 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistDNAS: Search Efficient Feature Interactions within 2 Hours
Nov 01, 2023



Search efficiency and serving efficiency are two major axes in building feature interactions and expediting the model development process in recommender systems. On large-scale benchmarks, searching for the optimal feature interaction design requires extensive cost due to the sequential workflow on the large volume of data. In addition, fusing interactions of various sources, orders, and mathematical operations introduces potential conflicts and additional redundancy toward recommender models, leading to sub-optimal trade-offs in performance and serving cost. In this paper, we present DistDNAS as a neat solution to brew swift and efficient feature interaction design. DistDNAS proposes a supernet to incorporate interaction modules of varying orders and types as a search space. To optimize search efficiency, DistDNAS distributes the search and aggregates the choice of optimal interaction modules on varying data dates, achieving over 25x speed-up and reducing search cost from 2 days to 2 hours. To optimize serving efficiency, DistDNAS introduces a differentiable cost-aware loss to penalize the selection of redundant interaction modules, enhancing the efficiency of discovered feature interactions in serving. We extensively evaluate the best models crafted by DistDNAS on a 1TB Criteo Terabyte dataset. Experimental evaluations demonstrate 0.001 AUC improvement and 60% FLOPs saving over current state-of-the-art CTR models.
PerfSAGE: Generalized Inference Performance Predictor for Arbitrary Deep Learning Models on Edge Devices
Jan 26, 2023The ability to accurately predict deep neural network (DNN) inference performance metrics, such as latency, power, and memory footprint, for an arbitrary DNN on a target hardware platform is essential to the design of DNN based models. This ability is critical for the (manual or automatic) design, optimization, and deployment of practical DNNs for a specific hardware deployment platform. Unfortunately, these metrics are slow to evaluate using simulators (where available) and typically require measurement on the target hardware. This work describes PerfSAGE, a novel graph neural network (GNN) that predicts inference latency, energy, and memory footprint on an arbitrary DNN TFlite graph (TFL, 2017). In contrast, previously published performance predictors can only predict latency and are restricted to pre-defined construction rules or search spaces. This paper also describes the EdgeDLPerf dataset of 134,912 DNNs randomly sampled from four task search spaces and annotated with inference performance metrics from three edge hardware platforms. Using this dataset, we train PerfSAGE and provide experimental results that demonstrate state-of-the-art prediction accuracy with a Mean Absolute Percentage Error of <5% across all targets and model search spaces. These results: (1) Outperform previous state-of-art GNN-based predictors (Dudziak et al., 2020), (2) Accurately predict performance on accelerators (a shortfall of non-GNN-based predictors (Zhang et al., 2021)), and (3) Demonstrate predictions on arbitrary input graphs without modifications to the feature extractor.
Restructurable Activation Networks
Aug 17, 2022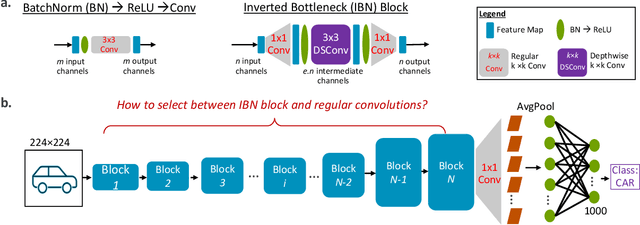
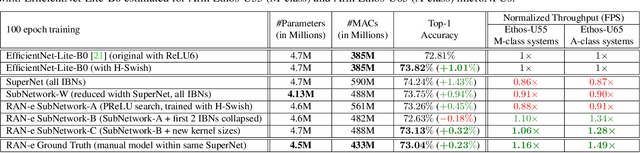
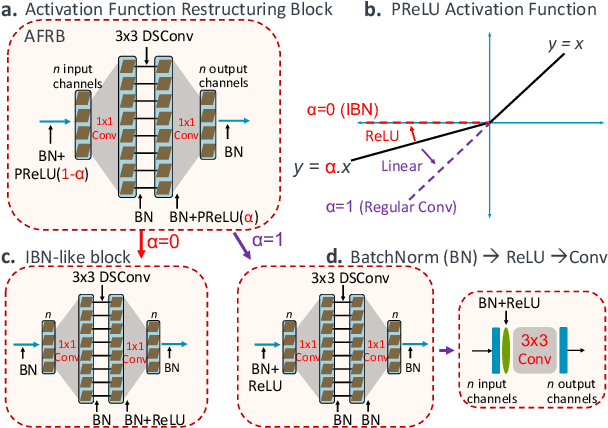
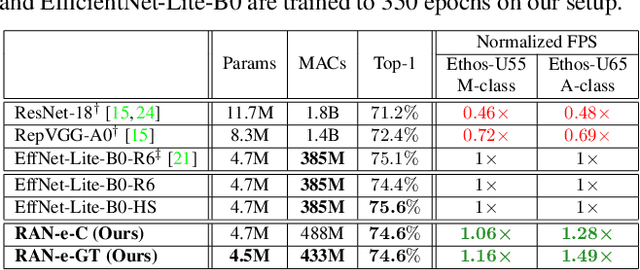
Is it possible to restructure the non-linear activation functions in a deep network to create hardware-efficient models? To address this question, we propose a new paradigm called Restructurable Activation Networks (RANs) that manipulate the amount of non-linearity in models to improve their hardware-awareness and efficiency. First, we propose RAN-explicit (RAN-e) -- a new hardware-aware search space and a semi-automatic search algorithm -- to replace inefficient blocks with hardware-aware blocks. Next, we propose a training-free model scaling method called RAN-implicit (RAN-i) where we theoretically prove the link between network topology and its expressivity in terms of number of non-linear units. We demonstrate that our networks achieve state-of-the-art results on ImageNet at different scales and for several types of hardware. For example, compared to EfficientNet-Lite-B0, RAN-e achieves a similar accuracy while improving Frames-Per-Second (FPS) by 1.5x on Arm micro-NPUs. On the other hand, RAN-i demonstrates up to 2x reduction in #MACs over ConvNexts with a similar or better accuracy. We also show that RAN-i achieves nearly 40% higher FPS than ConvNext on Arm-based datacenter CPUs. Finally, RAN-i based object detection networks achieve a similar or higher mAP and up to 33% higher FPS on datacenter CPUs compared to ConvNext based models.
Magnitude-aware Probabilistic Speaker Embeddings
Feb 28, 2022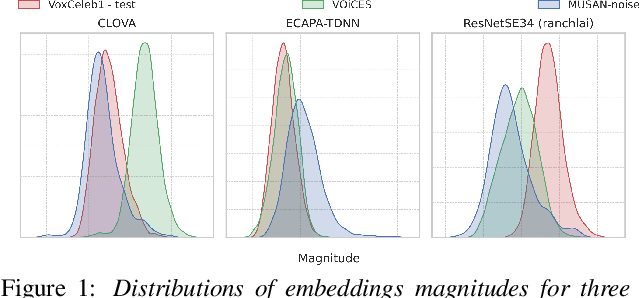


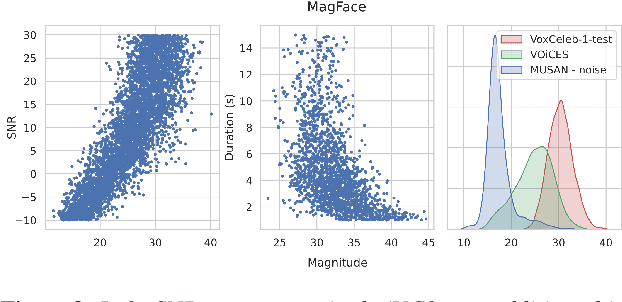
Recently, hyperspherical embeddings have established themselves as a dominant technique for face and voice recognition. Specifically, Euclidean space vector embeddings are learned to encode person-specific information in their direction while ignoring the magnitude. However, recent studies have shown that the magnitudes of the embeddings extracted by deep neural networks may indicate the quality of the corresponding inputs. This paper explores the properties of the magnitudes of the embeddings related to quality assessment and out-of-distribution detection. We propose a new probabilistic speaker embedding extractor using the information encoded in the embedding magnitude and leverage it in the speaker verification pipeline. We also propose several quality-aware diarization methods and incorporate the magnitudes in those. Our results indicate significant improvements over magnitude-agnostic baselines both in speaker verification and diarization tasks.
UDC: Unified DNAS for Compressible TinyML Models
Jan 21, 2022
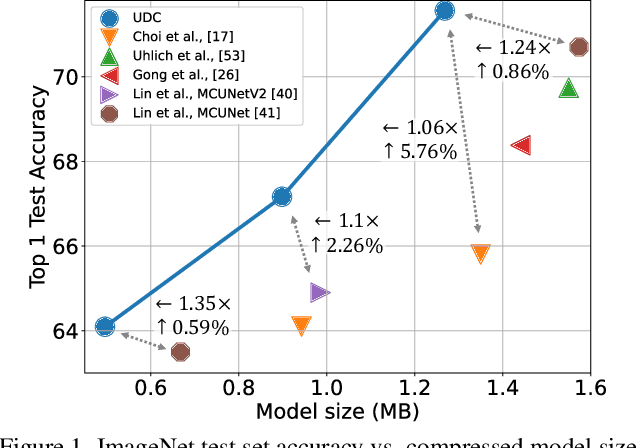
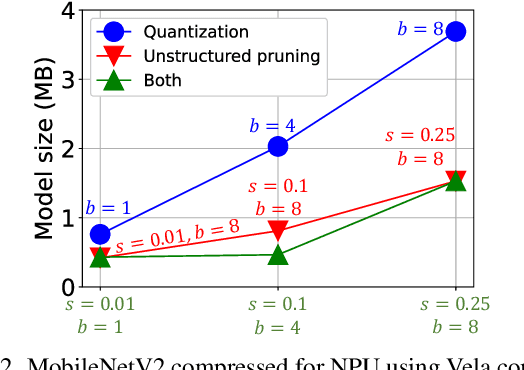
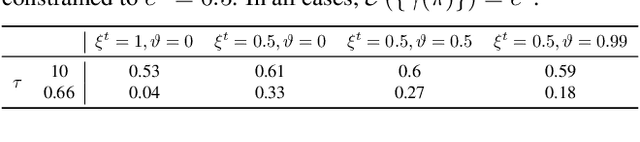
Emerging Internet-of-things (IoT) applications are driving deployment of neural networks (NNs) on heavily constrained low-cost hardware (HW) platforms, where accuracy is typically limited by memory capacity. To address this TinyML challenge, new HW platforms like neural processing units (NPUs) have support for model compression, which exploits aggressive network quantization and unstructured pruning optimizations. The combination of NPUs with HW compression and compressible models allows more expressive models in the same memory footprint. However, adding optimizations for compressibility on top of conventional NN architecture choices expands the design space across which we must make balanced trade-offs. This work bridges the gap between NPU HW capability and NN model design, by proposing a neural architecture search (NAS) algorithm to efficiently search a large design space, including: network depth, operator type, layer width, bitwidth, sparsity, and more. Building on differentiable NAS (DNAS) with several key improvements, we demonstrate Unified DNAS for Compressible models (UDC) on CIFAR100, ImageNet, and DIV2K super resolution tasks. On ImageNet, we find Pareto dominant compressible models, which are 1.9x smaller or 5.76% more accurate.
MicroNets: Neural Network Architectures for Deploying TinyML Applications on Commodity Microcontrollers
Oct 25, 2020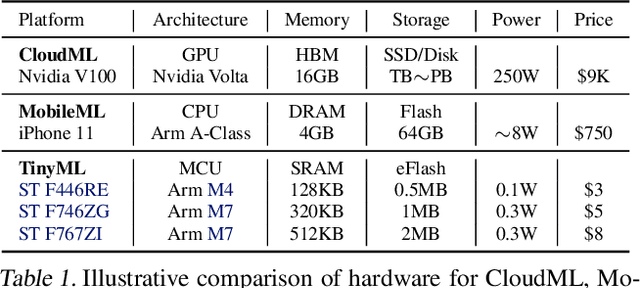
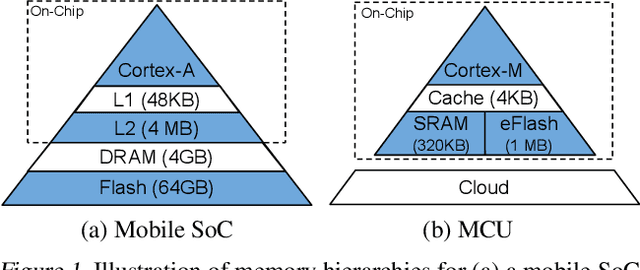
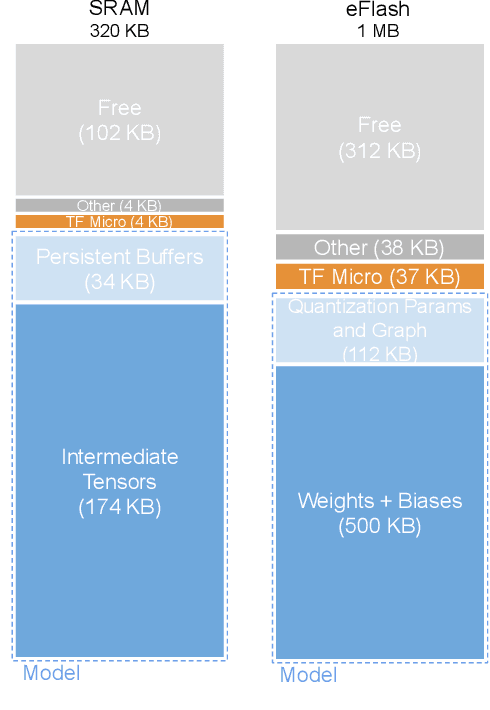
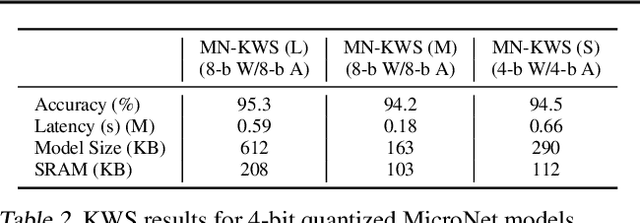
Executing machine learning workloads locally on resource constrained microcontrollers (MCUs) promises to drastically expand the application space of IoT. However, so-called TinyML presents severe technical challenges, as deep neural network inference demands a large compute and memory budget. To address this challenge, neural architecture search (NAS) promises to help design accurate ML models that meet the tight MCU memory, latency and energy constraints. A key component of NAS algorithms is their latency/energy model, i.e., the mapping from a given neural network architecture to its inference latency/energy on an MCU. In this paper, we observe an intriguing property of NAS search spaces for MCU model design: on average, model latency varies linearly with model operation (op) count under a uniform prior over models in the search space. Exploiting this insight, we employ differentiable NAS (DNAS) to search for models with low memory usage and low op count, where op count is treated as a viable proxy to latency. Experimental results validate our methodology, yielding our MicroNet models, which we deploy on MCUs using Tensorflow Lite Micro, a standard open-source NN inference runtime widely used in the TinyML community. MicroNets demonstrate state-of-the-art results for all three TinyMLperf industry-standard benchmark tasks: visual wake words, audio keyword spotting, and anomaly detection.
MANGO: A Python Library for Parallel Hyperparameter Tuning
May 22, 2020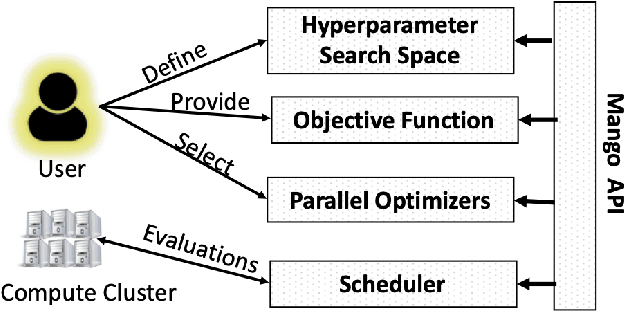
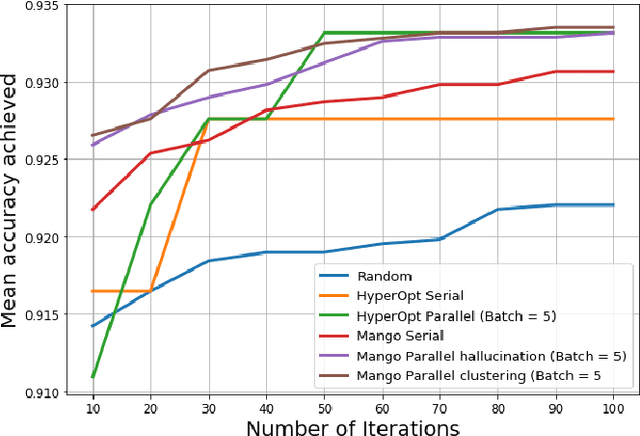
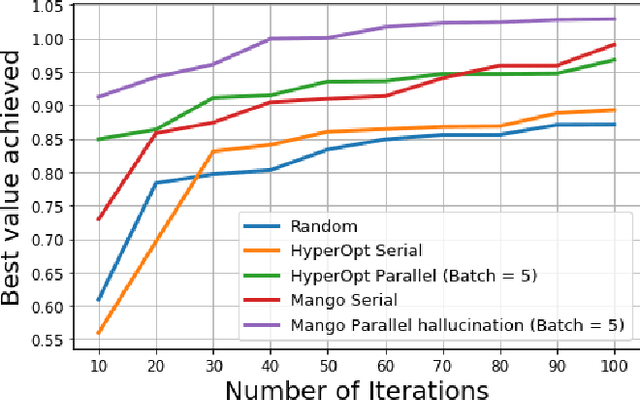
Tuning hyperparameters for machine learning algorithms is a tedious task, one that is typically done manually. To enable automated hyperparameter tuning, recent works have started to use techniques based on Bayesian optimization. However, to practically enable automated tuning for large scale machine learning training pipelines, significant gaps remain in existing libraries, including lack of abstractions, fault tolerance, and flexibility to support scheduling on any distributed computing framework. To address these challenges, we present Mango, a Python library for parallel hyperparameter tuning. Mango enables the use of any distributed scheduling framework, implements intelligent parallel search strategies, and provides rich abstractions for defining complex hyperparameter search spaces that are compatible with scikit-learn. Mango is comparable in performance to Hyperopt, another widely used library. Mango is available open-source and is currently used in production at Arm Research to provide state-of-art hyperparameter tuning capabilities.
TinyLSTMs: Efficient Neural Speech Enhancement for Hearing Aids
May 20, 2020
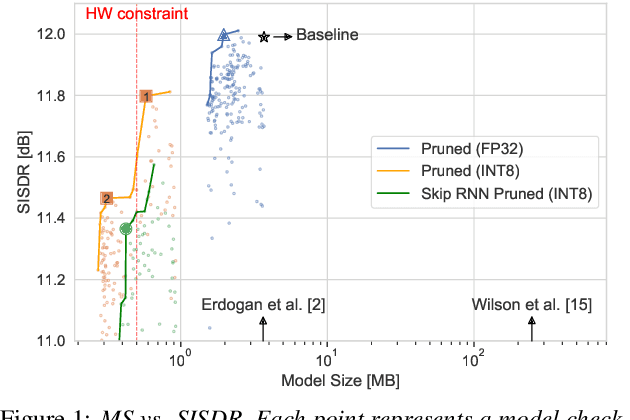
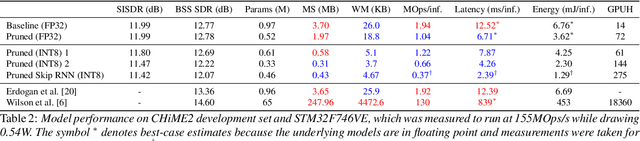
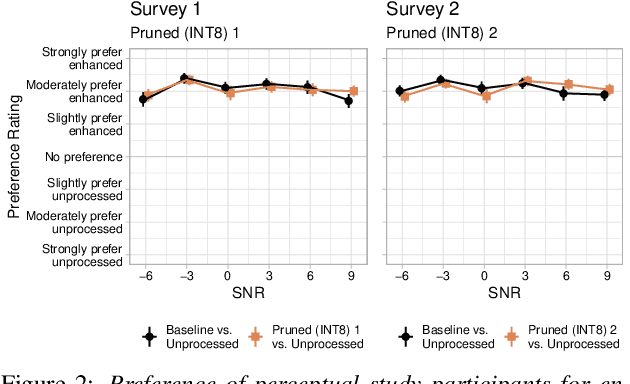
Modern speech enhancement algorithms achieve remarkable noise suppression by means of large recurrent neural networks (RNNs). However, large RNNs limit practical deployment in hearing aid hardware (HW) form-factors, which are battery powered and run on resource-constrained microcontroller units (MCUs) with limited memory capacity and compute capability. In this work, we use model compression techniques to bridge this gap. We define the constraints imposed on the RNN by the HW and describe a method to satisfy them. Although model compression techniques are an active area of research, we are the first to demonstrate their efficacy for RNN speech enhancement, using pruning and integer quantization of weights/activations. We also demonstrate state update skipping, which reduces the computational load. Finally, we conduct a perceptual evaluation of the compressed models to verify audio quality on human raters. Results show a reduction in model size and operations of 11.9$\times$ and 2.9$\times$, respectively, over the baseline for compressed models, without a statistical difference in listening preference and only exhibiting a loss of 0.55dB SDR. Our model achieves a computational latency of 2.39ms, well within the 10ms target and 351$\times$ better than previous work.
Pushing the limits of RNN Compression
Oct 09, 2019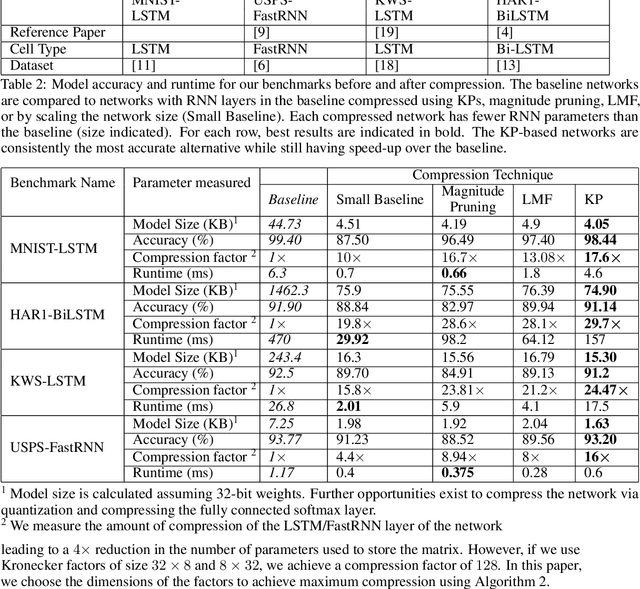
Recurrent Neural Networks (RNN) can be difficult to deploy on resource constrained devices due to their size. As a result, there is a need for compression techniques that can significantly compress RNNs without negatively impacting task accuracy. This paper introduces a method to compress RNNs for resource constrained environments using Kronecker product (KP). KPs can compress RNN layers by 16-38x with minimal accuracy loss. We show that KP can beat the task accuracy achieved by other state-of-the-art compression techniques (pruning and low-rank matrix factorization) across 4 benchmarks spanning 3 different applications, while simultaneously improving inference run-time.
* 6 pages. arXiv admin note: substantial text overlap with arXiv:1906.02876
Compressing RNNs for IoT devices by 15-38x using Kronecker Products
Jun 18, 2019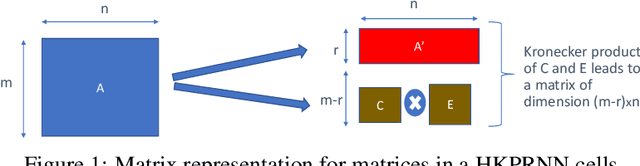
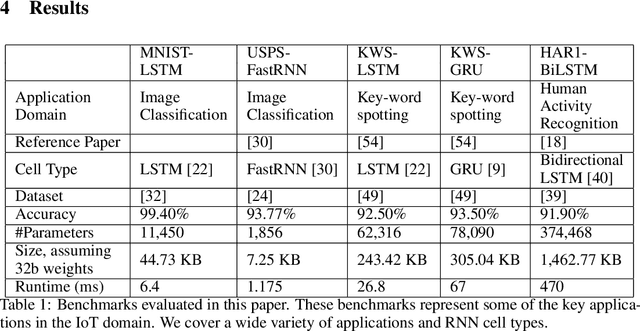
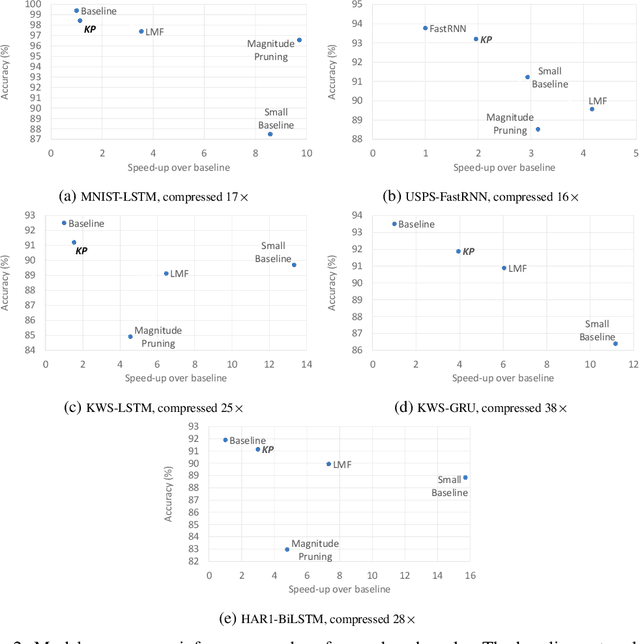
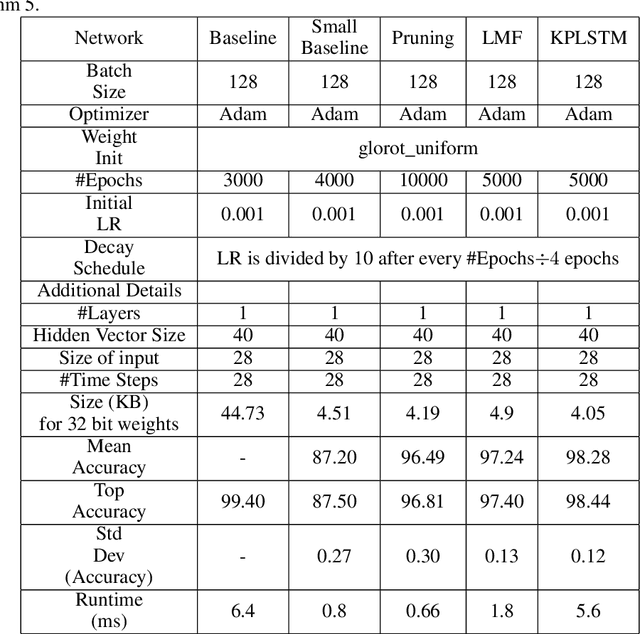
Recurrent Neural Networks (RNN) can be large and compute-intensive, making them hard to deploy on resource constrained devices. As a result, there is a need for compression technique that can significantly compress recurrent neural networks, without negatively impacting task accuracy. This paper introduces a method to compress RNNs for resource constrained environments using Kronecker products. We call the RNNs compressed using Kronecker products as Kronecker product Recurrent Neural Networks (KPRNNs). KPRNNs can compress the LSTM[22], GRU [9] and parameter optimized FastRNN [30] layers by 15 - 38x with minor loss in accuracy and can act as in-place replacement of most RNN cells in existing applications. By quantizing the Kronecker compressed networks to 8 bits, we further push the compression factor to 50x. We compare the accuracy and runtime of KPRNNs with other state-of-the-art compression techniques across 5 benchmarks spanning 3 different applications, showing its generality. Additionally, we show how to control the compression factors achieved by Kronecker products using a novel hybrid decomposition technique. We call the RNN cells compressed using Kronecker products with this control mechanism as hybrid Kronecker product RNNs (HKPRNN). Using HKPRNN, we compress RNN Cells in 2 benchmarks by 10x and 20x achieving better accuracy than other state-of-the-art compression techniques.