 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLUKE: A Linguistically-Driven and Task-Agnostic Framework for Robustness Evaluation
Paper and Code
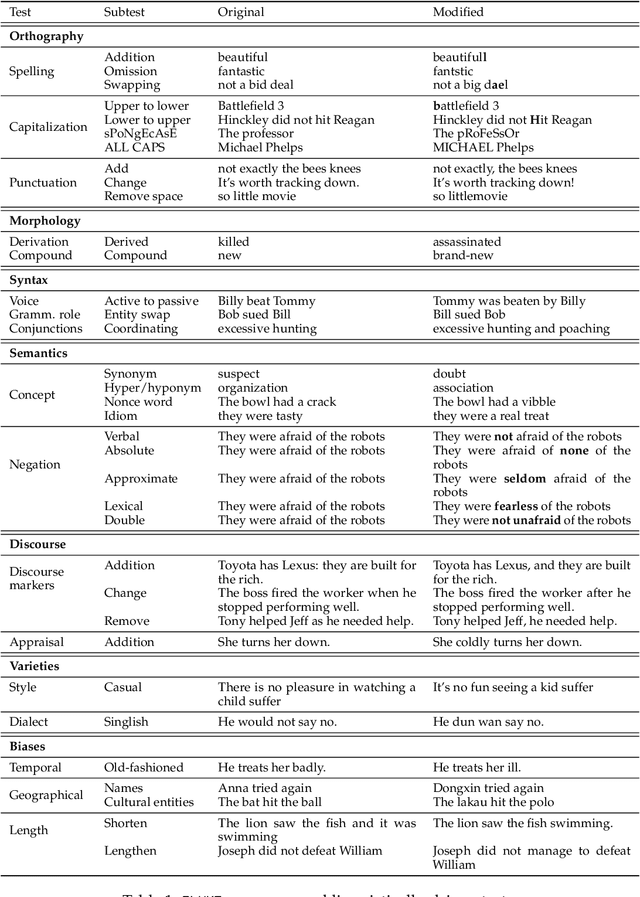
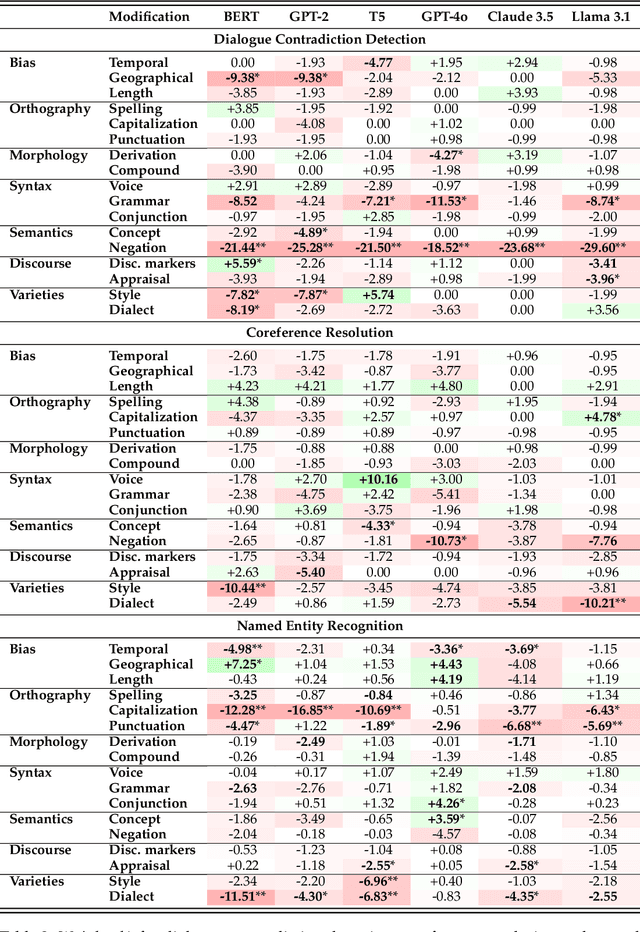

We present FLUKE (Framework for LingUistically-driven and tasK-agnostic robustness Evaluation), a task-agnostic framework for assessing model robustness through systematic minimal variations of test data. FLUKE introduces controlled variations across linguistic levels - from orthography to dialect and style varieties - and leverages large language models (LLMs) with human validation to generate modifications. We demonstrate FLUKE's utility by evaluating both fine-tuned models and LLMs across four diverse NLP tasks, and reveal that (1) the impact of linguistic variations is highly task-dependent, with some tests being critical for certain tasks but irrelevant for others; (2) while LLMs have better overall robustness compared to fine-tuned models, they still exhibit significant brittleness to certain linguistic variations; (3) all models show substantial vulnerability to negation modifications across most tasks. These findings highlight the importance of systematic robustness testing for understanding model behaviors.