 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Emotion to Expression: Theoretical Foundations and Resources for Fear Speech
Jan 23, 2026Few forces rival fear in their ability to mobilize societies, distort communication, and reshape collective behavior. In computational linguistics, fear is primarily studied as an emotion, but not as a distinct form of speech. Fear speech content is widespread and growing, and often outperforms hate-speech content in reach and engagement because it appears "civiler" and evades moderation. Yet the computational study of fear speech remains fragmented and under-resourced. This can be understood by recognizing that fear speech is a phenomenon shaped by contributions from multiple disciplines. In this paper, we bridge cross-disciplinary perspectives by comparing theories of fear from Psychology, Political science, Communication science, and Linguistics. Building on this, we review existing definitions. We follow up with a survey of datasets from related research areas and propose a taxonomy that consolidates different dimensions of fear for studying fear speech. By reviewing current datasets and defining core concepts, our work offers both theoretical and practical guidance for creating datasets and advancing fear speech research.
Sexism Detection on a Data Diet
Jun 07, 2024



There is an increase in the proliferation of online hate commensurate with the rise in the usage of social media. In response, there is also a significant advancement in the creation of automated tools aimed at identifying harmful text content using approaches grounded in Natural Language Processing and Deep Learning. Although it is known that training Deep Learning models require a substantial amount of annotated data, recent line of work suggests that models trained on specific subsets of the data still retain performance comparable to the model that was trained on the full dataset. In this work, we show how we can leverage influence scores to estimate the importance of a data point while training a model and designing a pruning strategy applied to the case of sexism detection. We evaluate the model performance trained on data pruned with different pruning strategies on three out-of-domain datasets and find, that in accordance with other work a large fraction of instances can be removed without significant performance drop. However, we also discover that the strategies for pruning data, previously successful in Natural Language Inference tasks, do not readily apply to the detection of harmful content and instead amplify the already prevalent class imbalance even more, leading in the worst-case to a complete absence of the hateful class.
The Unseen Targets of Hate -- A Systematic Review of Hateful Communication Datasets
May 14, 2024Machine learning (ML)-based content moderation tools are essential to keep online spaces free from hateful communication. Yet, ML tools can only be as capable as the quality of the data they are trained on allows them. While there is increasing evidence that they underperform in detecting hateful communications directed towards specific identities and may discriminate against them, we know surprisingly little about the provenance of such bias. To fill this gap, we present a systematic review of the datasets for the automated detection of hateful communication introduced over the past decade, and unpack the quality of the datasets in terms of the identities that they embody: those of the targets of hateful communication that the data curators focused on, as well as those unintentionally included in the datasets. We find, overall, a skewed representation of selected target identities and mismatches between the targets that research conceptualizes and ultimately includes in datasets. Yet, by contextualizing these findings in the language and location of origin of the datasets, we highlight a positive trend towards the broadening and diversification of this research space.
ValiTex -- a unified validation framework for computational text-based measures of social science constructs
Jul 10, 2023



Guidance on how to validate computational text-based measures of social science constructs is fragmented. Whereas scholars are generally acknowledging the importance of validating their text-based measures, they often lack common terminology and a unified framework to do so. This paper introduces a new validation framework called ValiTex, designed to assist scholars to measure social science constructs based on textual data. The framework draws on a long-established tradition within psychometrics while extending the framework for the purpose of computational text analysis. ValiTex consists of two components, a conceptual model, and a dynamic checklist. Whereas the conceptual model provides a general structure along distinct phases on how to approach validation, the dynamic checklist defines specific validation steps and provides guidance on which steps might be considered recommendable (i.e., providing relevant and necessary validation evidence) or optional (i.e., useful for providing additional supporting validation evidence. The utility of the framework is demonstrated by applying it to a use case of detecting sexism from social media data.
Counterfactually Augmented Data and Unintended Bias: The Case of Sexism and Hate Speech Detection
May 09, 2022
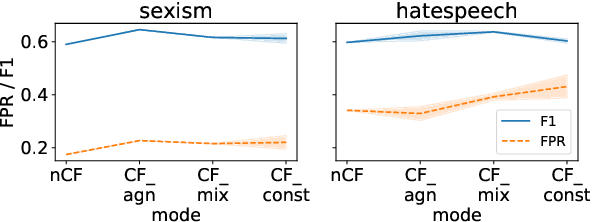
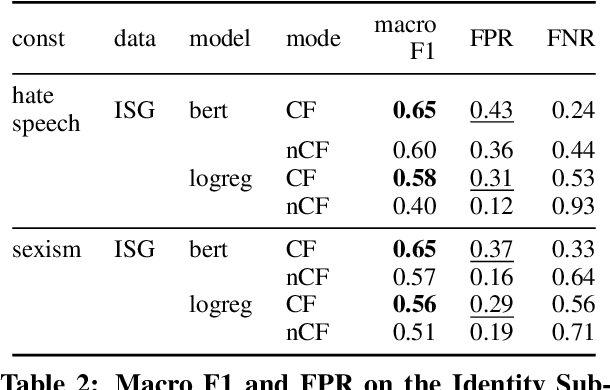
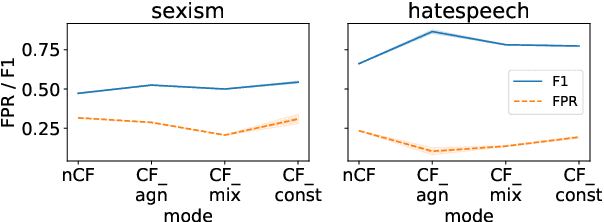
Counterfactually Augmented Data (CAD) aims to improve out-of-domain generalizability, an indicator of model robustness. The improvement is credited with promoting core features of the construct over spurious artifacts that happen to correlate with it. Yet, over-relying on core features may lead to unintended model bias. Especially, construct-driven CAD -- perturbations of core features -- may induce models to ignore the context in which core features are used. Here, we test models for sexism and hate speech detection on challenging data: non-hateful and non-sexist usage of identity and gendered terms. In these hard cases, models trained on CAD, especially construct-driven CAD, show higher false-positive rates than models trained on the original, unperturbed data. Using a diverse set of CAD -- construct-driven and construct-agnostic -- reduces such unintended bias.
The FairCeptron: A Framework for Measuring Human Perceptions of Algorithmic Fairness
Feb 08, 2021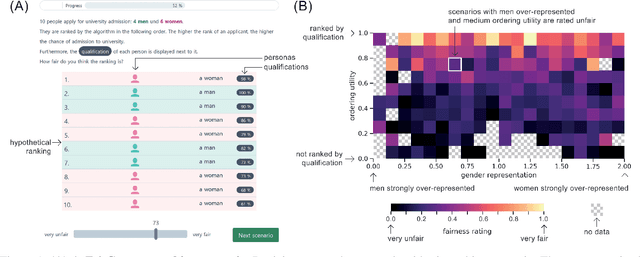
Measures of algorithmic fairness often do not account for human perceptions of fairness that can substantially vary between different sociodemographics and stakeholders. The FairCeptron framework is an approach for studying perceptions of fairness in algorithmic decision making such as in ranking or classification. It supports (i) studying human perceptions of fairness and (ii) comparing these human perceptions with measures of algorithmic fairness. The framework includes fairness scenario generation, fairness perception elicitation and fairness perception analysis. We demonstrate the FairCeptron framework by applying it to a hypothetical university admission context where we collect human perceptions of fairness in the presence of minorities. An implementation of the FairCeptron framework is openly available, and it can easily be adapted to study perceptions of algorithmic fairness in other application contexts. We hope our work paves the way towards elevating the role of studies of human fairness perceptions in the process of designing algorithmic decision making systems.
"Unsex me here": Revisiting Sexism Detection Using Psychological Scales and Adversarial Samples
Apr 27, 2020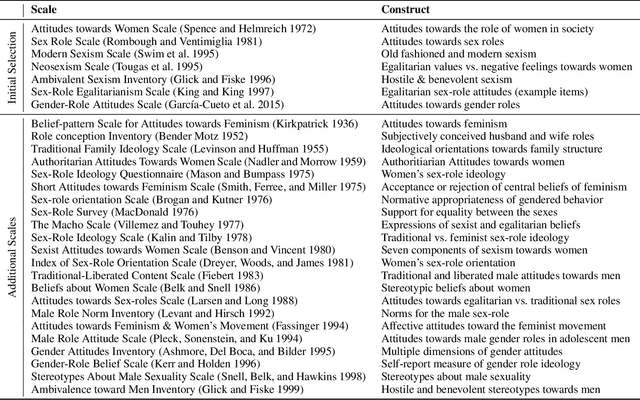
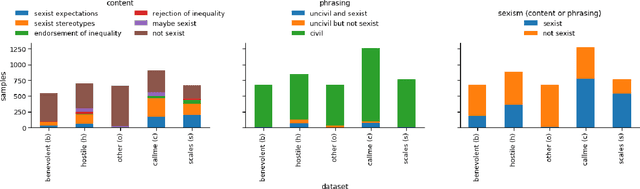

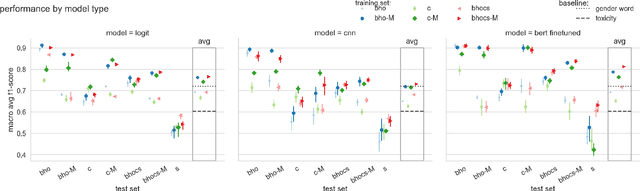
To effectively tackle sexism online, research has focused on automated methods for detecting sexism. In this paper, we use items from psychological scales and adversarial sample generation to 1) provide a codebook for different types of sexism in theory-driven scales and in social media text; 2) test the performance of different sexism detection methods across multiple data sets; 3) provide an overview of strategies employed by humans to remove sexism through minimal changes. Results highlight that current methods seem inadequate in detecting all but the most blatant forms of sexism and do not generalize well to out-of-domain examples. By providing a scale-based codebook for sexism and insights into what makes a statement sexist, we hope to contribute to the development of better and broader models for sexism detection, including reflections on theory-driven approaches to data collection.
Responsible team players wanted: an analysis of soft skill requirements in job advertisements
Oct 13, 2018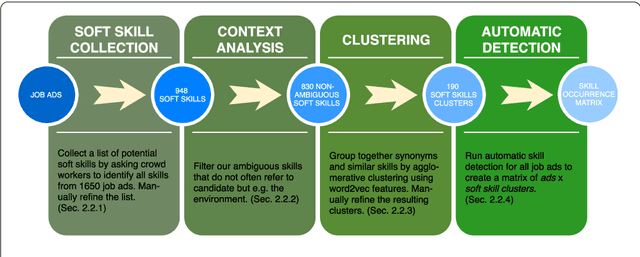
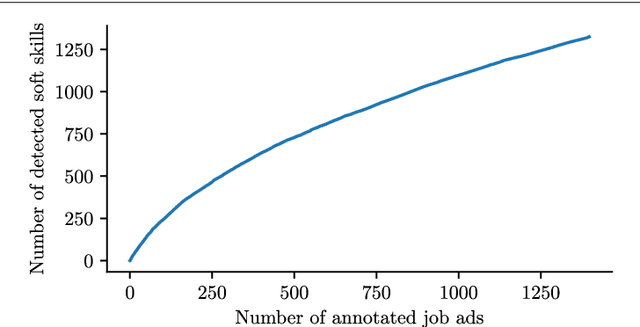
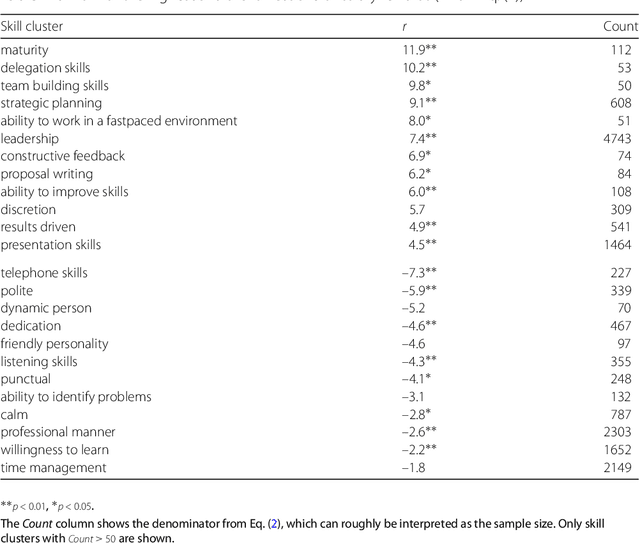
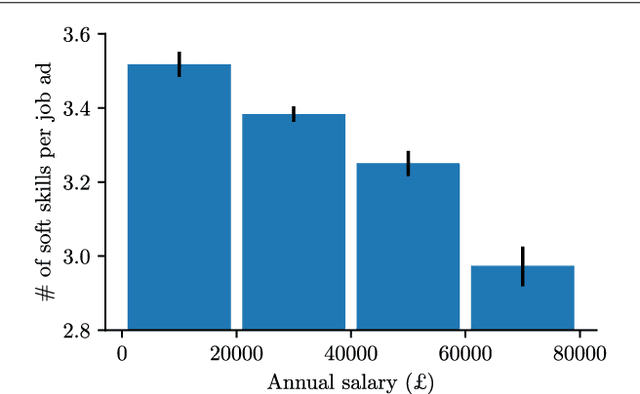
During the past decades the importance of soft skills for labour market outcomes has grown substantially. This carries implications for labour market inequality, since previous research shows that soft skills are not valued equally across race and gender. This work explores the role of soft skills in job advertisements by drawing on methods from computational science as well as on theoretical and empirical insights from economics, sociology and psychology. We present a semi-automatic approach based on crowdsourcing and text mining for extracting a list of soft skills. We find that soft skills are a crucial component of job ads, especially of low-paid jobs and jobs in female-dominated professions.Our work shows that soft skills can serve as partial predictors of the gender composition in job categories and that not all soft skills receive equal wage returns at the labour market. Especially "female" skills are associated with wage penalties. Our results expand the growing literature on soft skills and highlight the importance of soft skills for occupational gender segregation at labour markets.