 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task Sequence to Sequence Learning
Mar 01, 2016
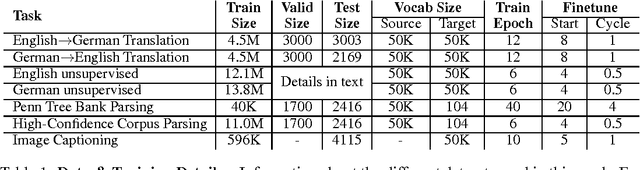
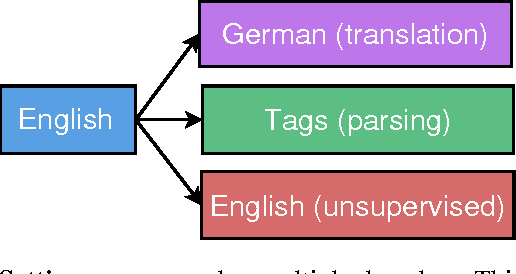
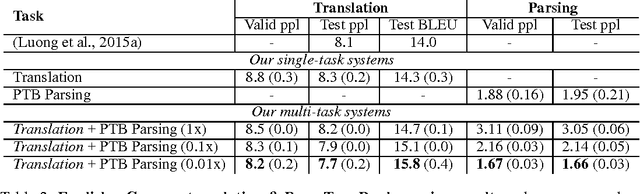
Sequence to sequence learning has recently emerged as a new paradigm in supervised learning. To date, most of its applications focused on only one task and not much work explored this framework for multiple tasks. This paper examines three multi-task learning (MTL) settings for sequence to sequence models: (a) the oneto-many setting - where the encoder is shared between several tasks such as machine translation and syntactic parsing, (b) the many-to-one setting - useful when only the decoder can be shared, as in the case of translation and image caption generation, and (c) the many-to-many setting - where multiple encoders and decoders are shared, which is the case with unsupervised objectives and translation. Our results show that training on a small amount of parsing and image caption data can improve the translation quality between English and German by up to 1.5 BLEU points over strong single-task baselines on the WMT benchmarks. Furthermore, we have established a new state-of-the-art result in constituent parsing with 93.0 F1. Lastly, we reveal interesting properties of the two unsupervised learning objectives, autoencoder and skip-thought, in the MTL context: autoencoder helps less in terms of perplexities but more on BLEU scores compared to skip-thought.
MuProp: Unbiased Backpropagation for Stochastic Neural Networks
Feb 25, 2016
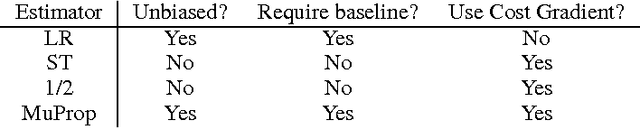
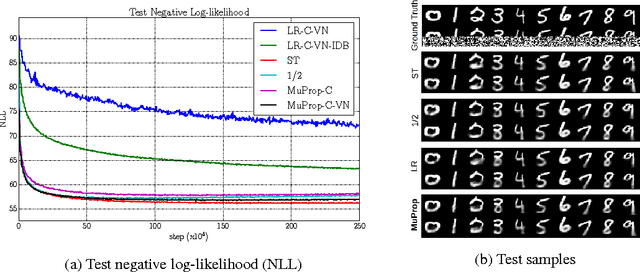

Deep neural networks are powerful parametric models that can be trained efficiently using the backpropagation algorithm. Stochastic neural networks combine the power of large parametric functions with that of graphical models, which makes it possible to learn very complex distributions. However, as backpropagation is not directly applicable to stochastic networks that include discrete sampling operations within their computational graph, training such networks remains difficult. We present MuProp, an unbiased gradient estimator for stochastic networks, designed to make this task easier. MuProp improves on the likelihood-ratio estimator by reducing its variance using a control variate based on the first-order Taylor expansion of a mean-field network. Crucially, unlike prior attempts at using backpropagation for training stochastic networks, the resulting estimator is unbiased and well behaved. Our experiments on structured output prediction and discrete latent variable modeling demonstrate that MuProp yields consistently good performance across a range of difficult tasks.
Neural Random-Access Machines
Feb 09, 2016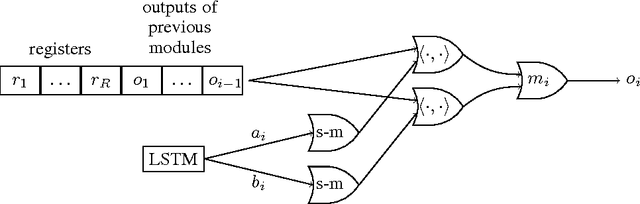
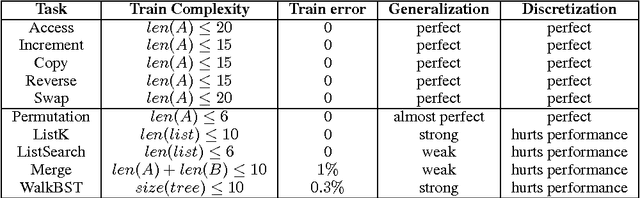
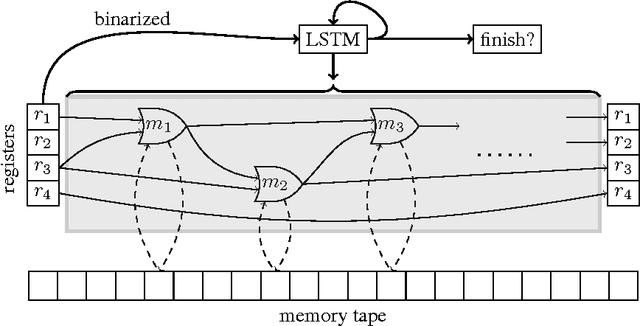
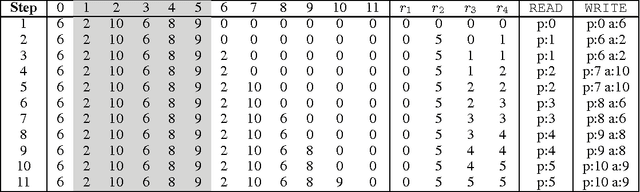
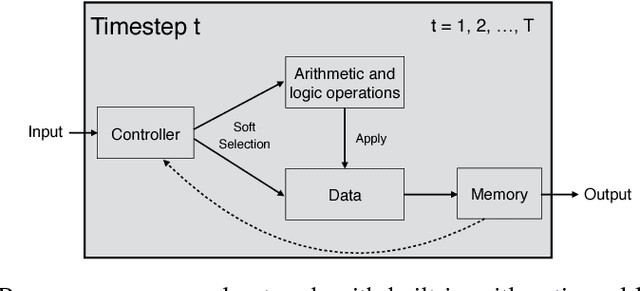
In this paper, we propose and investigate a new neural network architecture called Neural Random Access Machine. It can manipulate and dereference pointers to an external variable-size random-access memory. The model is trained from pure input-output examples using backpropagation. We evaluate the new model on a number of simple algorithmic tasks whose solutions require pointer manipulation and dereferencing. Our results show that the proposed model can learn to solve algorithmic tasks of such type and is capable of operating on simple data structures like linked-lists and binary trees. For easier tasks, the learned solutions generalize to sequences of arbitrary length. Moreover, memory access during inference can be done in a constant time under some assumptions.
Reinforcement Learning Neural Turing Machines - Revised
Jan 12, 2016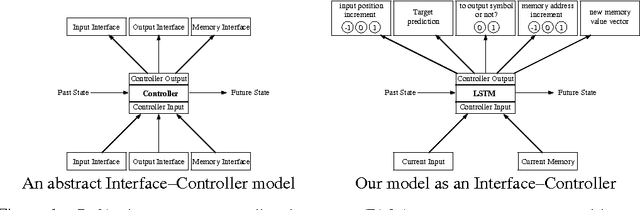


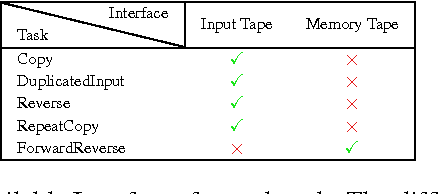
The Neural Turing Machine (NTM) is more expressive than all previously considered models because of its external memory. It can be viewed as a broader effort to use abstract external Interfaces and to learn a parametric model that interacts with them. The capabilities of a model can be extended by providing it with proper Interfaces that interact with the world. These external Interfaces include memory, a database, a search engine, or a piece of software such as a theorem verifier. Some of these Interfaces are provided by the developers of the model. However, many important existing Interfaces, such as databases and search engines, are discrete. We examine feasibility of learning models to interact with discrete Interfaces. We investigate the following discrete Interfaces: a memory Tape, an input Tape, and an output Tape. We use a Reinforcement Learning algorithm to train a neural network that interacts with such Interfaces to solve simple algorithmic tasks. Our Interfaces are expressive enough to make our model Turing complete.
Towards Principled Unsupervised Learning
Dec 03, 2015
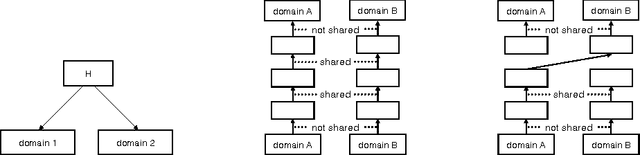

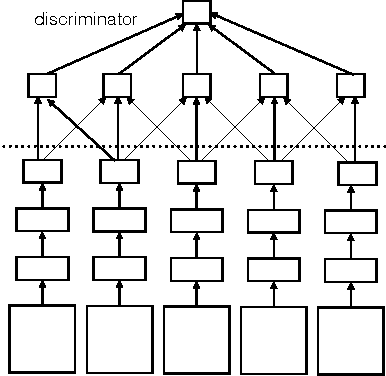
General unsupervised learning is a long-standing conceptual problem in machine learning. Supervised learning is successful because it can be solved by the minimization of the training error cost function. Unsupervised learning is not as successful, because the unsupervised objective may be unrelated to the supervised task of interest. For an example, density modelling and reconstruction have often been used for unsupervised learning, but they did not produced the sought-after performance gains, because they have no knowledge of the supervised tasks. In this paper, we present an unsupervised cost function which we name the Output Distribution Matching (ODM) cost, which measures a divergence between the distribution of predictions and distributions of labels. The ODM cost is appealing because it is consistent with the supervised cost in the following sense: a perfect supervised classifier is also perfect according to the ODM cost. Therefore, by aggressively optimizing the ODM cost, we are almost guaranteed to improve our supervised performance whenever the space of possible predictions is exponentially large. We demonstrate that the ODM cost works well on number of small and semi-artificial datasets using no (or almost no) labelled training cases. Finally, we show that the ODM cost can be used for one-shot domain adaptation, which allows the model to classify inputs that differ from the input distribution in significant ways without the need for prior exposure to the new domain.
Adding Gradient Noise Improves Learning for Very Deep Networks
Nov 21, 2015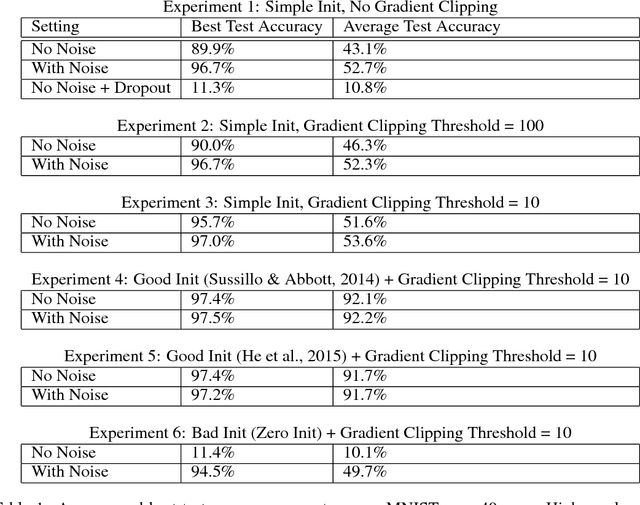

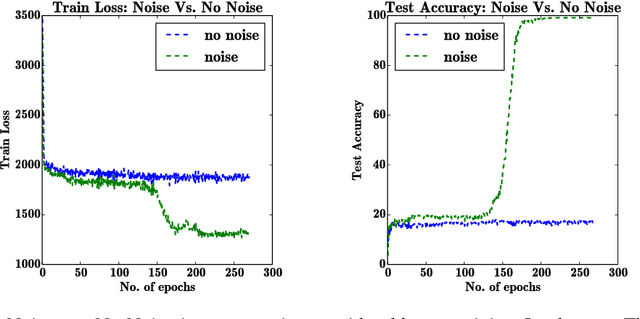
Deep feedforward and recurrent networks have achieved impressive results in many perception and language processing applications. This success is partially attributed to architectural innovations such as convolutional and long short-term memory networks. The main motivation for these architectural innovations is that they capture better domain knowledge, and importantly are easier to optimize than more basic architectures. Recently, more complex architectures such as Neural Turing Machines and Memory Networks have been proposed for tasks including question answering and general computation, creating a new set of optimization challenges. In this paper, we discuss a low-overhead and easy-to-implement technique of adding gradient noise which we find to be surprisingly effective when training these very deep architectures. The technique not only helps to avoid overfitting, but also can result in lower training loss. This method alone allows a fully-connected 20-layer deep network to be trained with standard gradient descent, even starting from a poor initialization. We see consistent improvements for many complex models, including a 72% relative reduction in error rate over a carefully-tuned baseline on a challenging question-answering task, and a doubling of the number of accurate binary multiplication models learned across 7,000 random restarts. We encourage further application of this technique to additional complex modern architectures.
Grammar as a Foreign Language
Jun 09, 2015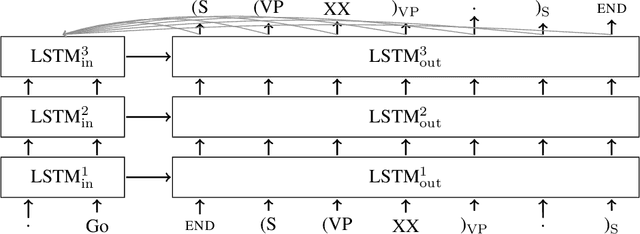
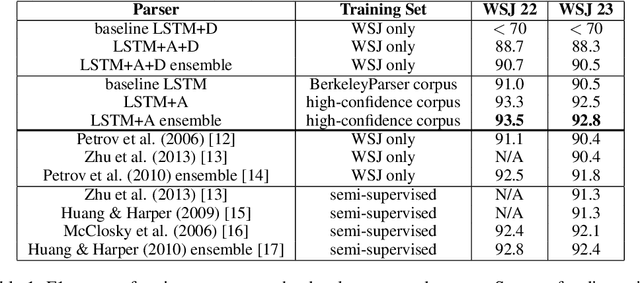
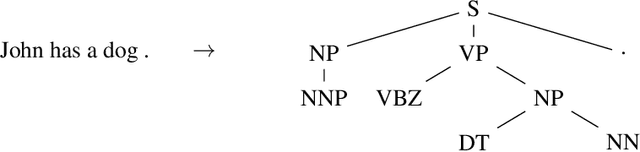
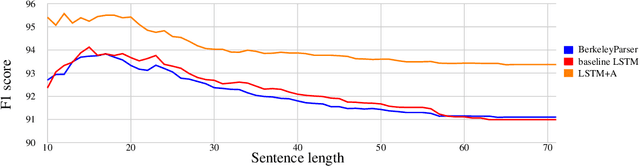
Syntactic constituency parsing is a fundamental problem in natural language processing and has been the subject of intensive research and engineering for decades. As a result, the most accurate parsers are domain specific, complex, and inefficient. In this paper we show that the domain agnostic attention-enhanced sequence-to-sequence model achieves state-of-the-art results on the most widely used syntactic constituency parsing dataset, when trained on a large synthetic corpus that was annotated using existing parsers. It also matches the performance of standard parsers when trained only on a small human-annotated dataset, which shows that this model is highly data-efficient, in contrast to sequence-to-sequence models without the attention mechanism. Our parser is also fast, processing over a hundred sentences per second with an unoptimized CPU implementation.
Addressing the Rare Word Problem in Neural Machine Translation
May 30, 2015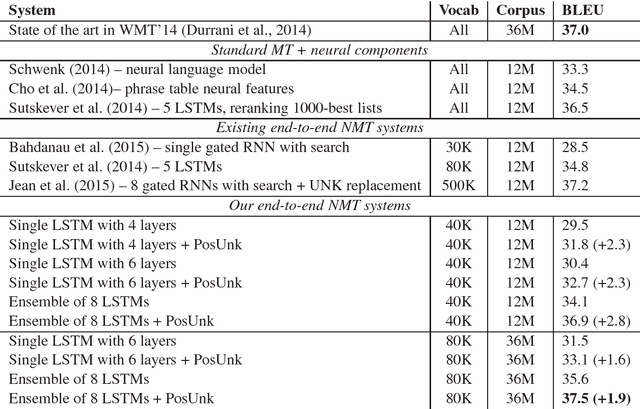


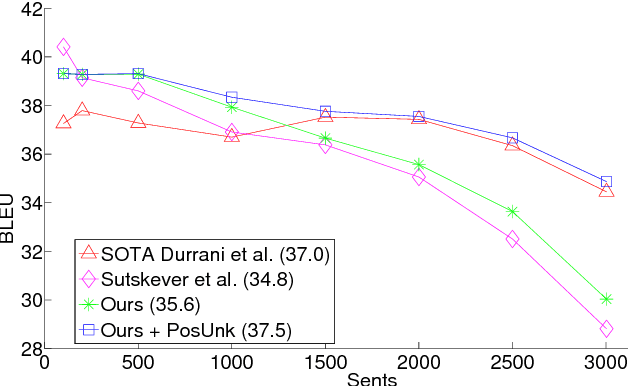
Neural Machine Translation (NMT) is a new approach to machine translation that has shown promising results that are comparable to traditional approaches. A significant weakness in conventional NMT systems is their inability to correctly translate very rare words: end-to-end NMTs tend to have relatively small vocabularies with a single unk symbol that represents every possible out-of-vocabulary (OOV) word. In this paper, we propose and implement an effective technique to address this problem. We train an NMT system on data that is augmented by the output of a word alignment algorithm, allowing the NMT system to emit, for each OOV word in the target sentence, the position of its corresponding word in the source sentence. This information is later utilized in a post-processing step that translates every OOV word using a dictionary. Our experiments on the WMT14 English to French translation task show that this method provides a substantial improvement of up to 2.8 BLEU points over an equivalent NMT system that does not use this technique. With 37.5 BLEU points, our NMT system is the first to surpass the best result achieved on a WMT14 contest task.
Move Evaluation in Go Using Deep Convolutional Neural Networks
Apr 10, 2015
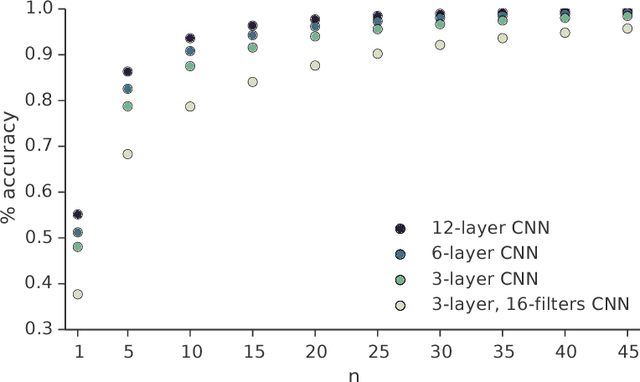
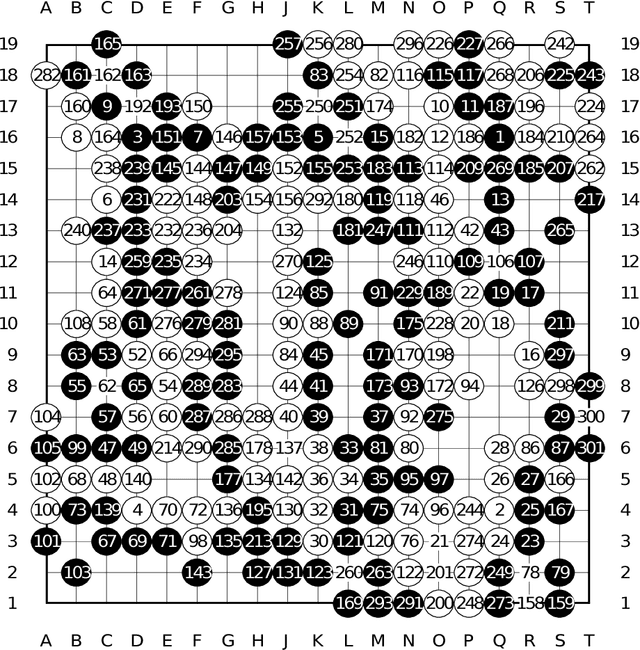
The game of Go is more challenging than other board games, due to the difficulty of constructing a position or move evaluation function. In this paper we investigate whether deep convolutional networks can be used to directly represent and learn this knowledge. We train a large 12-layer convolutional neural network by supervised learning from a database of human professional games. The network correctly predicts the expert move in 55% of positions, equalling the accuracy of a 6 dan human player. When the trained convolutional network was used directly to play games of Go, without any search, it beat the traditional search program GnuGo in 97% of games, and matched the performance of a state-of-the-art Monte-Carlo tree search that simulates a million positions per move.
Learning to Execute
Feb 19, 2015

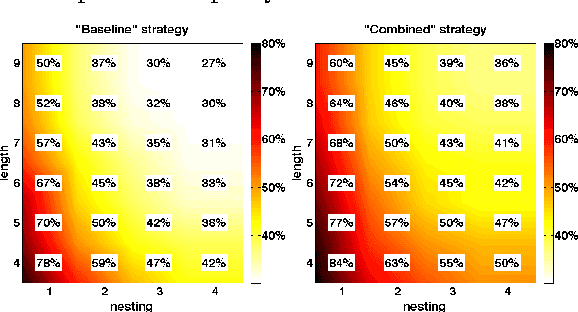
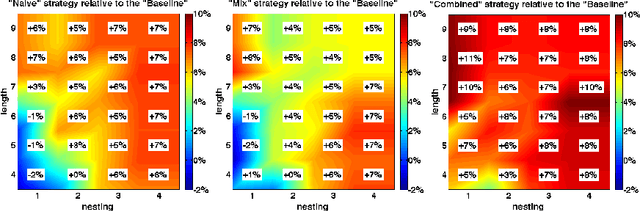
Recurrent Neural Networks (RNNs) with Long Short-Term Memory units (LSTM) are widely used because they are expressive and are easy to train. Our interest lies in empirically evaluating the expressiveness and the learnability of LSTMs in the sequence-to-sequence regime by training them to evaluate short computer programs, a domain that has traditionally been seen as too complex for neural networks. We consider a simple class of programs that can be evaluated with a single left-to-right pass using constant memory. Our main result is that LSTMs can learn to map the character-level representations of such programs to their correct outputs. Notably, it was necessary to use curriculum learning, and while conventional curriculum learning proved ineffective, we developed a new variant of curriculum learning that improved our networks' performance in all experimental conditions. The improved curriculum had a dramatic impact on an addition problem, making it possible to train an LSTM to add two 9-digit numbers with 99% accuracy.