 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTell Me What You Know About Sexism: Expert-LLM Interaction Strategies and Co-Created Definitions for Zero-Shot Sexism Detection
Apr 21, 2025



This paper investigates hybrid intelligence and collaboration between researchers of sexism and Large Language Models (LLMs), with a four-component pipeline. First, nine sexism researchers answer questions about their knowledge of sexism and of LLMs. They then participate in two interactive experiments involving an LLM (GPT3.5). The first experiment has experts assessing the model's knowledge about sexism and suitability for use in research. The second experiment tasks them with creating three different definitions of sexism: an expert-written definition, an LLM-written one, and a co-created definition. Lastly, zero-shot classification experiments use the three definitions from each expert in a prompt template for sexism detection, evaluating GPT4o on 2.500 texts sampled from five sexism benchmarks. We then analyze the resulting 67.500 classification decisions. The LLM interactions lead to longer and more complex definitions of sexism. Expert-written definitions on average perform poorly compared to LLM-generated definitions. However, some experts do improve classification performance with their co-created definitions of sexism, also experts who are inexperienced in using LLMs.
Only a Little to the Left: A Theory-grounded Measure of Political Bias in Large Language Models
Mar 20, 2025Prompt-based language models like GPT4 and LLaMa have been used for a wide variety of use cases such as simulating agents, searching for information, or for content analysis. For all of these applications and others, political biases in these models can affect their performance. Several researchers have attempted to study political bias in language models using evaluation suites based on surveys, such as the Political Compass Test (PCT), often finding a particular leaning favored by these models. However, there is some variation in the exact prompting techniques, leading to diverging findings and most research relies on constrained-answer settings to extract model responses. Moreover, the Political Compass Test is not a scientifically valid survey instrument. In this work, we contribute a political bias measured informed by political science theory, building on survey design principles to test a wide variety of input prompts, while taking into account prompt sensitivity. We then prompt 11 different open and commercial models, differentiating between instruction-tuned and non-instruction-tuned models, and automatically classify their political stances from 88,110 responses. Leveraging this dataset, we compute political bias profiles across different prompt variations and find that while PCT exaggerates bias in certain models like GPT3.5, measures of political bias are often unstable, but generally more left-leaning for instruction-tuned models.
Sensitive Content Classification in Social Media: A Holistic Resource and Evaluation
Nov 29, 2024



The detection of sensitive content in large datasets is crucial for ensuring that shared and analysed data is free from harmful material. However, current moderation tools, such as external APIs, suffer from limitations in customisation, accuracy across diverse sensitive categories, and privacy concerns. Additionally, existing datasets and open-source models focus predominantly on toxic language, leaving gaps in detecting other sensitive categories such as substance abuse or self-harm. In this paper, we put forward a unified dataset tailored for social media content moderation across six sensitive categories: conflictual language, profanity, sexually explicit material, drug-related content, self-harm, and spam. By collecting and annotating data with consistent retrieval strategies and guidelines, we address the shortcomings of previous focalised research. Our analysis demonstrates that fine-tuning large language models (LLMs) on this novel dataset yields significant improvements in detection performance compared to open off-the-shelf models such as LLaMA, and even proprietary OpenAI models, which underperform by 10-15% overall. This limitation is even more pronounced on popular moderation APIs, which cannot be easily tailored to specific sensitive content categories, among others.
Robustness and Confounders in the Demographic Alignment of LLMs with Human Perceptions of Offensiveness
Nov 13, 2024



Large language models (LLMs) are known to exhibit demographic biases, yet few studies systematically evaluate these biases across multiple datasets or account for confounding factors. In this work, we examine LLM alignment with human annotations in five offensive language datasets, comprising approximately 220K annotations. Our findings reveal that while demographic traits, particularly race, influence alignment, these effects are inconsistent across datasets and often entangled with other factors. Confounders -- such as document difficulty, annotator sensitivity, and within-group agreement -- account for more variation in alignment patterns than demographic traits alone. Specifically, alignment increases with higher annotator sensitivity and group agreement, while greater document difficulty corresponds to reduced alignment. Our results underscore the importance of multi-dataset analyses and confounder-aware methodologies in developing robust measures of demographic bias in LLMs.
From Measurement Instruments to Data: Leveraging Theory-Driven Synthetic Training Data for Classifying Social Constructs
Oct 17, 2024



Computational text classification is a challenging task, especially for multi-dimensional social constructs. Recently, there has been increasing discussion that synthetic training data could enhance classification by offering examples of how these constructs are represented in texts. In this paper, we systematically examine the potential of theory-driven synthetic training data for improving the measurement of social constructs. In particular, we explore how researchers can transfer established knowledge from measurement instruments in the social sciences, such as survey scales or annotation codebooks, into theory-driven generation of synthetic data. Using two studies on measuring sexism and political topics, we assess the added value of synthetic training data for fine-tuning text classification models. Although the results of the sexism study were less promising, our findings demonstrate that synthetic data can be highly effective in reducing the need for labeled data in political topic classification. With only a minimal drop in performance, synthetic data allows for substituting large amounts of labeled data. Furthermore, theory-driven synthetic data performed markedly better than data generated without conceptual information in mind.
An Open Multilingual System for Scoring Readability of Wikipedia
Jun 03, 2024



With over 60M articles, Wikipedia has become the largest platform for open and freely accessible knowledge. While it has more than 15B monthly visits, its content is believed to be inaccessible to many readers due to the lack of readability of its text. However, previous investigations of the readability of Wikipedia have been restricted to English only, and there are currently no systems supporting the automatic readability assessment of the 300+ languages in Wikipedia. To bridge this gap, we develop a multilingual model to score the readability of Wikipedia articles. To train and evaluate this model, we create a novel multilingual dataset spanning 14 languages, by matching articles from Wikipedia to simplified Wikipedia and online children encyclopedias. We show that our model performs well in a zero-shot scenario, yielding a ranking accuracy of more than 80% across 14 languages and improving upon previous benchmarks. These results demonstrate the applicability of the model at scale for languages in which there is no ground-truth data available for model fine-tuning. Furthermore, we provide the first overview on the state of readability in Wikipedia beyond English.
The Unseen Targets of Hate -- A Systematic Review of Hateful Communication Datasets
May 14, 2024Machine learning (ML)-based content moderation tools are essential to keep online spaces free from hateful communication. Yet, ML tools can only be as capable as the quality of the data they are trained on allows them. While there is increasing evidence that they underperform in detecting hateful communications directed towards specific identities and may discriminate against them, we know surprisingly little about the provenance of such bias. To fill this gap, we present a systematic review of the datasets for the automated detection of hateful communication introduced over the past decade, and unpack the quality of the datasets in terms of the identities that they embody: those of the targets of hateful communication that the data curators focused on, as well as those unintentionally included in the datasets. We find, overall, a skewed representation of selected target identities and mismatches between the targets that research conceptualizes and ultimately includes in datasets. Yet, by contextualizing these findings in the language and location of origin of the datasets, we highlight a positive trend towards the broadening and diversification of this research space.
People Make Better Edits: Measuring the Efficacy of LLM-Generated Counterfactually Augmented Data for Harmful Language Detection
Nov 02, 2023



NLP models are used in a variety of critical social computing tasks, such as detecting sexist, racist, or otherwise hateful content. Therefore, it is imperative that these models are robust to spurious features. Past work has attempted to tackle such spurious features using training data augmentation, including Counterfactually Augmented Data (CADs). CADs introduce minimal changes to existing training data points and flip their labels; training on them may reduce model dependency on spurious features. However, manually generating CADs can be time-consuming and expensive. Hence in this work, we assess if this task can be automated using generative NLP models. We automatically generate CADs using Polyjuice, ChatGPT, and Flan-T5, and evaluate their usefulness in improving model robustness compared to manually-generated CADs. By testing both model performance on multiple out-of-domain test sets and individual data point efficacy, our results show that while manual CADs are still the most effective, CADs generated by ChatGPT come a close second. One key reason for the lower performance of automated methods is that the changes they introduce are often insufficient to flip the original label.
Counterfactually Augmented Data and Unintended Bias: The Case of Sexism and Hate Speech Detection
May 09, 2022
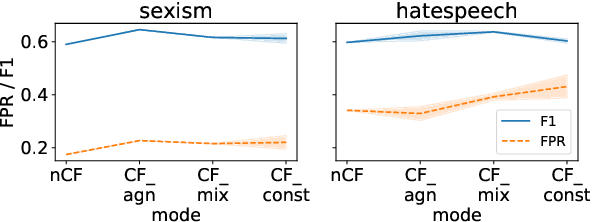
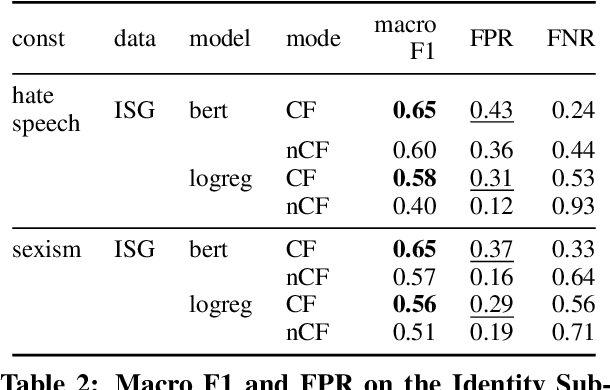
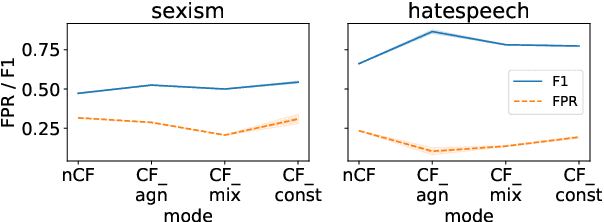
Counterfactually Augmented Data (CAD) aims to improve out-of-domain generalizability, an indicator of model robustness. The improvement is credited with promoting core features of the construct over spurious artifacts that happen to correlate with it. Yet, over-relying on core features may lead to unintended model bias. Especially, construct-driven CAD -- perturbations of core features -- may induce models to ignore the context in which core features are used. Here, we test models for sexism and hate speech detection on challenging data: non-hateful and non-sexist usage of identity and gendered terms. In these hard cases, models trained on CAD, especially construct-driven CAD, show higher false-positive rates than models trained on the original, unperturbed data. Using a diverse set of CAD -- construct-driven and construct-agnostic -- reduces such unintended bias.
"Unsex me here": Revisiting Sexism Detection Using Psychological Scales and Adversarial Samples
Apr 27, 2020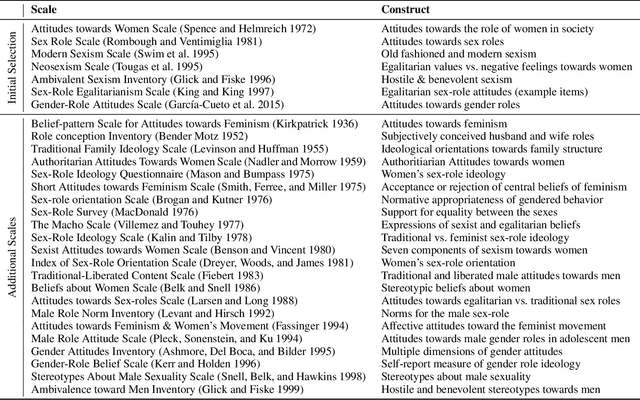
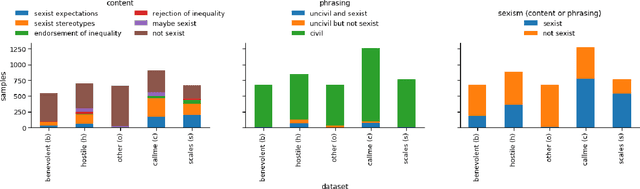

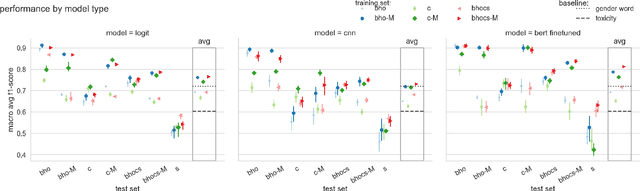
To effectively tackle sexism online, research has focused on automated methods for detecting sexism. In this paper, we use items from psychological scales and adversarial sample generation to 1) provide a codebook for different types of sexism in theory-driven scales and in social media text; 2) test the performance of different sexism detection methods across multiple data sets; 3) provide an overview of strategies employed by humans to remove sexism through minimal changes. Results highlight that current methods seem inadequate in detecting all but the most blatant forms of sexism and do not generalize well to out-of-domain examples. By providing a scale-based codebook for sexism and insights into what makes a statement sexist, we hope to contribute to the development of better and broader models for sexism detection, including reflections on theory-driven approaches to data collection.