 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Root Models: Beyond Pairwise Graphical Models for Univariate Exponential Families
Jun 02, 2016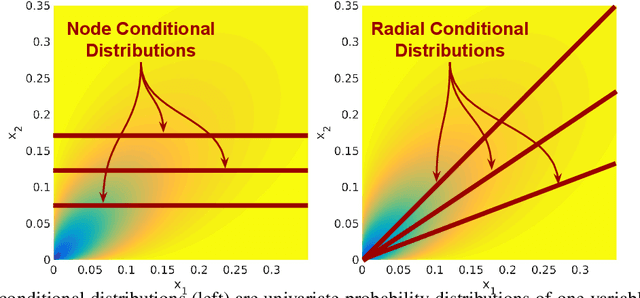
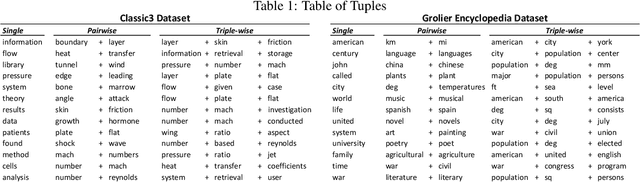
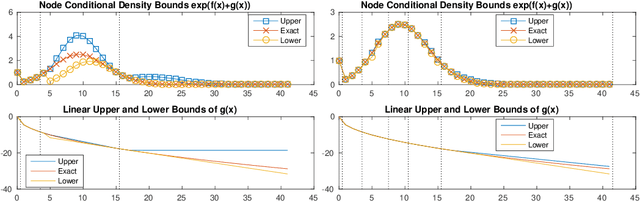
We present a novel k-way high-dimensional graphical model called the Generalized Root Model (GRM) that explicitly models dependencies between variable sets of size k > 2---where k = 2 is the standard pairwise graphical model. This model is based on taking the k-th root of the original sufficient statistics of any univariate exponential family with positive sufficient statistics, including the Poisson and exponential distributions. As in the recent work with square root graphical (SQR) models [Inouye et al. 2016]---which was restricted to pairwise dependencies---we give the conditions of the parameters that are needed for normalization using the radial conditionals similar to the pairwise case [Inouye et al. 2016]. In particular, we show that the Poisson GRM has no restrictions on the parameters and the exponential GRM only has a restriction akin to negative definiteness. We develop a simple but general learning algorithm based on L1-regularized node-wise regressions. We also present a general way of numerically approximating the log partition function and associated derivatives of the GRM univariate node conditionals---in contrast to [Inouye et al. 2016], which only provided algorithm for estimating the exponential SQR. To illustrate GRM, we model word counts with a Poisson GRM and show the associated k-sized variable sets. We finish by discussing methods for reducing the parameter space in various situations.
High-dimensional Time Series Prediction with Missing Values
Feb 17, 2016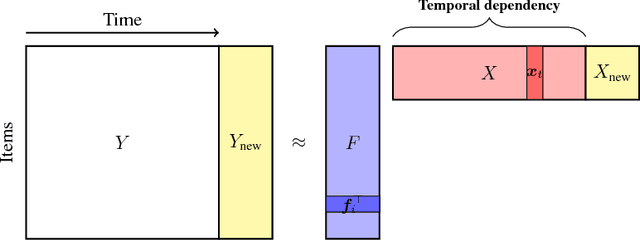
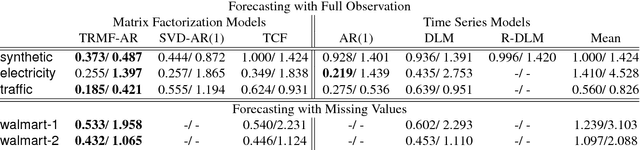
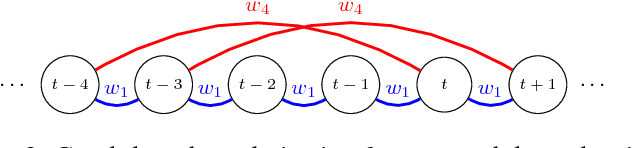
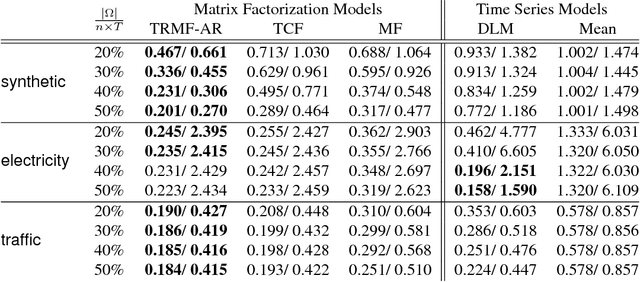
High-dimensional time series prediction is needed in applications as diverse as demand forecasting and climatology. Often, such applications require methods that are both highly scalable, and deal with noisy data in terms of corruptions or missing values. Classical time series methods usually fall short of handling both these issues. In this paper, we propose to adapt matrix matrix completion approaches that have previously been successfully applied to large scale noisy data, but which fail to adequately model high-dimensional time series due to temporal dependencies. We present a novel temporal regularized matrix factorization (TRMF) framework which supports data-driven temporal dependency learning and enables forecasting ability to our new matrix factorization approach. TRMF is highly general, and subsumes many existing matrix factorization approaches for time series data. We make interesting connections to graph regularized matrix factorization methods in the context of learning the dependencies. Experiments on both real and synthetic data show that TRMF outperforms several existing approaches for common time series tasks.
Fast Multiplier Methods to Optimize Non-exhaustive, Overlapping Clustering
Feb 05, 2016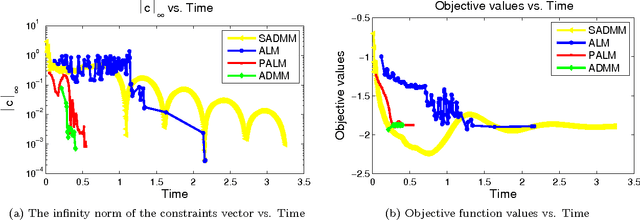
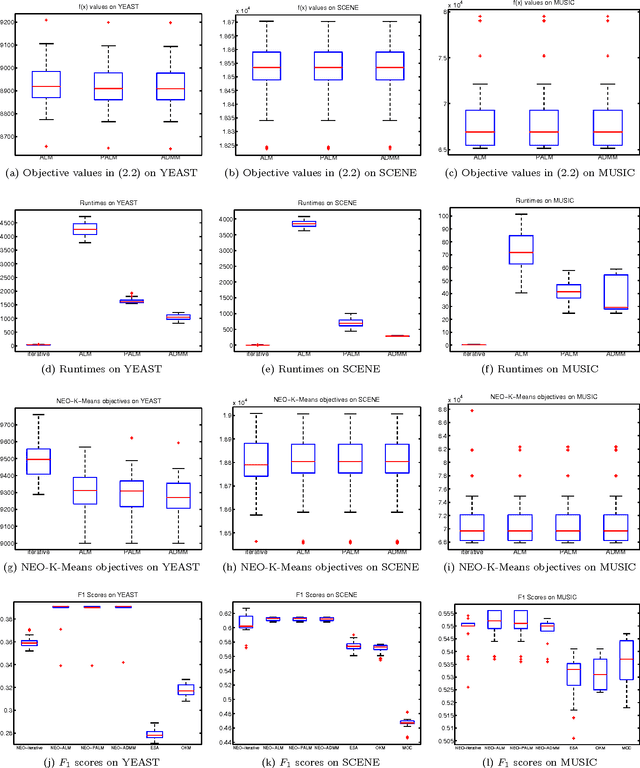
Clustering is one of the most fundamental and important tasks in data mining. Traditional clustering algorithms, such as K-means, assign every data point to exactly one cluster. However, in real-world datasets, the clusters may overlap with each other. Furthermore, often, there are outliers that should not belong to any cluster. We recently proposed the NEO-K-Means (Non-Exhaustive, Overlapping K-Means) objective as a way to address both issues in an integrated fashion. Optimizing this discrete objective is NP-hard, and even though there is a convex relaxation of the objective, straightforward convex optimization approaches are too expensive for large datasets. A practical alternative is to use a low-rank factorization of the solution matrix in the convex formulation. The resulting optimization problem is non-convex, and we can locally optimize the objective function using an augmented Lagrangian method. In this paper, we consider two fast multiplier methods to accelerate the convergence of an augmented Lagrangian scheme: a proximal method of multipliers and an alternating direction method of multipliers (ADMM). For the proximal augmented Lagrangian or proximal method of multipliers, we show a convergence result for the non-convex case with bound-constrained subproblems. These methods are up to 13 times faster---with no change in quality---compared with a standard augmented Lagrangian method on problems with over 10,000 variables and bring runtimes down from over an hour to around 5 minutes.
Preference Completion: Large-scale Collaborative Ranking from Pairwise Comparisons
Jul 16, 2015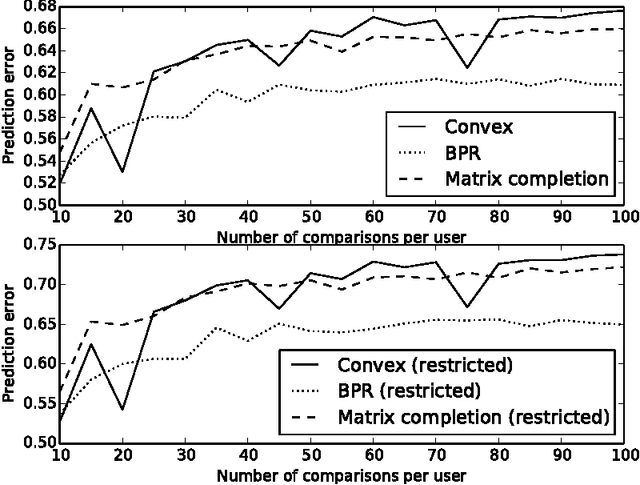

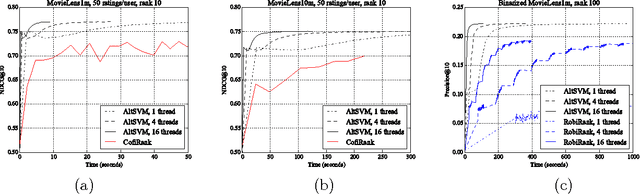
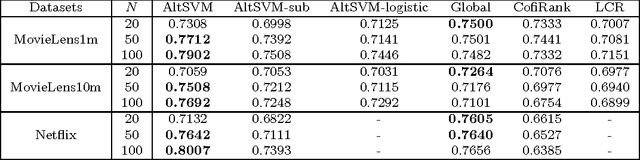
In this paper we consider the collaborative ranking setting: a pool of users each provides a small number of pairwise preferences between $d$ possible items; from these we need to predict preferences of the users for items they have not yet seen. We do so by fitting a rank $r$ score matrix to the pairwise data, and provide two main contributions: (a) we show that an algorithm based on convex optimization provides good generalization guarantees once each user provides as few as $O(r\log^2 d)$ pairwise comparisons -- essentially matching the sample complexity required in the related matrix completion setting (which uses actual numerical as opposed to pairwise information), and (b) we develop a large-scale non-convex implementation, which we call AltSVM, that trains a factored form of the matrix via alternating minimization (which we show reduces to alternating SVM problems), and scales and parallelizes very well to large problem settings. It also outperforms common baselines on many moderately large popular collaborative filtering datasets in both NDCG and in other measures of ranking performance.
Optimal Decision-Theoretic Classification Using Non-Decomposable Performance Metrics
May 07, 2015
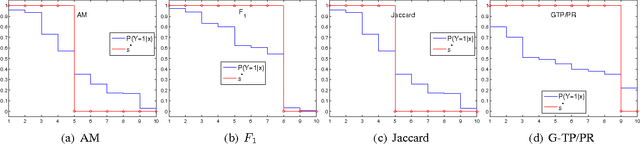
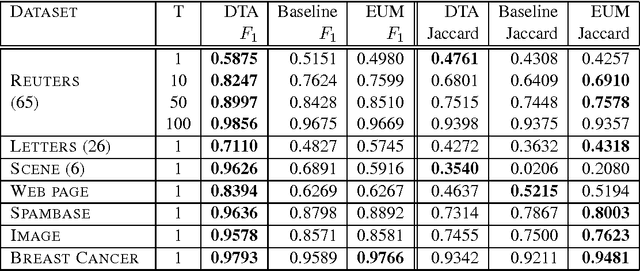
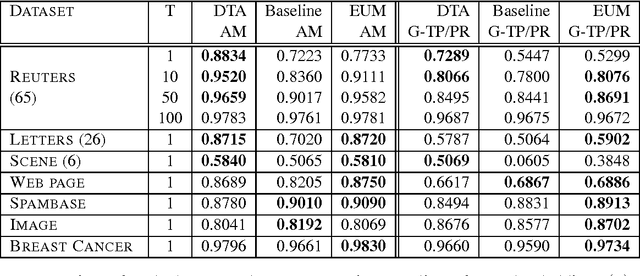
We provide a general theoretical analysis of expected out-of-sample utility, also referred to as decision-theoretic classification, for non-decomposable binary classification metrics such as F-measure and Jaccard coefficient. Our key result is that the expected out-of-sample utility for many performance metrics is provably optimized by a classifier which is equivalent to a signed thresholding of the conditional probability of the positive class. Our analysis bridges a gap in the literature on binary classification, revealed in light of recent results for non-decomposable metrics in population utility maximization style classification. Our results identify checkable properties of a performance metric which are sufficient to guarantee a probability ranking principle. We propose consistent estimators for optimal expected out-of-sample classification. As a consequence of the probability ranking principle, computational requirements can be reduced from exponential to cubic complexity in the general case, and further reduced to quadratic complexity in special cases. We provide empirical results on simulated and benchmark datasets evaluating the performance of the proposed algorithms for decision-theoretic classification and comparing them to baseline and state-of-the-art methods in population utility maximization for non-decomposable metrics.
PASSCoDe: Parallel ASynchronous Stochastic dual Co-ordinate Descent
Apr 06, 2015

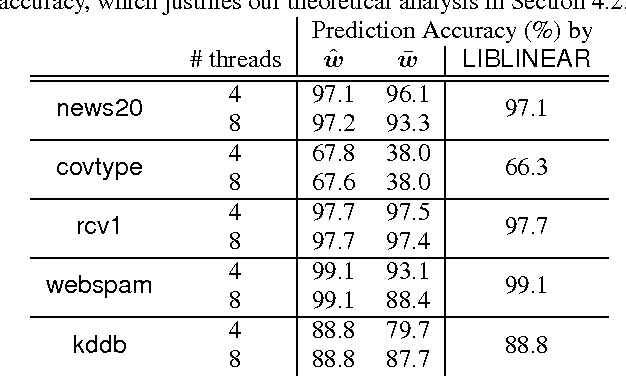
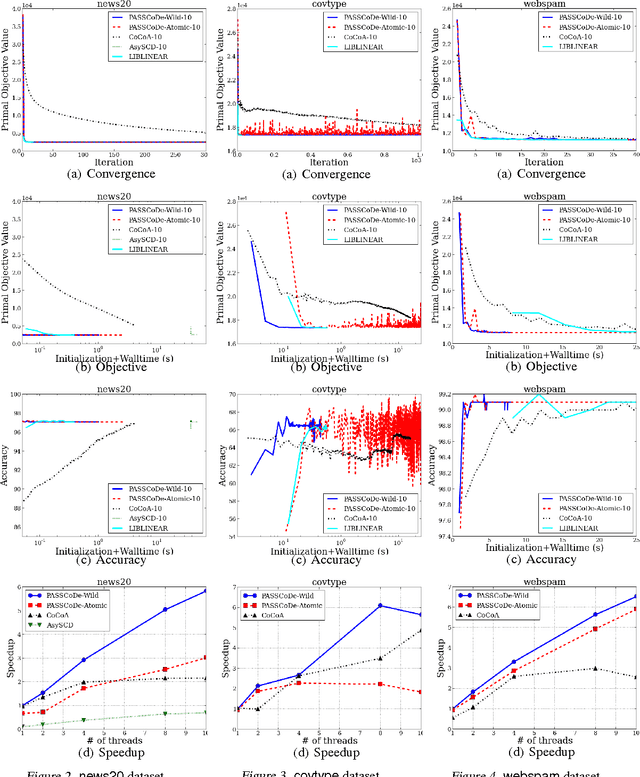
Stochastic Dual Coordinate Descent (SDCD) has become one of the most efficient ways to solve the family of $\ell_2$-regularized empirical risk minimization problems, including linear SVM, logistic regression, and many others. The vanilla implementation of DCD is quite slow; however, by maintaining primal variables while updating dual variables, the time complexity of SDCD can be significantly reduced. Such a strategy forms the core algorithm in the widely-used LIBLINEAR package. In this paper, we parallelize the SDCD algorithms in LIBLINEAR. In recent research, several synchronized parallel SDCD algorithms have been proposed, however, they fail to achieve good speedup in the shared memory multi-core setting. In this paper, we propose a family of asynchronous stochastic dual coordinate descent algorithms (ASDCD). Each thread repeatedly selects a random dual variable and conducts coordinate updates using the primal variables that are stored in the shared memory. We analyze the convergence properties when different locking/atomic mechanisms are applied. For implementation with atomic operations, we show linear convergence under mild conditions. For implementation without any atomic operations or locking, we present the first {\it backward error analysis} for ASDCD under the multi-core environment, showing that the converged solution is the exact solution for a primal problem with perturbed regularizer. Experimental results show that our methods are much faster than previous parallel coordinate descent solvers.
Proximal Quasi-Newton for Computationally Intensive L1-regularized M-estimators
Jan 23, 2015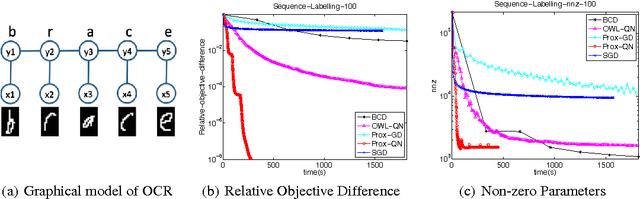
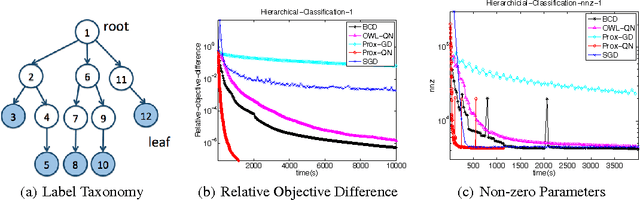
We consider the class of optimization problems arising from computationally intensive L1-regularized M-estimators, where the function or gradient values are very expensive to compute. A particular instance of interest is the L1-regularized MLE for learning Conditional Random Fields (CRFs), which are a popular class of statistical models for varied structured prediction problems such as sequence labeling, alignment, and classification with label taxonomy. L1-regularized MLEs for CRFs are particularly expensive to optimize since computing the gradient values requires an expensive inference step. In this work, we propose the use of a carefully constructed proximal quasi-Newton algorithm for such computationally intensive M-estimation problems, where we employ an aggressive active set selection technique. In a key contribution of the paper, we show that the proximal quasi-Newton method is provably super-linearly convergent, even in the absence of strong convexity, by leveraging a restricted variant of strong convexity. In our experiments, the proposed algorithm converges considerably faster than current state-of-the-art on the problems of sequence labeling and hierarchical classification.
A Scalable Asynchronous Distributed Algorithm for Topic Modeling
Dec 16, 2014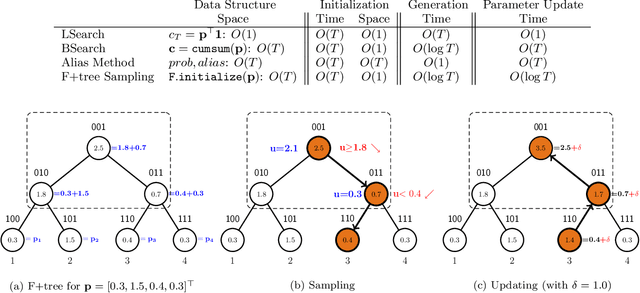


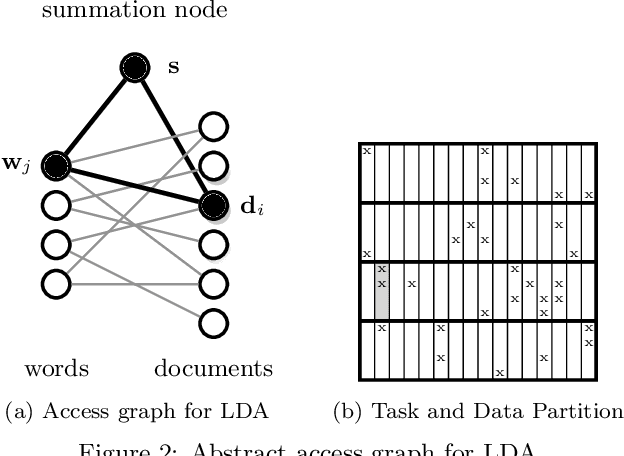
Learning meaningful topic models with massive document collections which contain millions of documents and billions of tokens is challenging because of two reasons: First, one needs to deal with a large number of topics (typically in the order of thousands). Second, one needs a scalable and efficient way of distributing the computation across multiple machines. In this paper we present a novel algorithm F+Nomad LDA which simultaneously tackles both these problems. In order to handle large number of topics we use an appropriately modified Fenwick tree. This data structure allows us to sample from a multinomial distribution over $T$ items in $O(\log T)$ time. Moreover, when topic counts change the data structure can be updated in $O(\log T)$ time. In order to distribute the computation across multiple processor we present a novel asynchronous framework inspired by the Nomad algorithm of \cite{YunYuHsietal13}. We show that F+Nomad LDA significantly outperform state-of-the-art on massive problems which involve millions of documents, billions of words, and thousands of topics.
PU Learning for Matrix Completion
Nov 22, 2014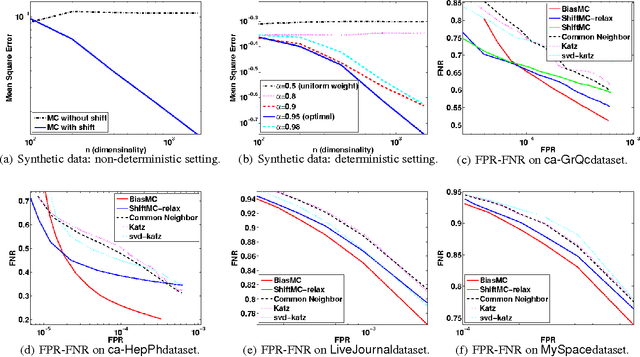

In this paper, we consider the matrix completion problem when the observations are one-bit measurements of some underlying matrix M, and in particular the observed samples consist only of ones and no zeros. This problem is motivated by modern applications such as recommender systems and social networks where only "likes" or "friendships" are observed. The problem of learning from only positive and unlabeled examples, called PU (positive-unlabeled) learning, has been studied in the context of binary classification. We consider the PU matrix completion problem, where an underlying real-valued matrix M is first quantized to generate one-bit observations and then a subset of positive entries is revealed. Under the assumption that M has bounded nuclear norm, we provide recovery guarantees for two different observation models: 1) M parameterizes a distribution that generates a binary matrix, 2) M is thresholded to obtain a binary matrix. For the first case, we propose a "shifted matrix completion" method that recovers M using only a subset of indices corresponding to ones, while for the second case, we propose a "biased matrix completion" method that recovers the (thresholded) binary matrix. Both methods yield strong error bounds --- if M is n by n, the Frobenius error is bounded as O(1/((1-rho)n), where 1-rho denotes the fraction of ones observed. This implies a sample complexity of O(n\log n) ones to achieve a small error, when M is dense and n is large. We extend our methods and guarantees to the inductive matrix completion problem, where rows and columns of M have associated features. We provide efficient and scalable optimization procedures for both the methods and demonstrate the effectiveness of the proposed methods for link prediction (on real-world networks consisting of over 2 million nodes and 90 million links) and semi-supervised clustering tasks.
Large-scale Multi-label Learning with Missing Labels
Nov 25, 2013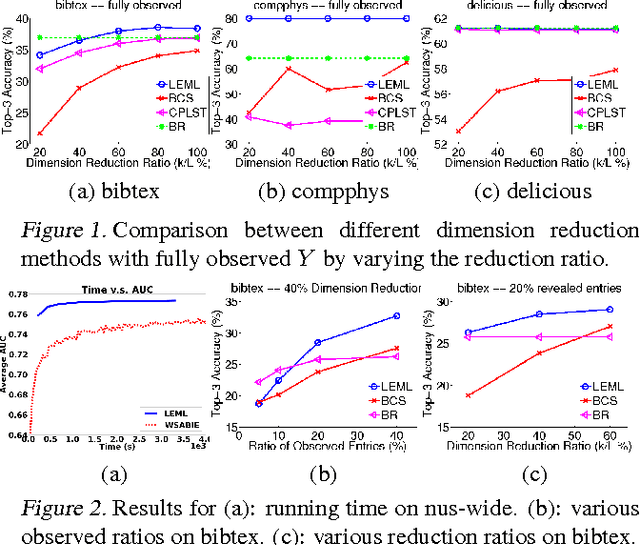
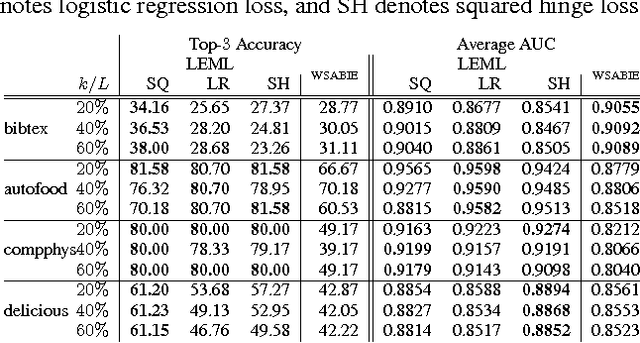
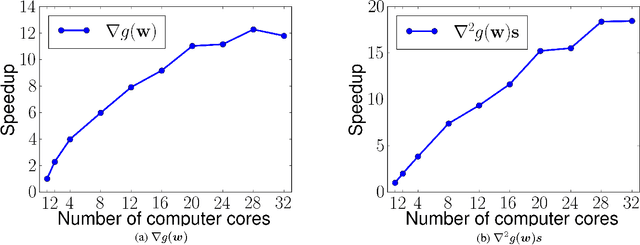
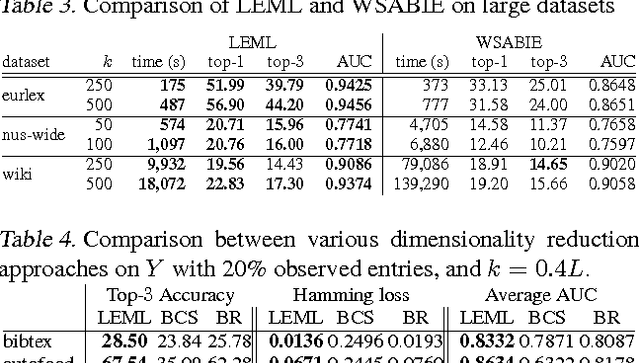
The multi-label classification problem has generated significant interest in recent years. However, existing approaches do not adequately address two key challenges: (a) the ability to tackle problems with a large number (say millions) of labels, and (b) the ability to handle data with missing labels. In this paper, we directly address both these problems by studying the multi-label problem in a generic empirical risk minimization (ERM) framework. Our framework, despite being simple, is surprisingly able to encompass several recent label-compression based methods which can be derived as special cases of our method. To optimize the ERM problem, we develop techniques that exploit the structure of specific loss functions - such as the squared loss function - to offer efficient algorithms. We further show that our learning framework admits formal excess risk bounds even in the presence of missing labels. Our risk bounds are tight and demonstrate better generalization performance for low-rank promoting trace-norm regularization when compared to (rank insensitive) Frobenius norm regularization. Finally, we present extensive empirical results on a variety of benchmark datasets and show that our methods perform significantly better than existing label compression based methods and can scale up to very large datasets such as the Wikipedia dataset.