 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinker: Training LLMs in Hierarchical Thinking for Deep Search via Multi-Turn Interaction
Nov 14, 2025



Efficient retrieval of external knowledge bases and web pages is crucial for enhancing the reasoning abilities of LLMs. Previous works on training LLMs to leverage external retrievers for solving complex problems have predominantly employed end-to-end reinforcement learning. However, these approaches neglect supervision over the reasoning process, making it difficult to guarantee logical coherence and rigor. To address these limitations, we propose Thinker, a hierarchical thinking model for deep search through multi-turn interaction, making the reasoning process supervisable and verifiable. It decomposes complex problems into independently solvable sub-problems, each dually represented in both natural language and an equivalent logical function to support knowledge base and web searches. Concurrently, dependencies between sub-problems are passed as parameters via these logical functions, enhancing the logical coherence of the problem-solving process. To avoid unnecessary external searches, we perform knowledge boundary determination to check if a sub-problem is within the LLM's intrinsic knowledge, allowing it to answer directly. Experimental results indicate that with as few as several hundred training samples, the performance of Thinker is competitive with established baselines. Furthermore, when scaled to the full training set, Thinker significantly outperforms these methods across various datasets and model sizes. The source code is available at https://github.com/OpenSPG/KAG-Thinker.
Fast Multiplier Methods to Optimize Non-exhaustive, Overlapping Clustering
Feb 05, 2016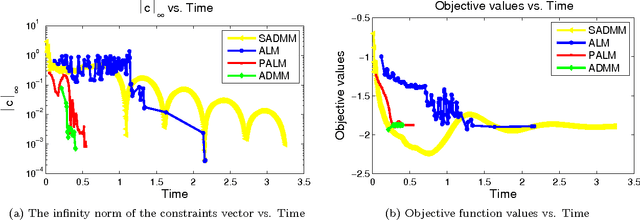
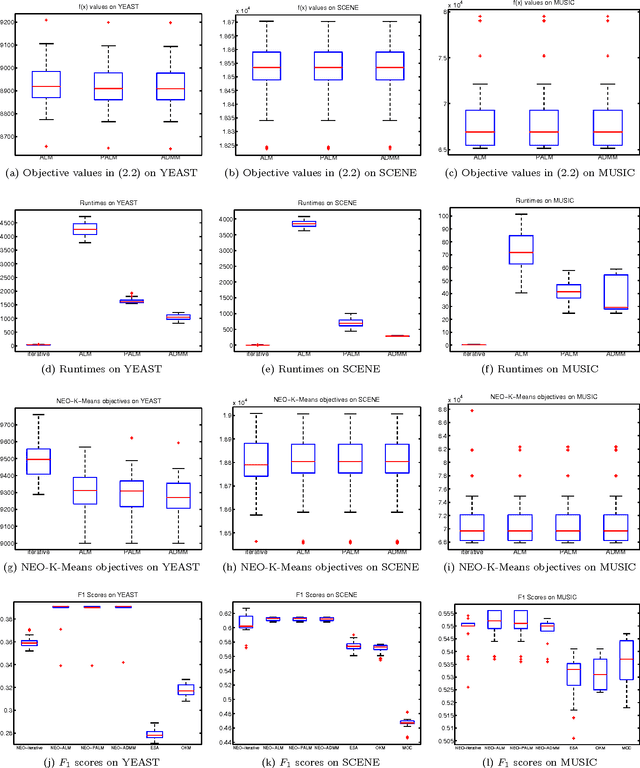
Clustering is one of the most fundamental and important tasks in data mining. Traditional clustering algorithms, such as K-means, assign every data point to exactly one cluster. However, in real-world datasets, the clusters may overlap with each other. Furthermore, often, there are outliers that should not belong to any cluster. We recently proposed the NEO-K-Means (Non-Exhaustive, Overlapping K-Means) objective as a way to address both issues in an integrated fashion. Optimizing this discrete objective is NP-hard, and even though there is a convex relaxation of the objective, straightforward convex optimization approaches are too expensive for large datasets. A practical alternative is to use a low-rank factorization of the solution matrix in the convex formulation. The resulting optimization problem is non-convex, and we can locally optimize the objective function using an augmented Lagrangian method. In this paper, we consider two fast multiplier methods to accelerate the convergence of an augmented Lagrangian scheme: a proximal method of multipliers and an alternating direction method of multipliers (ADMM). For the proximal augmented Lagrangian or proximal method of multipliers, we show a convergence result for the non-convex case with bound-constrained subproblems. These methods are up to 13 times faster---with no change in quality---compared with a standard augmented Lagrangian method on problems with over 10,000 variables and bring runtimes down from over an hour to around 5 minutes.