 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLookaheadKV: Fast and Accurate KV Cache Eviction by Glimpsing into the Future without Generation
Mar 11, 2026Transformer-based large language models (LLMs) rely on key-value (KV) caching to avoid redundant computation during autoregressive inference. While this mechanism greatly improves efficiency, the cache size grows linearly with the input sequence length, quickly becoming a bottleneck for long-context tasks. Existing solutions mitigate this problem by evicting prompt KV that are deemed unimportant, guided by estimated importance scores. Notably, a recent line of work proposes to improve eviction quality by "glimpsing into the future", in which a draft generator produces a surrogate future response approximating the target model's true response, and this surrogate is subsequently used to estimate the importance of cached KV more accurately. However, these approaches rely on computationally expensive draft generation, which introduces substantial prefilling overhead and limits their practicality in real-world deployment. To address this challenge, we propose LookaheadKV, a lightweight eviction framework that leverages the strength of surrogate future response without requiring explicit draft generation. LookaheadKV augments transformer layers with parameter-efficient modules trained to predict true importance scores with high accuracy. Our design ensures negligible runtime overhead comparable to existing inexpensive heuristics, while achieving accuracy superior to more costly approximation methods. Extensive experiments on long-context understanding benchmarks, across a wide range of models, demonstrate that our method not only outperforms recent competitive baselines in various long-context understanding tasks, but also reduces the eviction cost by up to 14.5x, leading to significantly faster time-to-first-token. Our code is available at https://github.com/SamsungLabs/LookaheadKV.
On the Importance of a Multi-Scale Calibration for Quantization
Feb 07, 2026Post-training quantization (PTQ) is a cornerstone for efficiently deploying large language models (LLMs), where a small calibration set critically affects quantization performance. However, conventional practices rely on random sequences of fixed length, overlooking the variable-length nature of LLM inputs. Input length directly influences the activation distribution and, consequently, the weight importance captured by the Hessian, which in turn affects quantization outcomes. As a result, Hessian estimates derived from fixed-length calibration may fail to represent the true importance of weights across diverse input scenarios. We propose MaCa (Matryoshka Calibration), a simple yet effective method for length-aware Hessian construction. MaCa (i) incorporates multi-scale sequence length information into Hessian estimation and (ii) regularizes each sequence as an independent sample, yielding a more stable and fruitful Hessian for accurate quantization. Experiments on state-of-the-art LLMs (e.g., Qwen3, Gemma3, LLaMA3) demonstrate that MaCa consistently improves accuracy under low bit quantization, offering a lightweight enhancement compatible with existing PTQ frameworks. To the best of our knowledge, this is the first work to systematically highlight the role of multi-scale calibration in LLM quantization.
Beyond Fact Verification: Comparing and Contrasting Claims on Contentious Topics
May 24, 2022
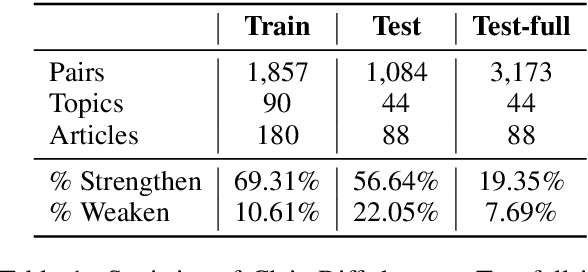
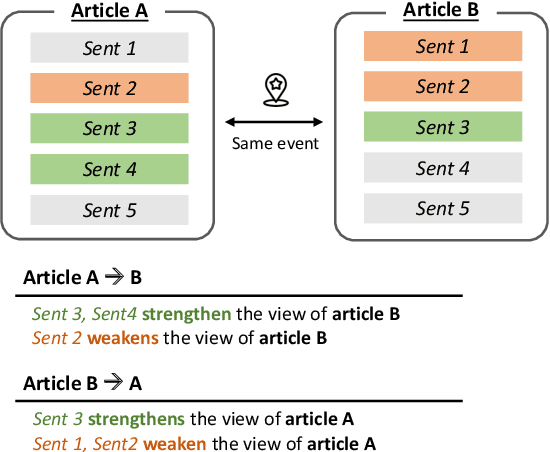
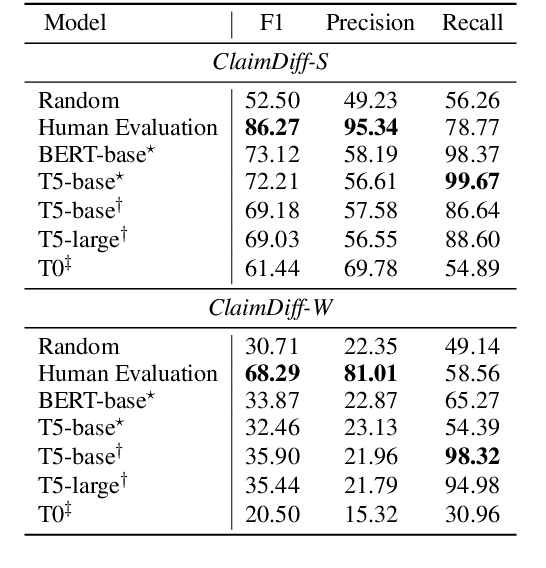
As the importance of identifying misinformation is increasing, many researchers focus on verifying textual claims on the web. One of the most popular tasks to achieve this is fact verification, which retrieves an evidence sentence from a large knowledge source such as Wikipedia to either verify or refute each factual claim. However, while such problem formulation is helpful for detecting false claims and fake news, it is not applicable to catching subtle differences in factually consistent claims which still might implicitly bias the readers, especially in contentious topics such as political, gender, or racial issues. In this study, we propose ClaimDiff, a novel dataset to compare the nuance between claim pairs in both a discriminative and a generative manner, with the underlying assumption that one is not necessarily more true than the other. This differs from existing fact verification datasets that verify the target sentence with respect to an absolute truth. We hope this task assists people in making more informed decisions among various sources of media.