 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCADO: From Imitation to Cost Minimization for Heatmap-based Solvers in Combinatorial Optimization
Feb 09, 2026Heatmap-based solvers have emerged as a promising paradigm for Combinatorial Optimization (CO). However, we argue that the dominant Supervised Learning (SL) training paradigm suffers from a fundamental objective mismatch: minimizing imitation loss (e.g., cross-entropy) does not guarantee solution cost minimization. We dissect this mismatch into two deficiencies: Decoder-Blindness (being oblivious to the non-differentiable decoding process) and Cost-Blindness (prioritizing structural imitation over solution quality). We empirically demonstrate that these intrinsic flaws impose a hard performance ceiling. To overcome this limitation, we propose CADO (Cost-Aware Diffusion models for Optimization), a streamlined Reinforcement Learning fine-tuning framework that formulates the diffusion denoising process as an MDP to directly optimize the post-decoded solution cost. We introduce Label-Centered Reward, which repurposes ground-truth labels as unbiased baselines rather than imitation targets, and Hybrid Fine-Tuning for parameter-efficient adaptation. CADO achieves state-of-the-art performance across diverse benchmarks, validating that objective alignment is essential for unlocking the full potential of heatmap-based solvers.
Dynamic Self-Attention : Computing Attention over Words Dynamically for Sentence Embedding
Aug 22, 2018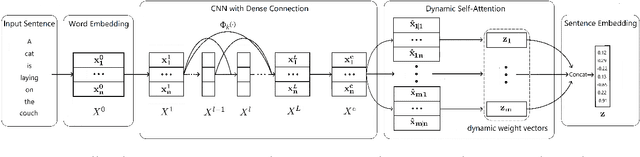
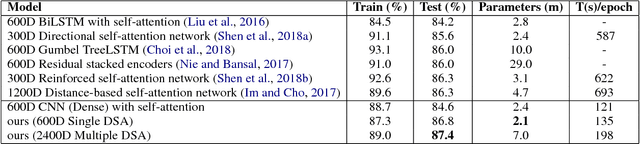

In this paper, we propose Dynamic Self-Attention (DSA), a new self-attention mechanism for sentence embedding. We design DSA by modifying dynamic routing in capsule network (Sabouretal.,2017) for natural language processing. DSA attends to informative words with a dynamic weight vector. We achieve new state-of-the-art results among sentence encoding methods in Stanford Natural Language Inference (SNLI) dataset with the least number of parameters, while showing comparative results in Stanford Sentiment Treebank (SST) dataset.