 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInter-subject Contrastive Learning for Subject Adaptive EEG-based Visual Recognition
Feb 07, 2022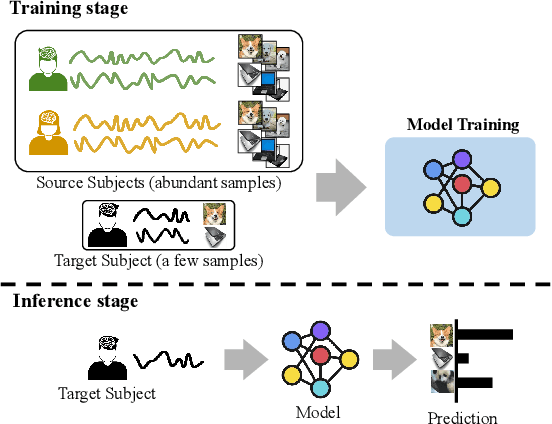
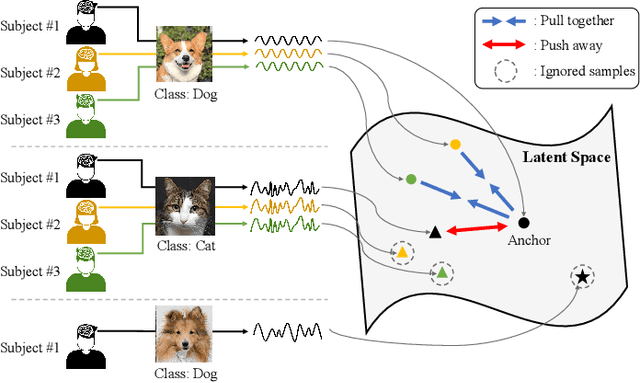
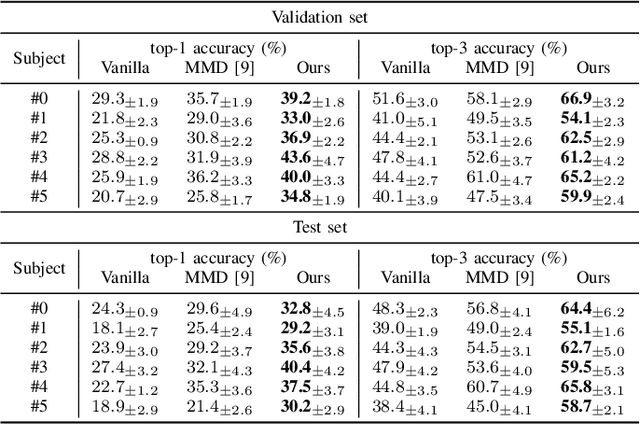
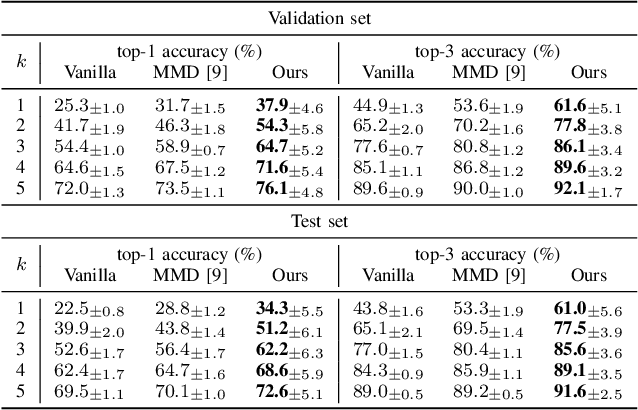
This paper tackles the problem of subject adaptive EEG-based visual recognition. Its goal is to accurately predict the categories of visual stimuli based on EEG signals with only a handful of samples for the target subject during training. The key challenge is how to appropriately transfer the knowledge obtained from abundant data of source subjects to the subject of interest. To this end, we introduce a novel method that allows for learning subject-independent representation by increasing the similarity of features sharing the same class but coming from different subjects. With the dedicated sampling principle, our model effectively captures the common knowledge shared across different subjects, thereby achieving promising performance for the target subject even under harsh problem settings with limited data. Specifically, on the EEG-ImageNet40 benchmark, our model records the top-1 / top-3 test accuracy of 72.6% / 91.6% when using only five EEG samples per class for the target subject. Our code is available at https://github.com/DeepBCI/Deep-BCI/tree/master/1_Intelligent_BCI/Inter_Subject_Contrastive_Learning_for_EEG.
Subject Adaptive EEG-based Visual Recognition
Oct 26, 2021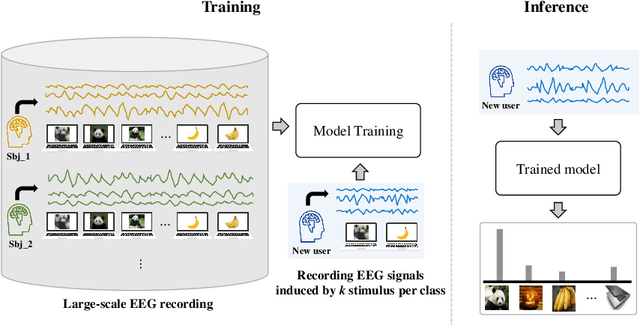
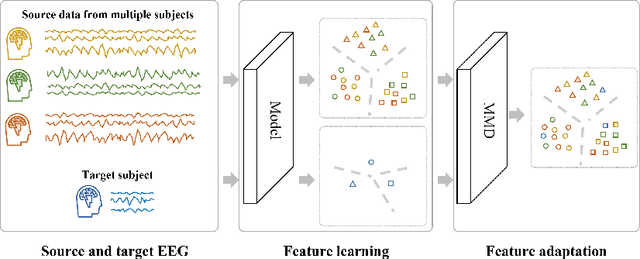
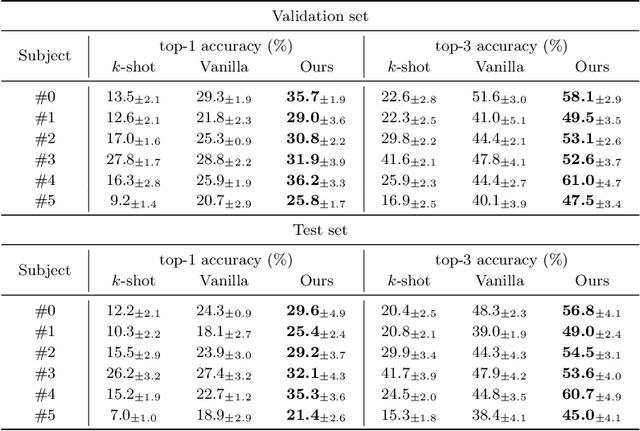
This paper focuses on EEG-based visual recognition, aiming to predict the visual object class observed by a subject based on his/her EEG signals. One of the main challenges is the large variation between signals from different subjects. It limits recognition systems to work only for the subjects involved in model training, which is undesirable for real-world scenarios where new subjects are frequently added. This limitation can be alleviated by collecting a large amount of data for each new user, yet it is costly and sometimes infeasible. To make the task more practical, we introduce a novel problem setting, namely subject adaptive EEG-based visual recognition. In this setting, a bunch of pre-recorded data of existing users (source) is available, while only a little training data from a new user (target) are provided. At inference time, the model is evaluated solely on the signals from the target user. This setting is challenging, especially because training samples from source subjects may not be helpful when evaluating the model on the data from the target subject. To tackle the new problem, we design a simple yet effective baseline that minimizes the discrepancy between feature distributions from different subjects, which allows the model to extract subject-independent features. Consequently, our model can learn the common knowledge shared among subjects, thereby significantly improving the recognition performance for the target subject. In the experiments, we demonstrate the effectiveness of our method under various settings. Our code is available at https://github.com/DeepBCI/Deep-BCI/tree/master/1_Intelligent_BCI/Subject_Adaptive_EEG_based_Visual_Recognition.
Feature Stylization and Domain-aware Contrastive Learning for Domain Generalization
Aug 19, 2021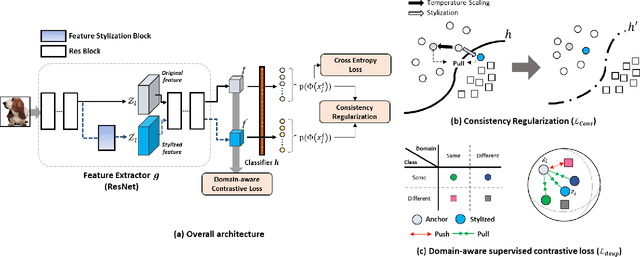
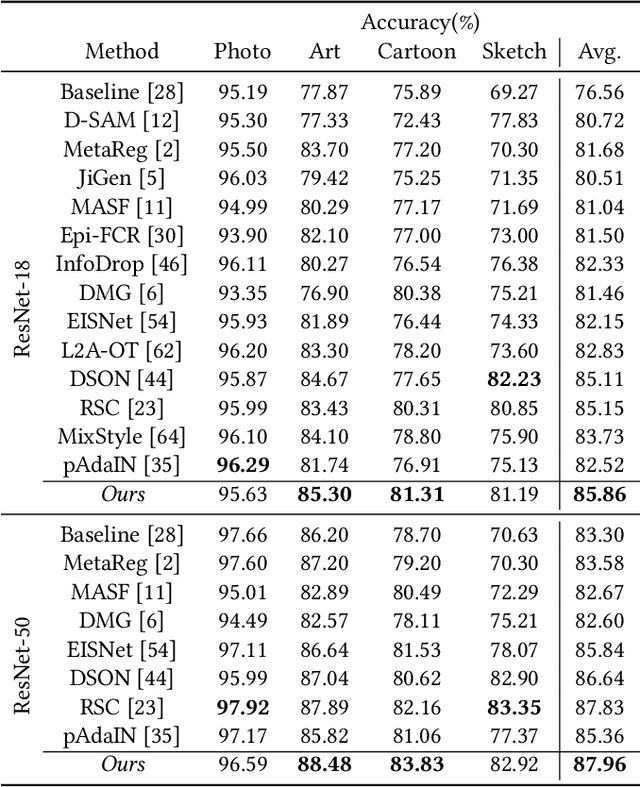
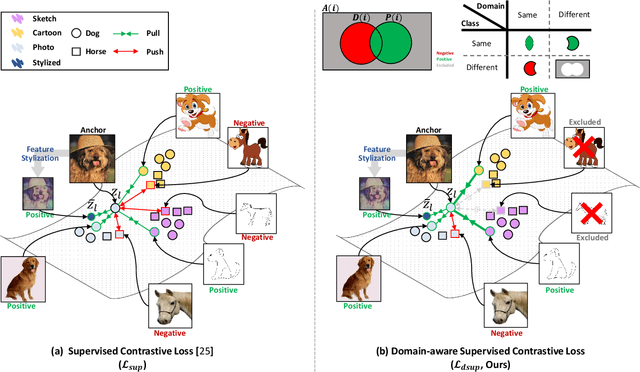
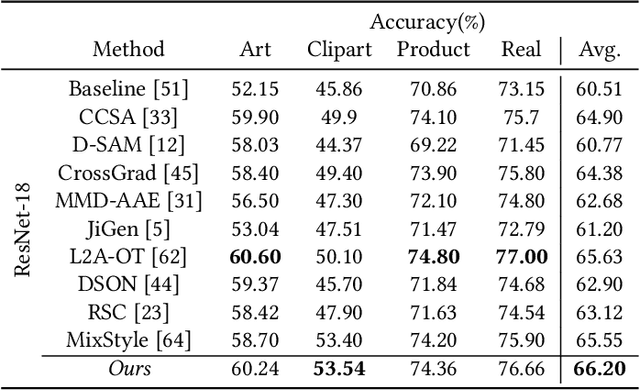
Domain generalization aims to enhance the model robustness against domain shift without accessing the target domain. Since the available source domains for training are limited, recent approaches focus on generating samples of novel domains. Nevertheless, they either struggle with the optimization problem when synthesizing abundant domains or cause the distortion of class semantics. To these ends, we propose a novel domain generalization framework where feature statistics are utilized for stylizing original features to ones with novel domain properties. To preserve class information during stylization, we first decompose features into high and low frequency components. Afterward, we stylize the low frequency components with the novel domain styles sampled from the manipulated statistics, while preserving the shape cues in high frequency ones. As the final step, we re-merge both components to synthesize novel domain features. To enhance domain robustness, we utilize the stylized features to maintain the model consistency in terms of features as well as outputs. We achieve the feature consistency with the proposed domain-aware supervised contrastive loss, which ensures domain invariance while increasing class discriminability. Experimental results demonstrate the effectiveness of the proposed feature stylization and the domain-aware contrastive loss. Through quantitative comparisons, we verify the lead of our method upon existing state-of-the-art methods on two benchmarks, PACS and Office-Home.
Domain-Aware Universal Style Transfer
Aug 17, 2021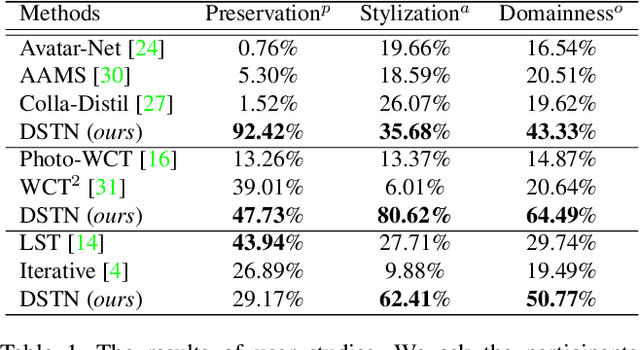
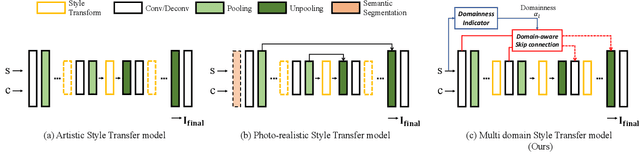
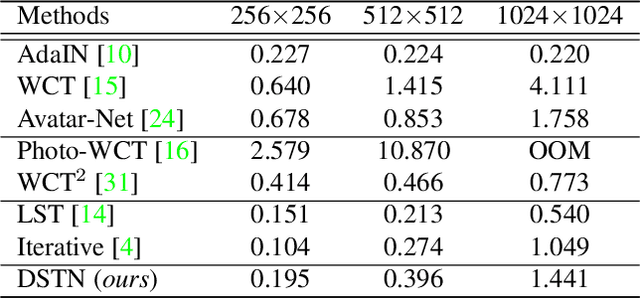
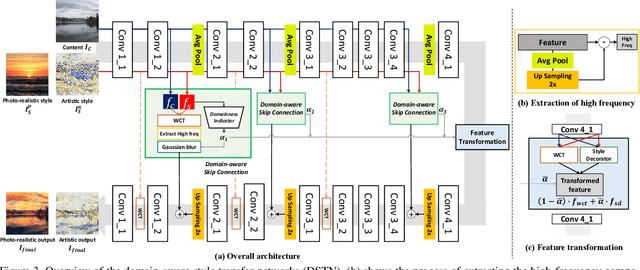
Style transfer aims to reproduce content images with the styles from reference images. Existing universal style transfer methods successfully deliver arbitrary styles to original images either in an artistic or a photo-realistic way. However, the range of 'arbitrary style' defined by existing works is bounded in the particular domain due to their structural limitation. Specifically, the degrees of content preservation and stylization are established according to a predefined target domain. As a result, both photo-realistic and artistic models have difficulty in performing the desired style transfer for the other domain. To overcome this limitation, we propose a unified architecture, Domain-aware Style Transfer Networks (DSTN) that transfer not only the style but also the property of domain (i.e., domainness) from a given reference image. To this end, we design a novel domainness indicator that captures the domainness value from the texture and structural features of reference images. Moreover, we introduce a unified framework with domain-aware skip connection to adaptively transfer the stroke and palette to the input contents guided by the domainness indicator. Our extensive experiments validate that our model produces better qualitative results and outperforms previous methods in terms of proxy metrics on both artistic and photo-realistic stylizations.
Learning Action Completeness from Points for Weakly-supervised Temporal Action Localization
Aug 11, 2021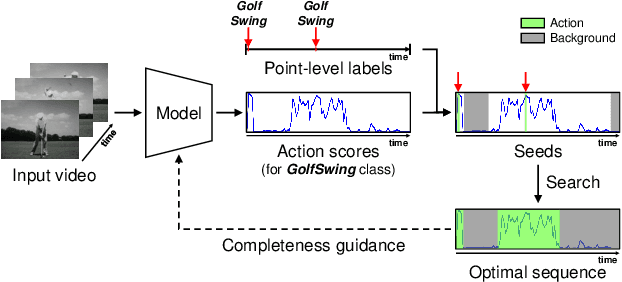
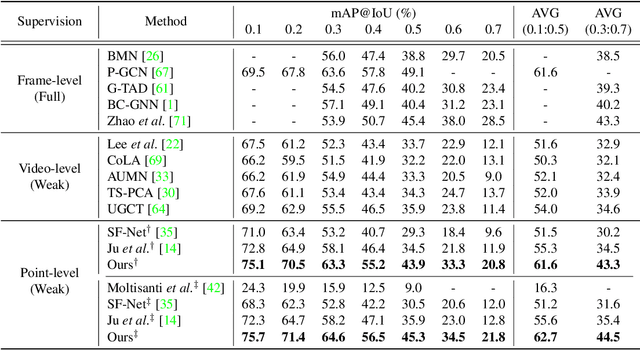
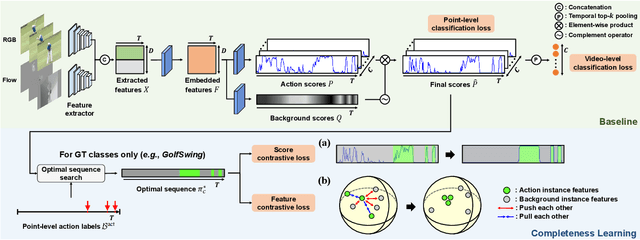
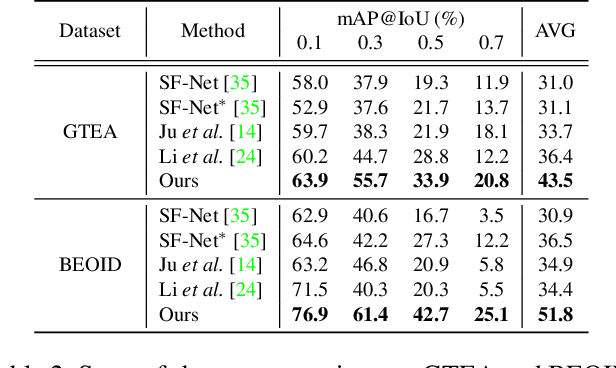
We tackle the problem of localizing temporal intervals of actions with only a single frame label for each action instance for training. Owing to label sparsity, existing work fails to learn action completeness, resulting in fragmentary action predictions. In this paper, we propose a novel framework, where dense pseudo-labels are generated to provide completeness guidance for the model. Concretely, we first select pseudo background points to supplement point-level action labels. Then, by taking the points as seeds, we search for the optimal sequence that is likely to contain complete action instances while agreeing with the seeds. To learn completeness from the obtained sequence, we introduce two novel losses that contrast action instances with background ones in terms of action score and feature similarity, respectively. Experimental results demonstrate that our completeness guidance indeed helps the model to locate complete action instances, leading to large performance gains especially under high IoU thresholds. Moreover, we demonstrate the superiority of our method over existing state-of-the-art methods on four benchmarks: THUMOS'14, GTEA, BEOID, and ActivityNet. Notably, our method even performs comparably to recent fully-supervised methods, at the 6 times cheaper annotation cost. Our code is available at https://github.com/Pilhyeon.
Continuous Face Aging Generative Adversarial Networks
Feb 26, 2021
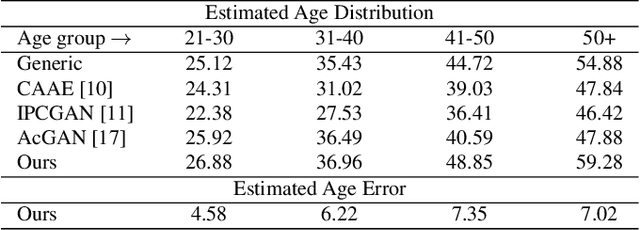
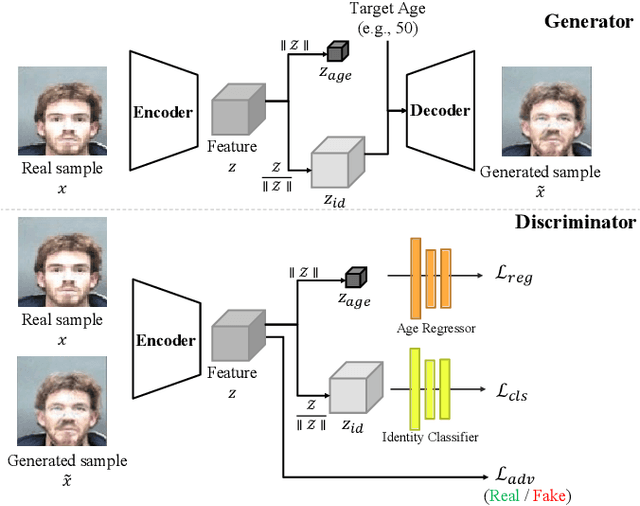
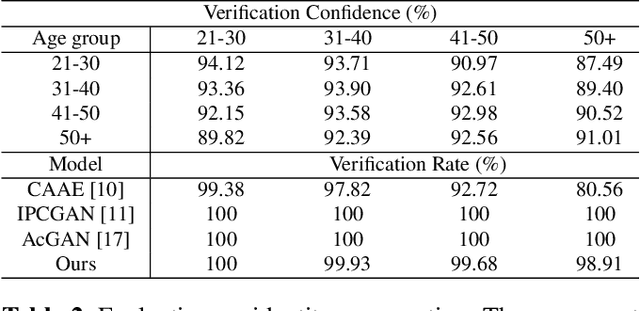
Face aging is the task aiming to translate the faces in input images to designated ages. To simplify the problem, previous methods have limited themselves only able to produce discrete age groups, each of which consists of ten years. Consequently, the exact ages of the translated results are unknown and it is unable to obtain the faces of different ages within groups. To this end, we propose the continuous face aging generative adversarial networks (CFA-GAN). Specifically, to make the continuous aging feasible, we propose to decompose image features into two orthogonal features: the identity and the age basis features. Moreover, we introduce the novel loss function for identity preservation which maximizes the cosine similarity between the original and the generated identity basis features. With the qualitative and quantitative evaluations on MORPH, we demonstrate the realistic and continuous aging ability of our model, validating its superiority against existing models. To the best of our knowledge, this work is the first attempt to handle continuous target ages.
ArrowGAN : Learning to Generate Videos by Learning Arrow of Time
Jan 11, 2021

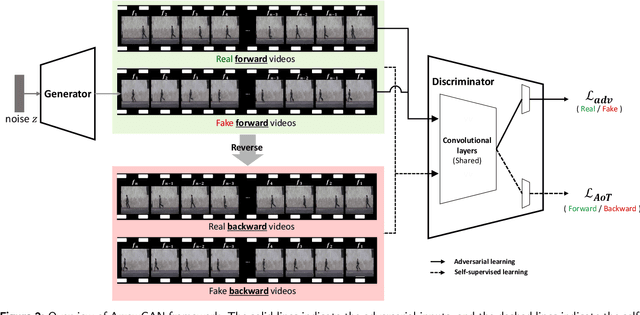

Training GANs on videos is even more sophisticated than on images because videos have a distinguished dimension: time. While recent methods designed a dedicated architecture considering time, generated videos are still far from indistinguishable from real videos. In this paper, we introduce ArrowGAN framework, where the discriminators learns to classify arrow of time as an auxiliary task and the generators tries to synthesize forward-running videos. We argue that the auxiliary task should be carefully chosen regarding the target domain. In addition, we explore categorical ArrowGAN with recent techniques in conditional image generation upon ArrowGAN framework, achieving the state-of-the-art performance on categorical video generation. Our extensive experiments validate the effectiveness of arrow of time as a self-supervisory task, and demonstrate that all our components of categorical ArrowGAN lead to the improvement regarding video inception score and Frechet video distance on three datasets: Weizmann, UCFsports, and UCF-101.
FairFaceGAN: Fairness-aware Facial Image-to-Image Translation
Dec 02, 2020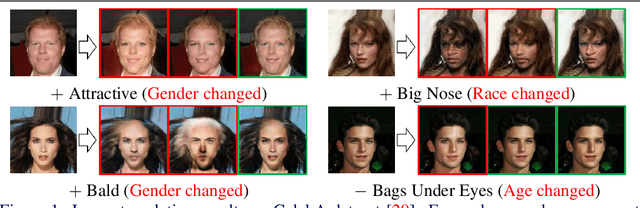

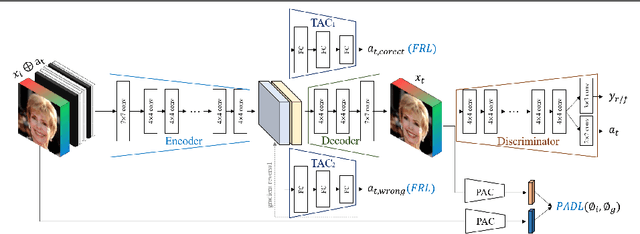
In this paper, we introduce FairFaceGAN, a fairness-aware facial Image-to-Image translation model, mitigating the problem of unwanted translation in protected attributes (e.g., gender, age, race) during facial attributes editing. Unlike existing models, FairFaceGAN learns fair representations with two separate latents - one related to the target attributes to translate, and the other unrelated to them. This strategy enables FairFaceGAN to separate the information about protected attributes and that of target attributes. It also prevents unwanted translation in protected attributes while target attributes editing. To evaluate the degree of fairness, we perform two types of experiments on CelebA dataset. First, we compare the fairness-aware classification performances when augmenting data by existing image translation methods and FairFaceGAN respectively. Moreover, we propose a new fairness metric, namely Frechet Protected Attribute Distance (FPAD), which measures how well protected attributes are preserved. Experimental results demonstrate that FairFaceGAN shows consistent improvements in terms of fairness over the existing image translation models. Further, we also evaluate image translation performances, where FairFaceGAN shows competitive results, compared to those of existing methods.
In-sample Contrastive Learning and Consistent Attention for Weakly Supervised Object Localization
Sep 25, 2020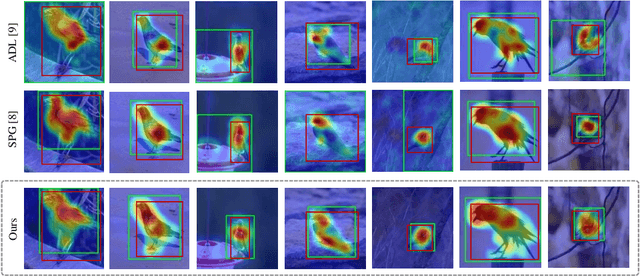
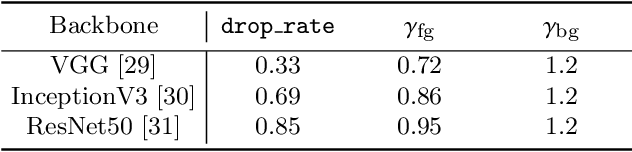
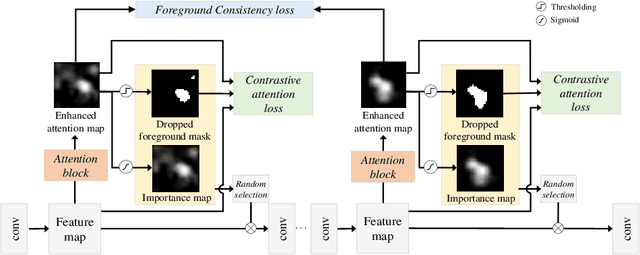
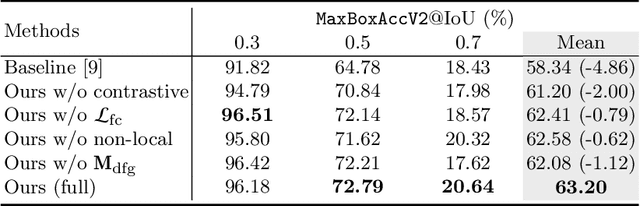
Weakly supervised object localization (WSOL) aims to localize the target object using only the image-level supervision. Recent methods encourage the model to activate feature maps over the entire object by dropping the most discriminative parts. However, they are likely to induce excessive extension to the backgrounds which leads to over-estimated localization. In this paper, we consider the background as an important cue that guides the feature activation to cover the sophisticated object region and propose contrastive attention loss. The loss promotes similarity between foreground and its dropped version, and, dissimilarity between the dropped version and background. Furthermore, we propose foreground consistency loss that penalizes earlier layers producing noisy attention regarding the later layer as a reference to provide them with a sense of backgroundness. It guides the early layers to activate on objects rather than locally distinctive backgrounds so that their attentions to be similar to the later layer. For better optimizing the above losses, we use the non-local attention blocks to replace channel-pooled attention leading to enhanced attention maps considering the spatial similarity. Last but not least, we propose to drop background regions in addition to the most discriminative region. Our method achieves state-of-theart performance on CUB-200-2011 and ImageNet benchmark datasets regarding top-1 localization accuracy and MaxBoxAccV2, and we provide detailed analysis on our individual components. The code will be publicly available online for reproducibility.
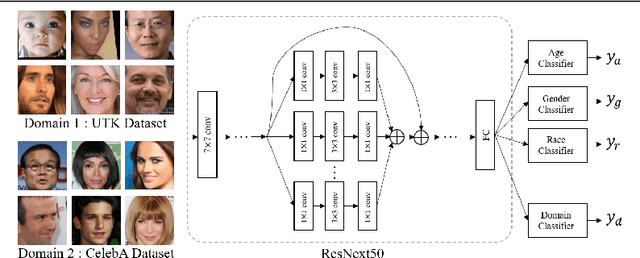
README: REpresentation learning by fairness-Aware Disentangling MEthod
Jul 07, 2020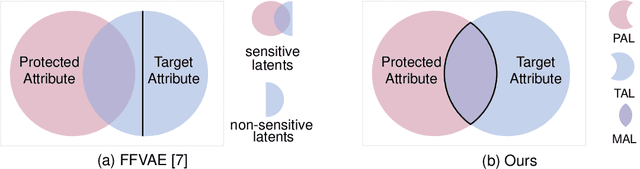

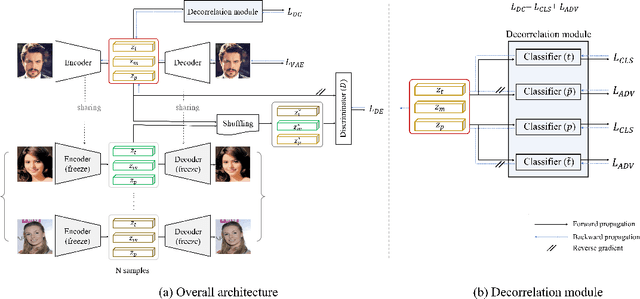
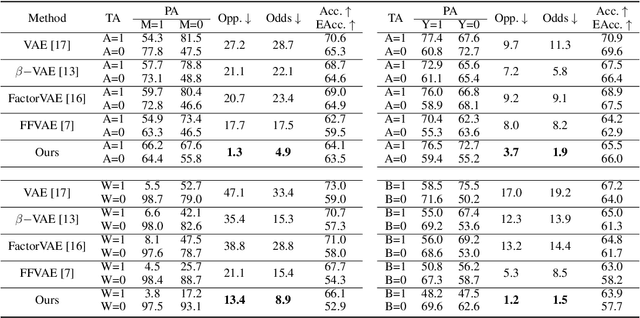
Fair representation learning aims to encode invariant representation with respect to the protected attribute, such as gender or age. In this paper, we design Fairness-aware Disentangling Variational AutoEncoder (FD-VAE) for fair representation learning. This network disentangles latent space into three subspaces with a decorrelation loss that encourages each subspace to contain independent information: 1) target attribute information, 2) protected attribute information, 3) mutual attribute information. After the representation learning, this disentangled representation is leveraged for fairer downstream classification by excluding the subspace with the protected attribute information. We demonstrate the effectiveness of our model through extensive experiments on CelebA and UTK Face datasets. Our method outperforms the previous state-of-the-art method by large margins in terms of equal opportunity and equalized odds.