 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Feature Aggregating and Hashing for Compact Binary Code Learning
Apr 24, 2019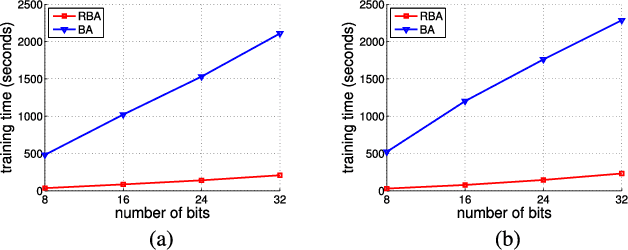
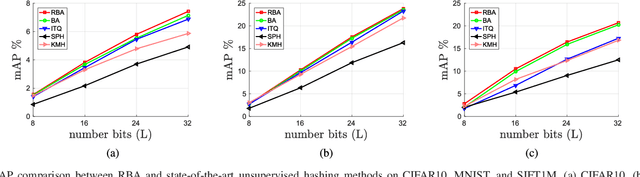
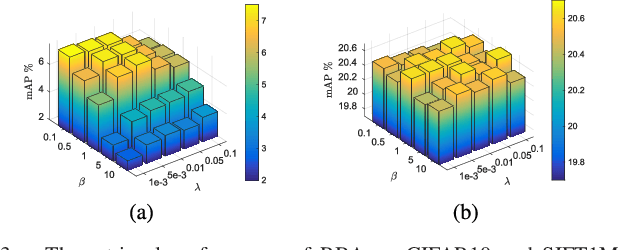
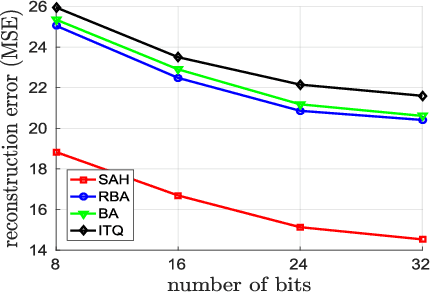
Representing images by compact hash codes is an attractive approach for large-scale content-based image retrieval. In most state-of-the-art hashing-based image retrieval systems, for each image, local descriptors are first aggregated as a global representation vector. This global vector is then subjected to a hashing function to generate a binary hash code. In previous works, the aggregating and the hashing processes are designed independently. Hence these frameworks may generate suboptimal hash codes. In this paper, we first propose a novel unsupervised hashing framework in which feature aggregating and hashing are designed simultaneously and optimized jointly. Specifically, our joint optimization generates aggregated representations that can be better reconstructed by some binary codes. This leads to more discriminative binary hash codes and improved retrieval accuracy. In addition, the proposed method is flexible. It can be extended for supervised hashing. When the data label is available, the framework can be adapted to learn binary codes which minimize the reconstruction loss w.r.t. label vectors. Furthermore, we also propose a fast version of the state-of-the-art hashing method Binary Autoencoder to be used in our proposed frameworks. Extensive experiments on benchmark datasets under various settings show that the proposed methods outperform state-of-the-art unsupervised and supervised hashing methods.
SDRSAC: Semidefinite-Based Randomized Approach for Robust Point Cloud Registration without Correspondences
Apr 14, 2019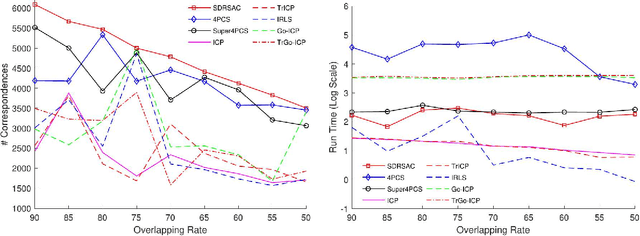
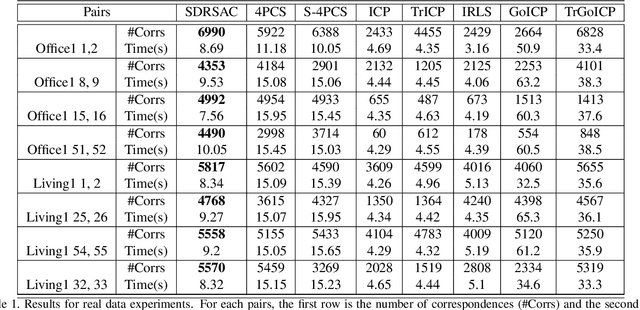
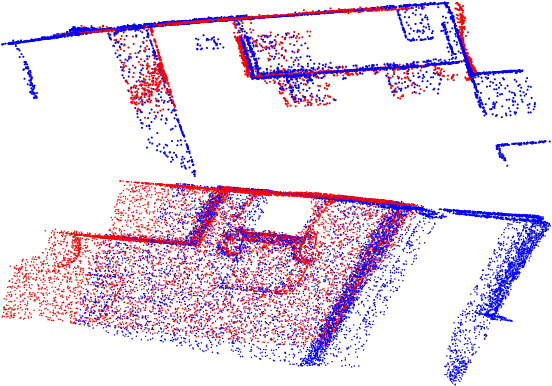
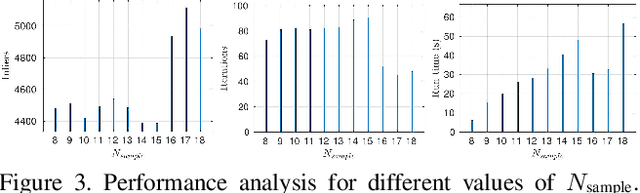
This paper presents a novel randomized algorithm for robust point cloud registration without correspondences. Most existing registration approaches require a set of putative correspondences obtained by extracting invariant descriptors. However, such descriptors could become unreliable in noisy and contaminated settings. In these settings, methods that directly handle input point sets are preferable. Without correspondences, however, conventional randomized techniques require a very large number of samples in order to reach satisfactory solutions. In this paper, we propose a novel approach to address this problem. In particular, our work enables the use of randomized methods for point cloud registration without the need of putative correspondences. By considering point cloud alignment as a special instance of graph matching and employing an efficient semi-definite relaxation, we propose a novel sampling mechanism, in which the size of the sampled subsets can be larger-than-minimal. Our tight relaxation scheme enables fast rejection of the outliers in the sampled sets, resulting in high-quality hypotheses. We conduct extensive experiments to demonstrate that our approach outperforms other state-of-the-art methods. Importantly, our proposed method serves as a generic framework which can be extended to problems with known correspondences.
SASSE: Scalable and Adaptable 6-DOF Pose Estimation
Feb 05, 2019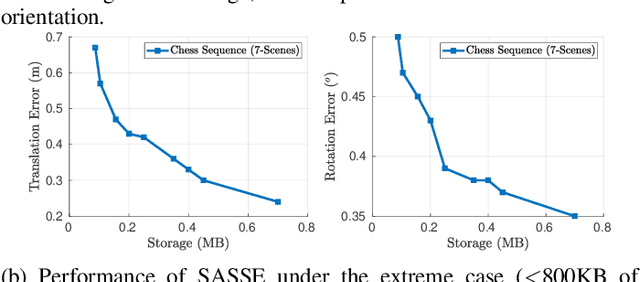
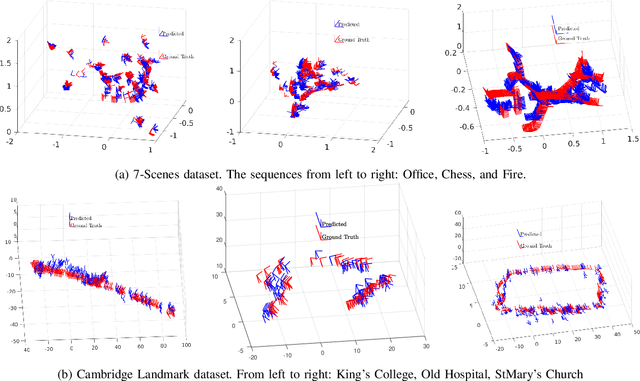
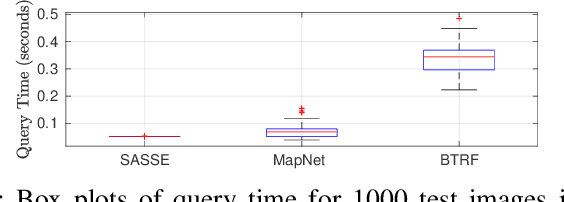

Visual localization has become a key enabling component of many place recognition and SLAM systems. Contemporary research has primarily focused on improving accuracy and precision-recall type metrics, with relatively little attention paid to a system's absolute storage scaling characteristics, its flexibility to adapt to available computational resources, and its longevity with respect to easily incorporating newly learned or hand-crafted image descriptors. Most significantly, improvement in one of these aspects typically comes at the cost of others: for example, a snapshot-based system that achieves sub-linear storage cost typically provides no metric pose estimation, or, a highly accurate pose estimation technique is often ossified in adapting to recent advances in appearance-invariant features. In this paper, we present a novel 6-DOF localization system that for the first time simultaneously achieves all the three characteristics: significantly sub-linear storage growth, agnosticism to image descriptors, and customizability to available storage and computational resources. The key features of our method are developed based on a novel adaptation of multiple-label learning, together with effective dimensional reduction and learning techniques that enable simple and efficient optimization. We evaluate our system on several large benchmarking datasets and provide detailed comparisons to state-of-the-art systems. The proposed method demonstrates competitive accuracy with existing pose estimation methods while achieving better sub-linear storage scaling, significantly reduced absolute storage requirements, and faster training and deployment speeds.
A Binary Optimization Approach for Constrained K-Means Clustering
Oct 29, 2018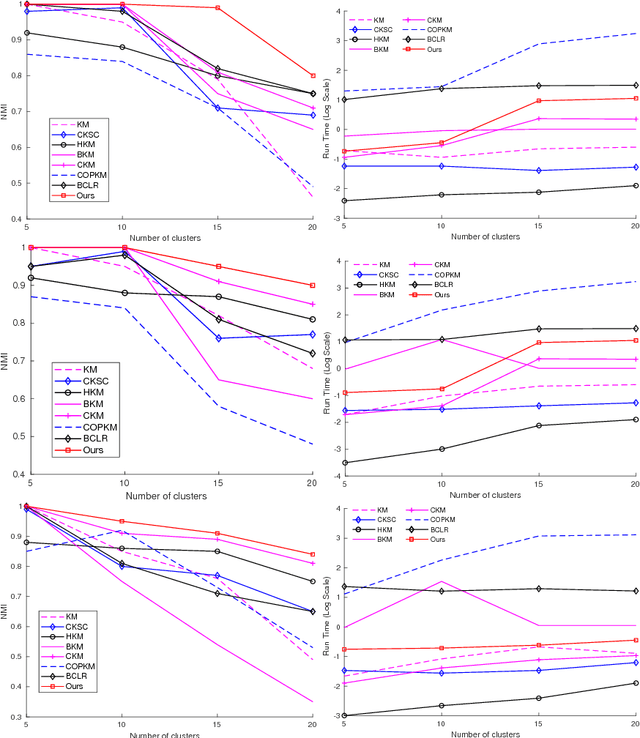
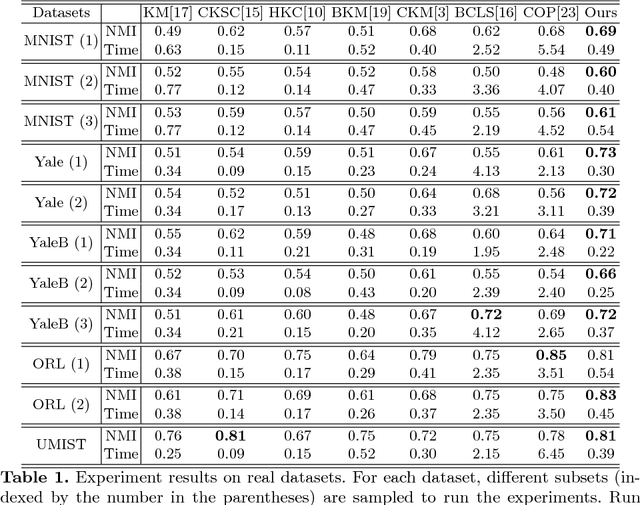
K-Means clustering still plays an important role in many computer vision problems. While the conventional Lloyd method, which alternates between centroid update and cluster assignment, is primarily used in practice, it may converge to a solution with empty clusters. Furthermore, some applications may require the clusters to satisfy a specific set of constraints, e.g., cluster sizes, must-link/cannot-link. Several methods have been introduced to solve constrained K-Means clustering. Due to the non-convex nature of K-Means, however, existing approaches may result in sub-optimal solutions that poorly approximate the true clusters. In this work, we provide a new perspective to tackle this problem. Particularly, we reconsider constrained K-Means as a Binary Optimization Problem and propose a novel optimization scheme to search for feasible solutions in the binary domain. This approach allows us to solve constrained K-Means where multiple types of constraints can be simultaneously enforced. Experimental results on synthetic and real datasets show that our method provides better clustering accuracy with faster runtime compared to several commonly used techniques.
Large scale visual place recognition with sub-linear storage growth
Oct 23, 2018

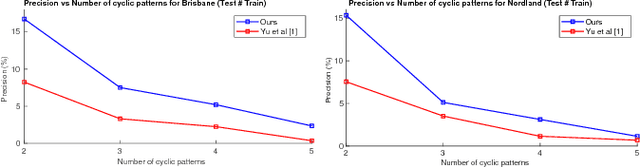
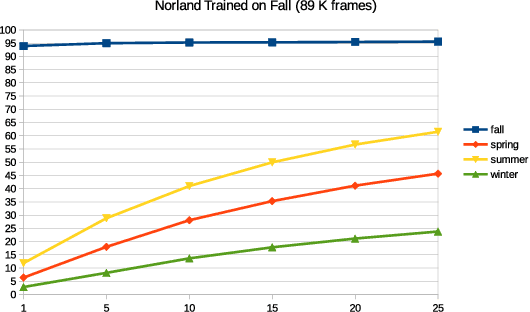
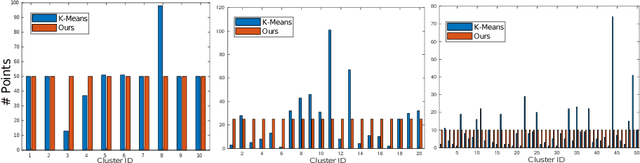
Robotic and animal mapping systems share many of the same objectives and challenges, but differ in one key aspect: where much of the research in robotic mapping has focused on solving the data association problem, the grid cell neurons underlying maps in the mammalian brain appear to intentionally break data association by encoding many locations with a single grid cell neuron. One potential benefit of this intentional aliasing is both sub-linear map storage and computational requirements growth with environment size, which we demonstrated in a previous proof-of-concept study that detected and encoded mutually complementary co-prime pattern frequencies in the visual map data. In this research, we solve several of the key theoretical and practical limitations of that prototype model and achieve significantly better sub-linear storage growth, a factor reduction in storage requirements per map location, scalability to large datasets on standard compute equipment and improved robustness to environments with visually challenging appearance change. These improvements are achieved through several innovations including a flexible user-driven choice mechanism for the periodic patterns underlying the new encoding method, a parallelized chunking technique that splits the map into sub-sections processed in parallel and a novel feature selection approach that selects only the image information most relevant to the encoded temporal patterns. We evaluate our techniques on two large benchmark datasets with the comparison to the previous state-of-the-art system, as well as providing a detailed analysis of system performance with respect to parameters such as required precision performance and the number of cyclic patterns encoded.
Deterministic Approximate Methods for Maximum Consensus Robust Fitting
Oct 23, 2018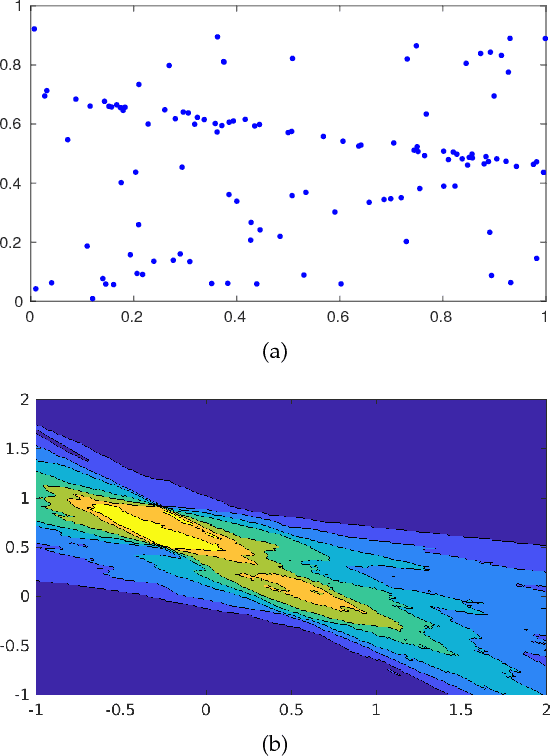
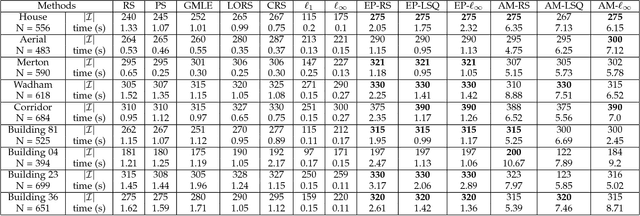

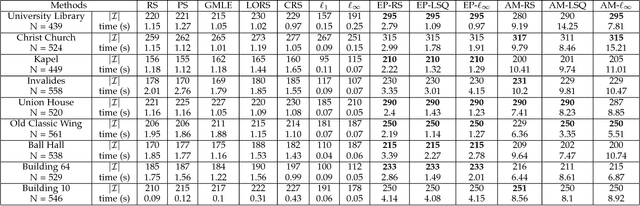
Maximum consensus estimation plays a critically important role in robust fitting problems in computer vision. Currently, the most prevalent algorithms for consensus maximization draw from the class of randomized hypothesize-and-verify algorithms, which are cheap but can usually deliver only rough approximate solutions. On the other extreme, there are exact algorithms which are exhaustive search in nature and can be costly for practical-sized inputs. This paper fills the gap between the two extremes by proposing deterministic algorithms to approximately optimize the maximum consensus criterion. Our work begins by reformulating consensus maximization with linear complementarity constraints. Then, we develop two novel algorithms: one based on non-smooth penalty method with a Frank-Wolfe style optimization scheme, the other based on the Alternating Direction Method of Multipliers (ADMM). Both algorithms solve convex subproblems to efficiently perform the optimization. We demonstrate the capability of our algorithms to greatly improve a rough initial estimate, such as those obtained using least squares or a randomized algorithm. Compared to the exact algorithms, our approach is much more practical on realistic input sizes. Further, our approach is naturally applicable to estimation problems with geometric residuals
Deterministic consensus maximization with biconvex programming
Aug 28, 2018
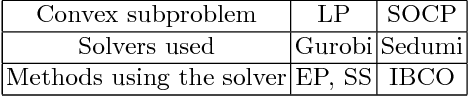
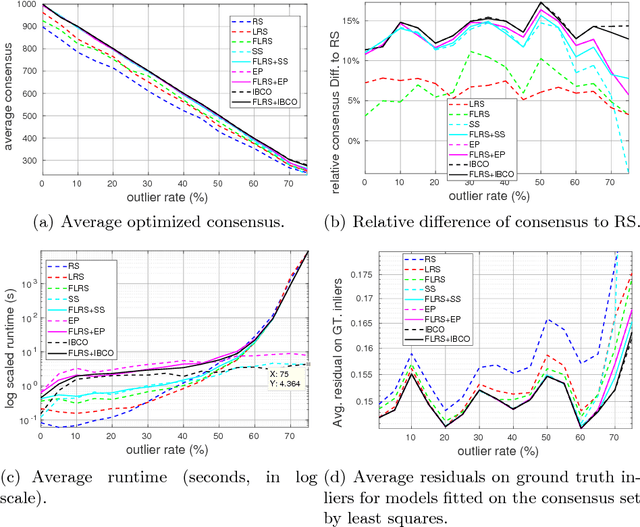

Consensus maximization is one of the most widely used robust fitting paradigms in computer vision, and the development of algorithms for consensus maximization is an active research topic. In this paper, we propose an efficient deterministic optimization algorithm for consensus maximization. Given an initial solution, our method conducts a deterministic search that forcibly increases the consensus of the initial solution. We show how each iteration of the update can be formulated as an instance of biconvex programming, which we solve efficiently using a novel biconvex optimization algorithm. In contrast to our algorithm, previous consensus improvement techniques rely on random sampling or relaxations of the objective function, which reduce their ability to significantly improve the initial consensus. In fact, on challenging instances, the previous techniques may even return a worse off solution. Comprehensive experiments show that our algorithm can consistently and greatly improve the quality of the initial solution, without substantial cost.
Binary Constrained Deep Hashing Network for Image Retrieval without Manual Annotation
Aug 02, 2018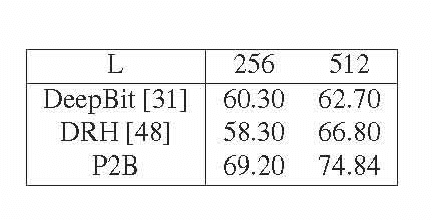
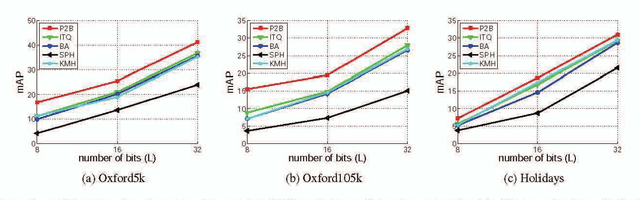
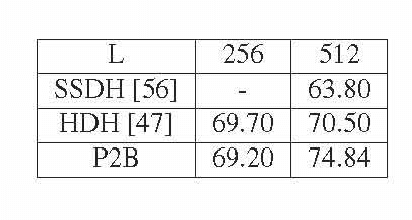
Learning compact binary codes for image retrieval problem using deep neural networks has attracted increasing attention recently. However, training deep hashing networks is challenging due to the binary constraints on the hash codes, the similarity preserving property, and the requirement for a vast amount of labelled images. To the best of our knowledge, none of the existing methods has tackled all of these challenges completely in a unified framework. In this work, we propose a novel end-to-end deep hashing approach, which is trained to produce binary codes directly from image pixels without the need of manual annotation. In particular, we propose a novel pairwise binary constrained loss function, which simultaneously encodes the distances between pairs of hash codes, and the binary quantization error. In order to train the network with the proposed loss function, we also propose an efficient parameter learning algorithm. In addition, to provide similar/dissimilar training images to train the network, we exploit 3D models reconstructed from unlabelled images for automatic generation of enormous similar/dissimilar pairs. Extensive experiments on three image retrieval benchmark datasets demonstrate the superior performance of the proposed method over the state-of-the-art hashing methods on the image retrieval problem.
From Selective Deep Convolutional Features to Compact Binary Representations for Image Retrieval
Jul 20, 2018

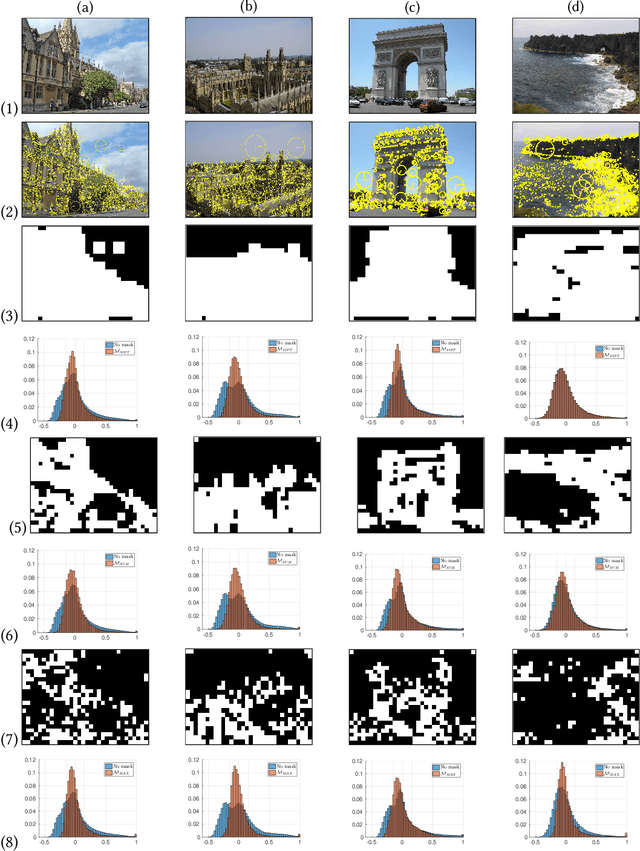

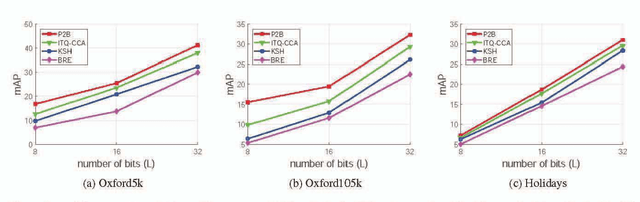
In the large-scale image retrieval task, the two most important requirements are the discriminability of image representations and the efficiency in computation and storage of representations. Regarding the former requirement, Convolutional Neural Network (CNN) is proven to be a very powerful tool to extract highly discriminative local descriptors for effective image search. Additionally, in order to further improve the discriminative power of the descriptors, recent works adopt fine-tuned strategies. In this paper, taking a different approach, we propose a novel, computationally efficient, and competitive framework. Specifically, we firstly propose various strategies to compute masks, namely SIFT-mask, SUM-mask, and MAX-mask, to select a representative subset of local convolutional features and eliminate redundant features. Our in-depth analyses demonstrate that proposed masking schemes are effective to address the burstiness drawback and improve retrieval accuracy. Secondly, we propose to employ recent embedding and aggregating methods which can significantly boost the feature discriminability. Regarding the computation and storage efficiency, we include a hashing module to produce very compact binary image representations. Extensive experiments on six image retrieval benchmarks demonstrate that our proposed framework achieves the state-of-the-art retrieval performances.
Simultaneous Compression and Quantization: A Joint Approach for Efficient Unsupervised Hashing
Jul 18, 2018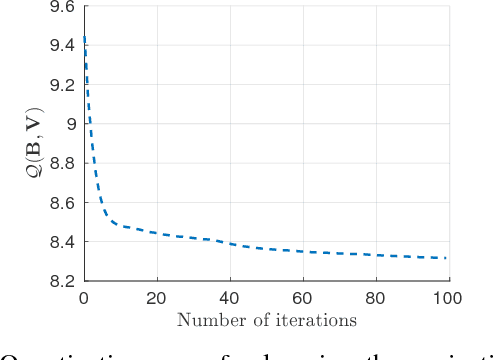
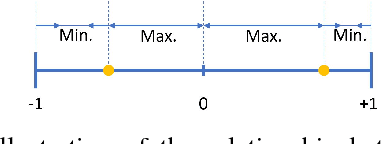
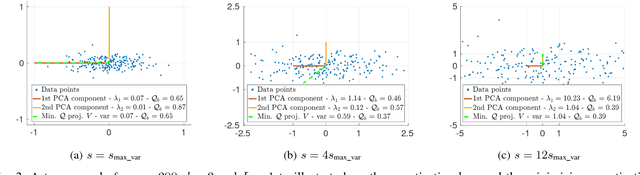
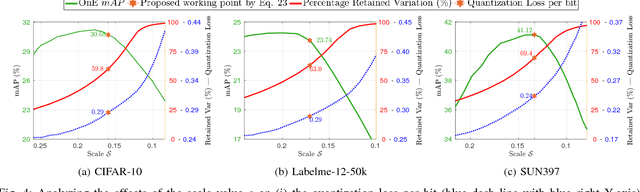
For unsupervised data-dependent hashing, the two most important requirements are to preserve similarity in the low-dimensional feature space and to minimize the binary quantization loss. A well-established hashing approach is Iterative Quantization (ITQ), which addresses these two requirements in separate steps. In this paper, we revisit the ITQ approach and propose novel formulations and algorithms to the problem. Specifically, we propose a novel approach, named Simultaneous Compression and Quantization (SCQ), to jointly learn to compress (reduce dimensionality) and binarize input data in a single formulation under strict orthogonal constraint. With this approach, we introduce a loss function and its relaxed version, termed Orthonormal Encoder (OnE) and Orthogonal Encoder (OgE) respectively, which involve challenging binary and orthogonal constraints. We propose to attack the optimization using novel algorithms based on recent advances in cyclic coordinate descent approach. Comprehensive experiments on unsupervised image retrieval demonstrate that our proposed methods consistently outperform other state-of-the-art hashing methods. Notably, our proposed methods outperform recent deep neural networks and GAN based hashing in accuracy, while being very computationally-efficient.