 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSERT-RoLL: Robust Multi-Modal Perception for Diverse Driving Conditions with Stereo Event-RGB-Thermal Cameras, 4D Radar, and Dual-LiDAR
Apr 04, 2026In this paper, we present DSERT-RoLL, a driving dataset that incorporates stereo event, RGB, and thermal cameras together with 4D radar and dual LiDAR, collected across diverse weather and illumination conditions. The dataset provides precise 2D and 3D bounding boxes with track IDs and ego vehicle odometry, enabling fair comparisons within and across sensor combinations. It is designed to alleviate data scarcity for novel sensors such as event cameras and 4D radar and to support systematic studies of their behavior. We establish unified 3D and 2D benchmarks that enable direct comparison of characteristics and strengths across sensor families and within each family. We report baselines for representative single modality and multimodal methods and provide protocols that encourage research on different fusion strategies and sensor combinations. In addition, we propose a fusion framework that integrates sensor specific cues into a unified feature space and improves 3D detection robustness under varied weather and lighting.
Label-Free Cross-Task LoRA Merging with Null-Space Compression
Mar 27, 2026Model merging combines independently fine-tuned checkpoints without joint multi-task training. In the era of foundation-model, fine-tuning with Low-Rank Adaptation (LoRA) is prevalent, making LoRA merging a promising target. Existing approaches can work in homogeneous settings where all target tasks are classification but often fail when tasks span classification and regression. Approaches using entropy-based surrogates do not apply to regression and are costly for large language models due to long token sequences. We introduce Null-Space Compression (NSC) Merging, a label-free, output-agnostic method that sets merge weights from adapter geometry. Our key observation is that during LoRA finetuning the down-projection factor $A$ in $ΔW = BA$ compresses its null space, and the compression correlates with performance. NSC uses this as an optimization signal for merging that can generalize across classification, regression, and sequence generation. NSC achieves state-of-the-art performance across twenty heterogeneous vision tasks with balanced gains where prior methods overfit subsets of tasks. It also outperforms baselines on six NLI benchmarks and on vision-language evaluations for VQA and image captioning, demonstrating scalability and effectiveness.
Preference-Aligned LoRA Merging: Preserving Subspace Coverage and Addressing Directional Anisotropy
Mar 27, 2026Merging multiple Low-Rank Adaptation (LoRA) modules is promising for constructing general-purpose systems, yet challenging because LoRA update directions span different subspaces and contribute unevenly. When merged naively, such mismatches can weaken the directions most critical to certain task losses while overemphasizing relatively less important ones, ultimately reducing the model's ability to represent all tasks faithfully. We revisit this problem through two perspectives: subspace coverage, which captures how broadly LoRA directions cover diverse representational directions, and anisotropy, which reflects the imbalance of influence across those directions. We propose TARA-Merging (Task-Rank Anisotropy Alignment), which aligns merging weights using a preference-weighted cross-entropy pseudo-loss while preserving task-relevant LoRA subspaces. This ensures broad subspace coverage and mitigates anisotropy via direction-wise reweighting. Across eight vision and six NLI benchmarks, TARA-Merging consistently outperforms vanilla and LoRA-aware baselines, demonstrating strong robustness and generalization, and highlighting the importance of addressing both subspace coverage and anisotropy in LoRA merging.
Exploiting Shape Cues for Weakly Supervised Semantic Segmentation
Aug 08, 2022
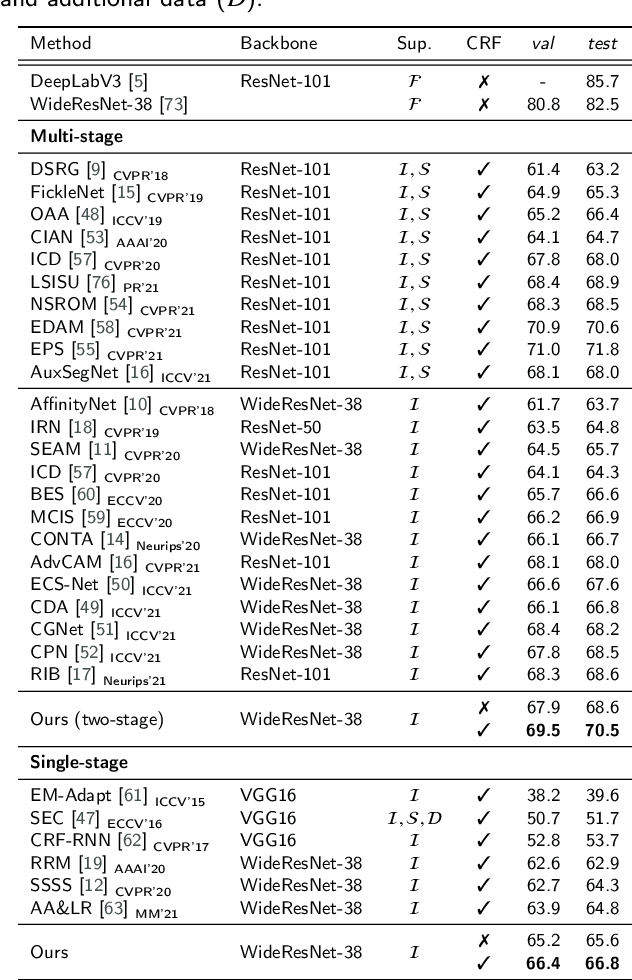
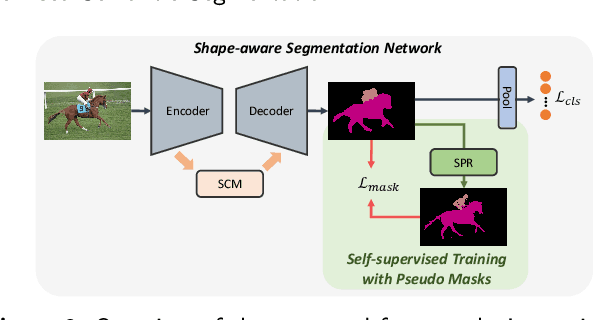
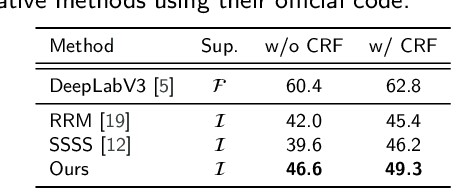
Weakly supervised semantic segmentation (WSSS) aims to produce pixel-wise class predictions with only image-level labels for training. To this end, previous methods adopt the common pipeline: they generate pseudo masks from class activation maps (CAMs) and use such masks to supervise segmentation networks. However, it is challenging to derive comprehensive pseudo masks that cover the whole extent of objects due to the local property of CAMs, i.e., they tend to focus solely on small discriminative object parts. In this paper, we associate the locality of CAMs with the texture-biased property of convolutional neural networks (CNNs). Accordingly, we propose to exploit shape information to supplement the texture-biased CNN features, thereby encouraging mask predictions to be not only comprehensive but also well-aligned with object boundaries. We further refine the predictions in an online fashion with a novel refinement method that takes into account both the class and the color affinities, in order to generate reliable pseudo masks to supervise the model. Importantly, our model is end-to-end trained within a single-stage framework and therefore efficient in terms of the training cost. Through extensive experiments on PASCAL VOC 2012, we validate the effectiveness of our method in producing precise and shape-aligned segmentation results. Specifically, our model surpasses the existing state-of-the-art single-stage approaches by large margins. What is more, it also achieves a new state-of-the-art performance over multi-stage approaches, when adopted in a simple two-stage pipeline without bells and whistles.
* Accepted by Pattern Recognition. The first two authors contributed equally
In-sample Contrastive Learning and Consistent Attention for Weakly Supervised Object Localization
Sep 25, 2020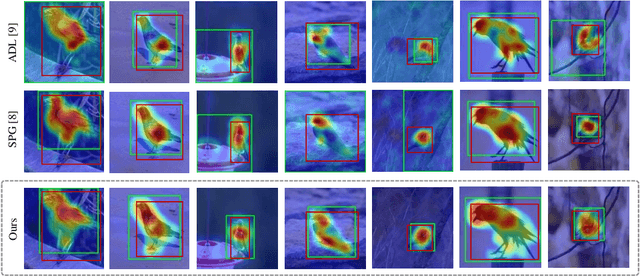
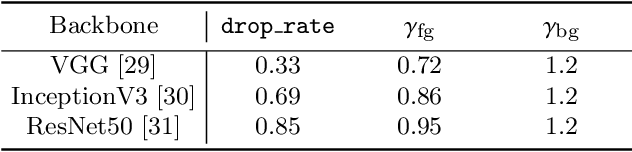
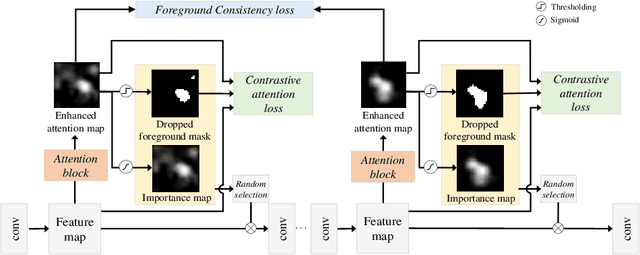
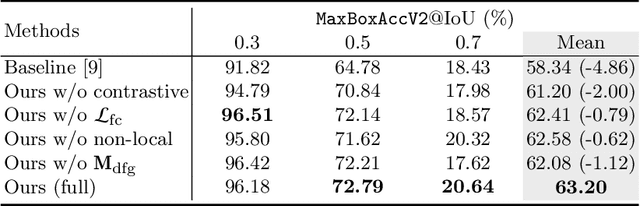
Weakly supervised object localization (WSOL) aims to localize the target object using only the image-level supervision. Recent methods encourage the model to activate feature maps over the entire object by dropping the most discriminative parts. However, they are likely to induce excessive extension to the backgrounds which leads to over-estimated localization. In this paper, we consider the background as an important cue that guides the feature activation to cover the sophisticated object region and propose contrastive attention loss. The loss promotes similarity between foreground and its dropped version, and, dissimilarity between the dropped version and background. Furthermore, we propose foreground consistency loss that penalizes earlier layers producing noisy attention regarding the later layer as a reference to provide them with a sense of backgroundness. It guides the early layers to activate on objects rather than locally distinctive backgrounds so that their attentions to be similar to the later layer. For better optimizing the above losses, we use the non-local attention blocks to replace channel-pooled attention leading to enhanced attention maps considering the spatial similarity. Last but not least, we propose to drop background regions in addition to the most discriminative region. Our method achieves state-of-theart performance on CUB-200-2011 and ImageNet benchmark datasets regarding top-1 localization accuracy and MaxBoxAccV2, and we provide detailed analysis on our individual components. The code will be publicly available online for reproducibility.