 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphemeAug: A Systematic Approach to Synthesized Hard Negative Keyword Spotting Examples
May 20, 2025



Spoken Keyword Spotting (KWS) is the task of distinguishing between the presence and absence of a keyword in audio. The accuracy of a KWS model hinges on its ability to correctly classify examples close to the keyword and non-keyword boundary. These boundary examples are often scarce in training data, limiting model performance. In this paper, we propose a method to systematically generate adversarial examples close to the decision boundary by making insertion/deletion/substitution edits on the keyword's graphemes. We evaluate this technique on held-out data for a popular keyword and show that the technique improves AUC on a dataset of synthetic hard negatives by 61% while maintaining quality on positives and ambient negative audio data.
GE2E-KWS: Generalized End-to-End Training and Evaluation for Zero-shot Keyword Spotting
Oct 22, 2024We propose GE2E-KWS -- a generalized end-to-end training and evaluation framework for customized keyword spotting. Specifically, enrollment utterances are separated and grouped by keywords from the training batch and their embedding centroids are compared to all other test utterance embeddings to compute the loss. This simulates runtime enrollment and verification stages, and improves convergence stability and training speed by optimizing matrix operations compared to SOTA triplet loss approaches. To benchmark different models reliably, we propose an evaluation process that mimics the production environment and compute metrics that directly measure keyword matching accuracy. Trained with GE2E loss, our 419KB quantized conformer model beats a 7.5GB ASR encoder by 23.6% relative AUC, and beats a same size triplet loss model by 60.7% AUC. Our KWS models are natively streamable with low memory footprints, and designed to continuously run on-device with no retraining needed for new keywords (zero-shot).
Adversarial training of Keyword Spotting to Minimize TTS Data Overfitting
Aug 20, 2024



The keyword spotting (KWS) problem requires large amounts of real speech training data to achieve high accuracy across diverse populations. Utilizing large amounts of text-to-speech (TTS) synthesized data can reduce the cost and time associated with KWS development. However, TTS data may contain artifacts not present in real speech, which the KWS model can exploit (overfit), leading to degraded accuracy on real speech. To address this issue, we propose applying an adversarial training method to prevent the KWS model from learning TTS-specific features when trained on large amounts of TTS data. Experimental results demonstrate that KWS model accuracy on real speech data can be improved by up to 12% when adversarial loss is used in addition to the original KWS loss. Surprisingly, we also observed that the adversarial setup improves accuracy by up to 8%, even when trained solely on TTS and real negative speech data, without any real positive examples.
Utilizing TTS Synthesized Data for Efficient Development of Keyword Spotting Model
Jul 26, 2024



This paper explores the use of TTS synthesized training data for KWS (keyword spotting) task while minimizing development cost and time. Keyword spotting models require a huge amount of training data to be accurate, and obtaining such training data can be costly. In the current state of the art, TTS models can generate large amounts of natural-sounding data, which can help reducing cost and time for KWS model development. Still, TTS generated data can be lacking diversity compared to real data. To pursue maximizing KWS model accuracy under the constraint of limited resources and current TTS capability, we explored various strategies to mix TTS data and real human speech data, with a focus on minimizing real data use and maximizing diversity of TTS output. Our experimental results indicate that relatively small amounts of real audio data with speaker diversity (100 speakers, 2k utterances) and large amounts of TTS synthesized data can achieve reasonably high accuracy (within 3x error rate of baseline), compared to the baseline (trained with 3.8M real positive utterances).
Synth4Kws: Synthesized Speech for User Defined Keyword Spotting in Low Resource Environments
Jul 23, 2024



One of the challenges in developing a high quality custom keyword spotting (KWS) model is the lengthy and expensive process of collecting training data covering a wide range of languages, phrases and speaking styles. We introduce Synth4Kws - a framework to leverage Text to Speech (TTS) synthesized data for custom KWS in different resource settings. With no real data, we found increasing TTS phrase diversity and utterance sampling monotonically improves model performance, as evaluated by EER and AUC metrics over 11k utterances of the speech command dataset. In low resource settings, with 50k real utterances as a baseline, we found using optimal amounts of TTS data can improve EER by 30.1% and AUC by 46.7%. Furthermore, we mix TTS data with varying amounts of real data and interpolate the real data needed to achieve various quality targets. Our experiments are based on English and single word utterances but the findings generalize to i18n languages and other keyword types.
Locale Encoding For Scalable Multilingual Keyword Spotting Models
Feb 25, 2023



A Multilingual Keyword Spotting (KWS) system detects spokenkeywords over multiple locales. Conventional monolingual KWSapproaches do not scale well to multilingual scenarios because ofhigh development/maintenance costs and lack of resource sharing.To overcome this limit, we propose two locale-conditioned universalmodels with locale feature concatenation and feature-wise linearmodulation (FiLM). We compare these models with two baselinemethods: locale-specific monolingual KWS, and a single universalmodel trained over all data. Experiments over 10 localized languagedatasets show that locale-conditioned models substantially improveaccuracy over baseline methods across all locales in different noiseconditions.FiLMperformed the best, improving on average FRRby 61% (relative) compared to monolingual KWS models of similarsizes.
Production federated keyword spotting via distillation, filtering, and joint federated-centralized training
Apr 11, 2022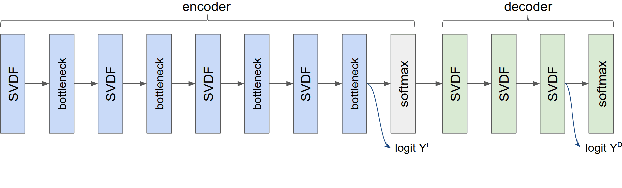
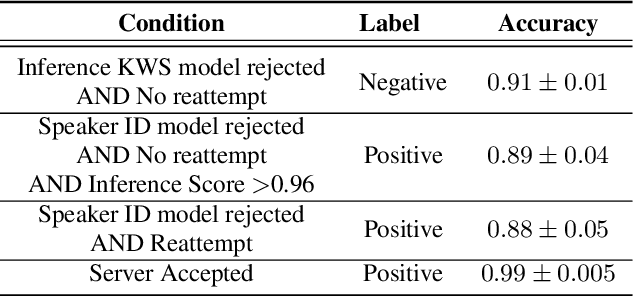
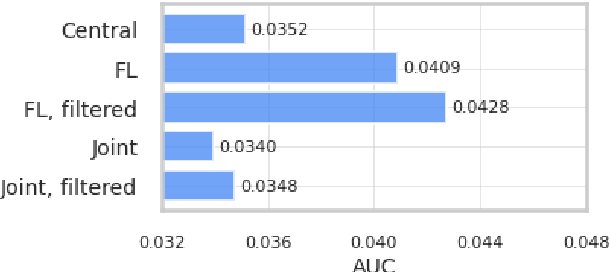

We trained a keyword spotting model using federated learning on real user devices and observed significant improvements when the model was deployed for inference on phones. To compensate for data domains that are missing from on-device training caches, we employed joint federated-centralized training. And to learn in the absence of curated labels on-device, we formulated a confidence filtering strategy based on user-feedback signals for federated distillation. These techniques created models that significantly improved quality metrics in offline evaluations and user-experience metrics in live A/B experiments.