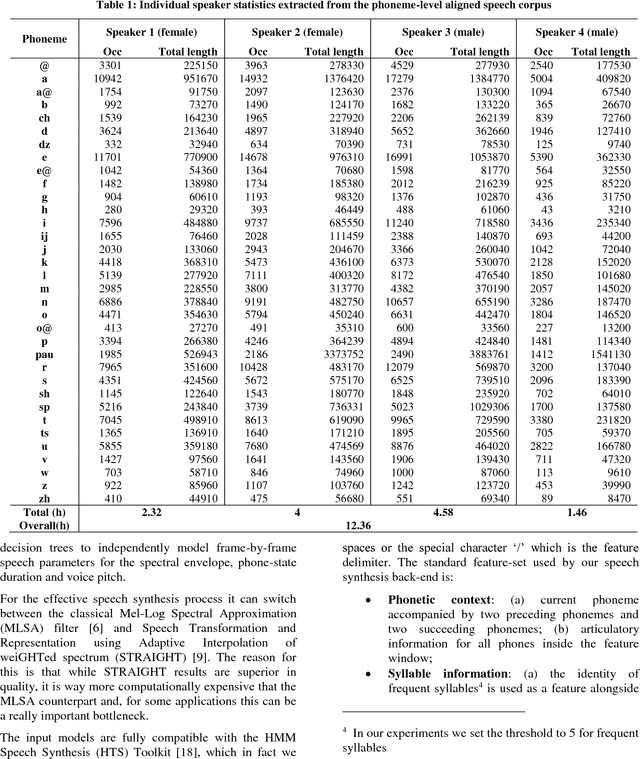
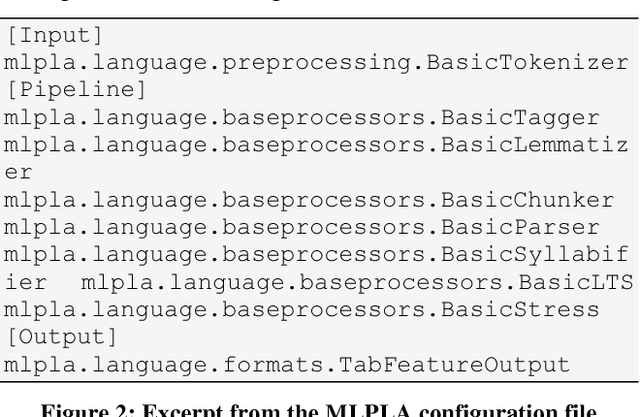
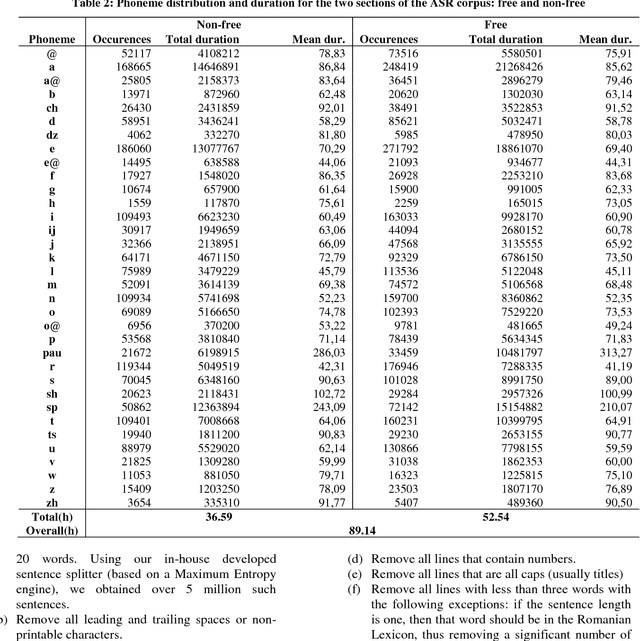
In this paper we introduce a set of resources and tools aimed at providing support for natural language processing, text-to-speech synthesis and speech recognition for Romanian. While the tools are general purpose and can be used for any language (we successfully trained our system for more than 50 languages and participated in the Universal Dependencies Shared Task), the resources are only relevant for Romanian language processing.