 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Planning in Combinatorial Action Spaces with Applications to Cooperative Multi-Agent Reinforcement Learning
Feb 08, 2023A practical challenge in reinforcement learning are combinatorial action spaces that make planning computationally demanding. For example, in cooperative multi-agent reinforcement learning, a potentially large number of agents jointly optimize a global reward function, which leads to a combinatorial blow-up in the action space by the number of agents. As a minimal requirement, we assume access to an argmax oracle that allows to efficiently compute the greedy policy for any Q-function in the model class. Building on recent work in planning with local access to a simulator and linear function approximation, we propose efficient algorithms for this setting that lead to polynomial compute and query complexity in all relevant problem parameters. For the special case where the feature decomposition is additive, we further improve the bounds and extend the results to the kernelized setting with an efficient algorithm.
Near-optimal Policy Identification in Active Reinforcement Learning
Dec 19, 2022



Many real-world reinforcement learning tasks require control of complex dynamical systems that involve both costly data acquisition processes and large state spaces. In cases where the transition dynamics can be readily evaluated at specified states (e.g., via a simulator), agents can operate in what is often referred to as planning with a \emph{generative model}. We propose the AE-LSVI algorithm for best-policy identification, a novel variant of the kernelized least-squares value iteration (LSVI) algorithm that combines optimism with pessimism for active exploration (AE). AE-LSVI provably identifies a near-optimal policy \emph{uniformly} over an entire state space and achieves polynomial sample complexity guarantees that are independent of the number of states. When specialized to the recently introduced offline contextual Bayesian optimization setting, our algorithm achieves improved sample complexity bounds. Experimentally, we demonstrate that AE-LSVI outperforms other RL algorithms in a variety of environments when robustness to the initial state is required.
Movement Penalized Bayesian Optimization with Application to Wind Energy Systems
Oct 14, 2022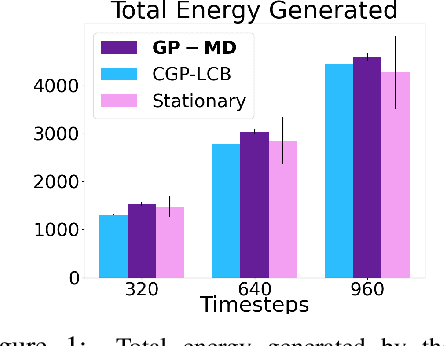
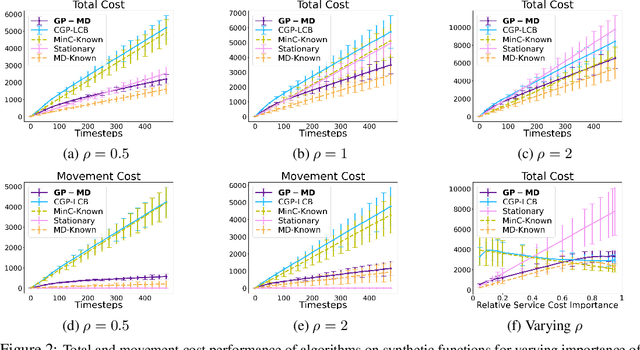
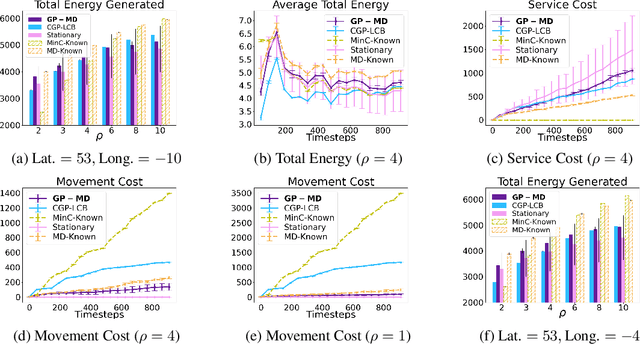
Contextual Bayesian optimization (CBO) is a powerful framework for sequential decision-making given side information, with important applications, e.g., in wind energy systems. In this setting, the learner receives context (e.g., weather conditions) at each round, and has to choose an action (e.g., turbine parameters). Standard algorithms assume no cost for switching their decisions at every round. However, in many practical applications, there is a cost associated with such changes, which should be minimized. We introduce the episodic CBO with movement costs problem and, based on the online learning approach for metrical task systems of Coester and Lee (2019), propose a novel randomized mirror descent algorithm that makes use of Gaussian Process confidence bounds. We compare its performance with the offline optimal sequence for each episode and provide rigorous regret guarantees. We further demonstrate our approach on the important real-world application of altitude optimization for Airborne Wind Energy Systems. In the presence of substantial movement costs, our algorithm consistently outperforms standard CBO algorithms.
Graph Neural Network Bandits
Jul 13, 2022
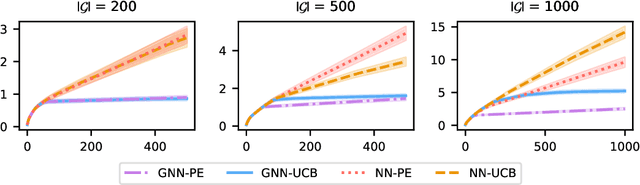
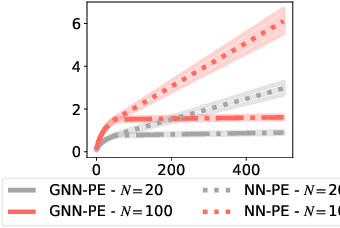
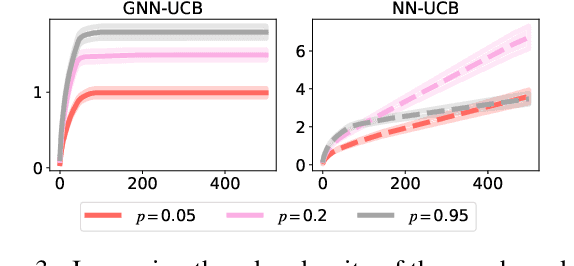
We consider the bandit optimization problem with the reward function defined over graph-structured data. This problem has important applications in molecule design and drug discovery, where the reward is naturally invariant to graph permutations. The key challenges in this setting are scaling to large domains, and to graphs with many nodes. We resolve these challenges by embedding the permutation invariance into our model. In particular, we show that graph neural networks (GNNs) can be used to estimate the reward function, assuming it resides in the Reproducing Kernel Hilbert Space of a permutation-invariant additive kernel. By establishing a novel connection between such kernels and the graph neural tangent kernel (GNTK), we introduce the first GNN confidence bound and use it to design a phased-elimination algorithm with sublinear regret. Our regret bound depends on the GNTK's maximum information gain, which we also provide a bound for. While the reward function depends on all $N$ node features, our guarantees are independent of the number of graph nodes $N$. Empirically, our approach exhibits competitive performance and scales well on graph-structured domains.
A Robust Phased Elimination Algorithm for Corruption-Tolerant Gaussian Process Bandits
Feb 03, 2022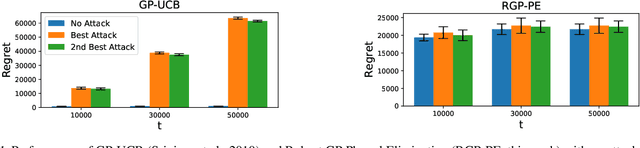

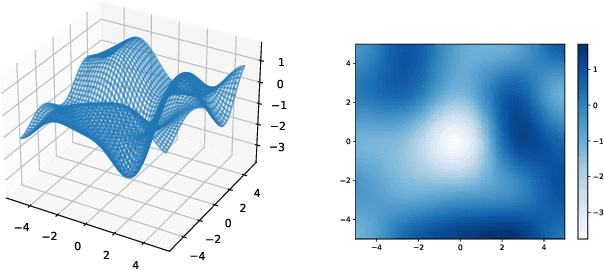
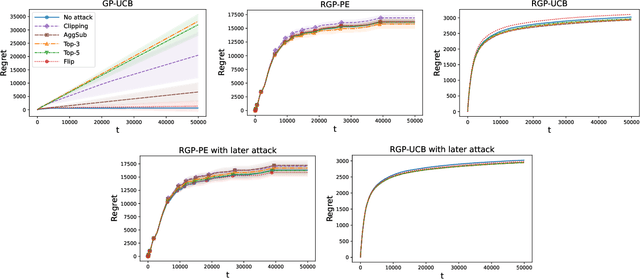
We consider the sequential optimization of an unknown, continuous, and expensive to evaluate reward function, from noisy and adversarially corrupted observed rewards. When the corruption attacks are subject to a suitable budget $C$ and the function lives in a Reproducing Kernel Hilbert Space (RKHS), the problem can be posed as corrupted Gaussian process (GP) bandit optimization. We propose a novel robust elimination-type algorithm that runs in epochs, combines exploration with infrequent switching to select a small subset of actions, and plays each action for multiple time instants. Our algorithm, Robust GP Phased Elimination (RGP-PE), successfully balances robustness to corruptions with exploration and exploitation such that its performance degrades minimally in the presence (or absence) of adversarial corruptions. When $T$ is the number of samples and $\gamma_T$ is the maximal information gain, the corruption-dependent term in our regret bound is $O(C \gamma_T^{3/2})$, which is significantly tighter than the existing $O(C \sqrt{T \gamma_T})$ for several commonly-considered kernels. We perform the first empirical study of robustness in the corrupted GP bandit setting, and show that our algorithm is robust against a variety of adversarial attacks.
Misspecified Gaussian Process Bandit Optimization
Nov 09, 2021We consider the problem of optimizing a black-box function based on noisy bandit feedback. Kernelized bandit algorithms have shown strong empirical and theoretical performance for this problem. They heavily rely on the assumption that the model is well-specified, however, and can fail without it. Instead, we introduce a \emph{misspecified} kernelized bandit setting where the unknown function can be $\epsilon$--uniformly approximated by a function with a bounded norm in some Reproducing Kernel Hilbert Space (RKHS). We design efficient and practical algorithms whose performance degrades minimally in the presence of model misspecification. Specifically, we present two algorithms based on Gaussian process (GP) methods: an optimistic EC-GP-UCB algorithm that requires knowing the misspecification error, and Phased GP Uncertainty Sampling, an elimination-type algorithm that can adapt to unknown model misspecification. We provide upper bounds on their cumulative regret in terms of $\epsilon$, the time horizon, and the underlying kernel, and we show that our algorithm achieves optimal dependence on $\epsilon$ with no prior knowledge of misspecification. In addition, in a stochastic contextual setting, we show that EC-GP-UCB can be effectively combined with the regret bound balancing strategy and attain similar regret bounds despite not knowing $\epsilon$.
Risk-averse Heteroscedastic Bayesian Optimization
Nov 05, 2021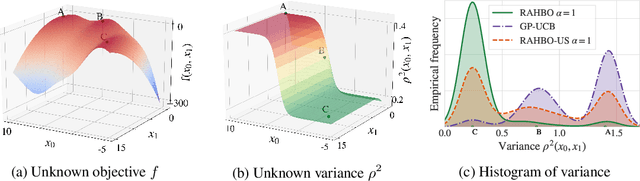

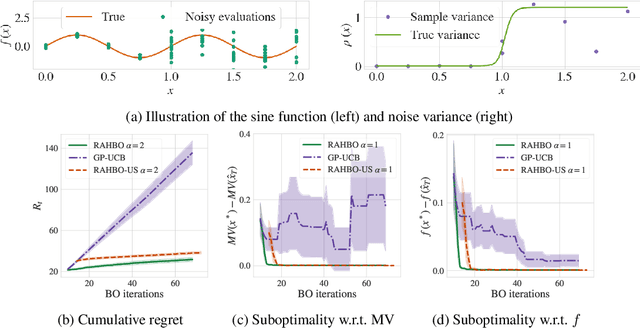
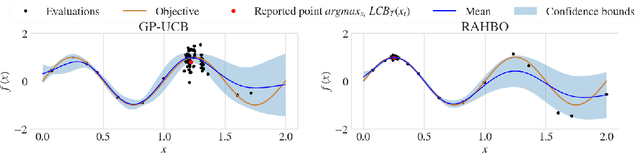
Many black-box optimization tasks arising in high-stakes applications require risk-averse decisions. The standard Bayesian optimization (BO) paradigm, however, optimizes the expected value only. We generalize BO to trade mean and input-dependent variance of the objective, both of which we assume to be unknown a priori. In particular, we propose a novel risk-averse heteroscedastic Bayesian optimization algorithm (RAHBO) that aims to identify a solution with high return and low noise variance, while learning the noise distribution on the fly. To this end, we model both expectation and variance as (unknown) RKHS functions, and propose a novel risk-aware acquisition function. We bound the regret for our approach and provide a robust rule to report the final decision point for applications where only a single solution must be identified. We demonstrate the effectiveness of RAHBO on synthetic benchmark functions and hyperparameter tuning tasks.
Contextual Games: Multi-Agent Learning with Side Information
Jul 13, 2021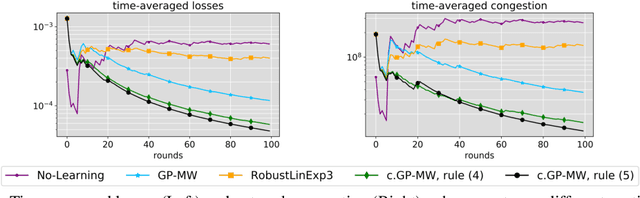
We formulate the novel class of contextual games, a type of repeated games driven by contextual information at each round. By means of kernel-based regularity assumptions, we model the correlation between different contexts and game outcomes and propose a novel online (meta) algorithm that exploits such correlations to minimize the contextual regret of individual players. We define game-theoretic notions of contextual Coarse Correlated Equilibria (c-CCE) and optimal contextual welfare for this new class of games and show that c-CCEs and optimal welfare can be approached whenever players' contextual regrets vanish. Finally, we empirically validate our results in a traffic routing experiment, where our algorithm leads to better performance and higher welfare compared to baselines that do not exploit the available contextual information or the correlations present in the game.
Efficient Model-Based Multi-Agent Mean-Field Reinforcement Learning
Jul 08, 2021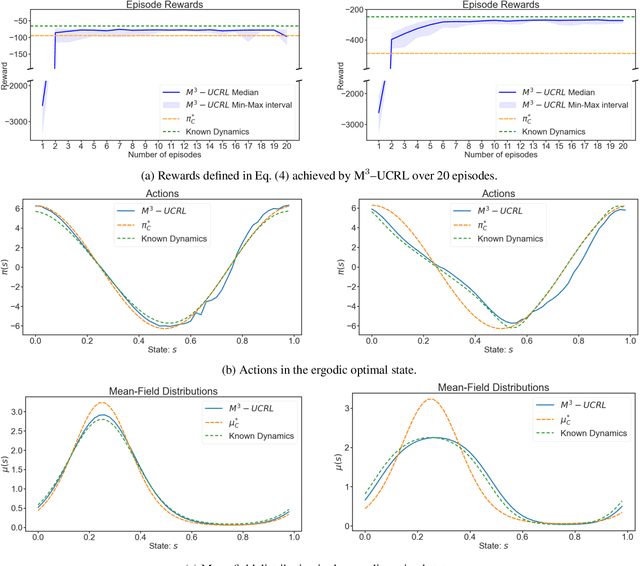
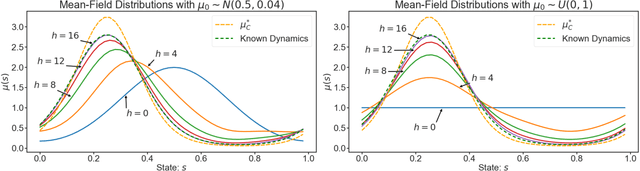
Learning in multi-agent systems is highly challenging due to the inherent complexity introduced by agents' interactions. We tackle systems with a huge population of interacting agents (e.g., swarms) via Mean-Field Control (MFC). MFC considers an asymptotically infinite population of identical agents that aim to collaboratively maximize the collective reward. Specifically, we consider the case of unknown system dynamics where the goal is to simultaneously optimize for the rewards and learn from experience. We propose an efficient model-based reinforcement learning algorithm $\text{M}^3\text{-UCRL}$ that runs in episodes and provably solves this problem. $\text{M}^3\text{-UCRL}$ uses upper-confidence bounds to balance exploration and exploitation during policy learning. Our main theoretical contributions are the first general regret bounds for model-based RL for MFC, obtained via a novel mean-field type analysis. $\text{M}^3\text{-UCRL}$ can be instantiated with different models such as neural networks or Gaussian Processes, and effectively combined with neural network policy learning. We empirically demonstrate the convergence of $\text{M}^3\text{-UCRL}$ on the swarm motion problem of controlling an infinite population of agents seeking to maximize location-dependent reward and avoid congested areas.
Combining Pessimism with Optimism for Robust and Efficient Model-Based Deep Reinforcement Learning
Mar 18, 2021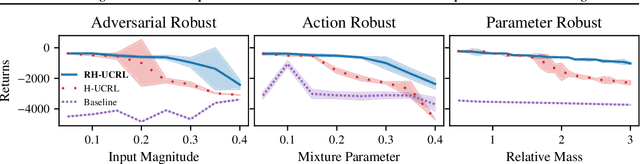
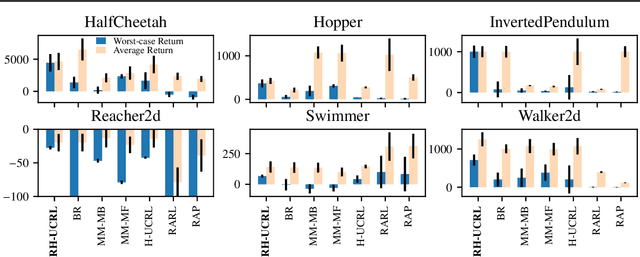
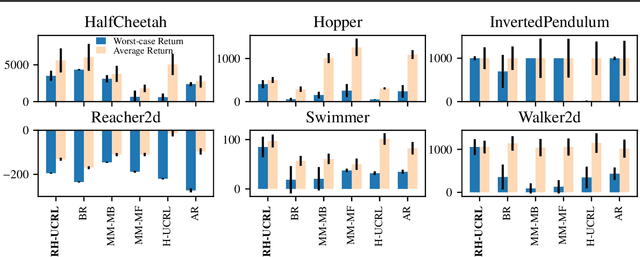
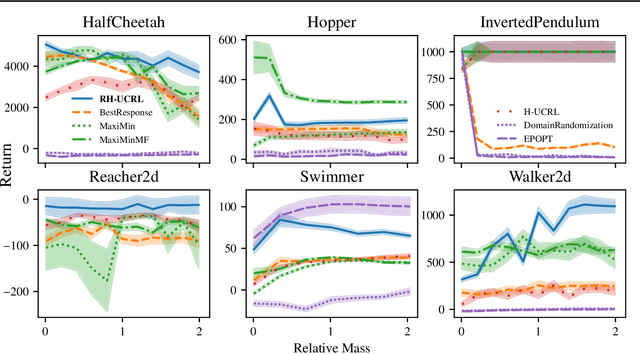
In real-world tasks, reinforcement learning (RL) agents frequently encounter situations that are not present during training time. To ensure reliable performance, the RL agents need to exhibit robustness against worst-case situations. The robust RL framework addresses this challenge via a worst-case optimization between an agent and an adversary. Previous robust RL algorithms are either sample inefficient, lack robustness guarantees, or do not scale to large problems. We propose the Robust Hallucinated Upper-Confidence RL (RH-UCRL) algorithm to provably solve this problem while attaining near-optimal sample complexity guarantees. RH-UCRL is a model-based reinforcement learning (MBRL) algorithm that effectively distinguishes between epistemic and aleatoric uncertainty and efficiently explores both the agent and adversary decision spaces during policy learning. We scale RH-UCRL to complex tasks via neural networks ensemble models as well as neural network policies. Experimentally, we demonstrate that RH-UCRL outperforms other robust deep RL algorithms in a variety of adversarial environments.